法則・曲線・増加率#
import japanize_matplotlib
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import py4macro
import statsmodels.formula.api as sm
# 警告メッセージを非表示
import warnings
warnings.filterwarnings("ignore")
はじめに#
前章では経済のデータを人の「言動」に例えて説明したが,その比喩をもう少し考えてみよう。「言動」にはパターンがあり,その人の心を映し出しているとも考えられる。例えば,心の優しい人は電車やバスで重い荷物を持つ老人や小さな子を持つ女性に席を譲る回数が多いかも知れない。「あの子が好きだ!」とは決して口に出さない男の子でも,その思いを示唆するような発言や行動があるかも知れない。同じように,経済の「真のメカニズム」の反映としてデータには何らかのパターンが現れる。そのパターンを見つけることに経済学者は時間を割いてきたし,見出したパターンの中には経済を理解する上で非常に重要なヒント隠されている場合がある。ここでは代表的な次のデータのパターンを考える。
オークンの法則
フィリップス曲線
マネー・ストックの増加率とインフレーションの関係
マクロ経済学を勉強した人にとっては必ずと言っていいほど,知名度が高いデータのパターンではないだろうか。これらから「真のメカニズム」の動きが垣間見える事になる。
一方で「真のメカニズム」は不変ではないかも知れない。経済は人が営む活動であり,人が変われば「真のメカニズム」も影響を受けると考えられる。技術進歩(例えば,ビットコイン)や価値観の変化(例えば,「昭和の価値観」から「平成・令和の価値観」への移り変わり),政府・日銀の政策やコロナ禍などの大きなショックは人の行動の変化に影響すると考えるのが自然である。例えば,2020年代の「真のメカニズム」は1970年代のそれとは異なる可能性を拭えない。データを見る際は,そのような変化がないかを注意深く見ることも重要になるだろう。
オークンの法則#
説明#
この節で使用する記号:
\(Y_t\):GDP
\(\bar{Y}_t\):産出量の自然率水準(もしくは長期的GDP、潜在的GDP)
\(u_t\):失業率
\(\bar{u}_t\):自然失業率(もしくは長期的失業率)
オークンの法則は経験則として次の関係を表す。
左辺はGDPの自然率水準からの乖離率(自然率水準を何%上回るかを示す)であり,右辺は失業率の自然率からの乖離(自然失業率を何%ポイント上回るかを示す)である。即ち,GDPと失業率の長期的な値からの乖離には負の関係が存在することを意味している。労働者が生産投入といこと考えると,直感的にも受け入れ易い関係ではないだろうか。では失業率の乖離が1%ポイント上昇するとGDPの乖離率は何%減少するのだろうか。この問いについては,データを使いパラメータbを推定する必要がる。難しい点は、\(\bar{Y}_t\)と\(\bar{u}_t\)が観測されないため推定する必要があることである。この点を回避するために、オークンの法則を変数の変化で表す場合もあるが、ここでは上の式を考える。\(\bar{Y}_t\)と\(\bar{u}_t\)の推定には様々な洗練された手法があるが、ここでは簡便的にHodrick–Prescottフィルターを使って計算したトレンドを\(\bar{Y}\)と\(\bar{u}\)とし,トレンドからの乖離を上の式の左辺と右辺に使う。
以前使ったデータを使うが,次の節でインフレ率について扱うので3つの変数gdp,unemployment_rate,inflationを読み込むことにする。
df = py4macro.data('jpn-q').loc[:,['gdp','unemployment_rate','inflation']]
df.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 168 entries, 1980-03-31 to 2021-12-31
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 gdp 168 non-null float64
1 unemployment_rate 168 non-null float64
2 inflation 168 non-null float64
dtypes: float64(3)
memory usage: 5.2 KB
失業率の特徴#
ここでは失業率の特徴を考える。まず図示してみよう。
df['unemployment_rate'].plot()
pass
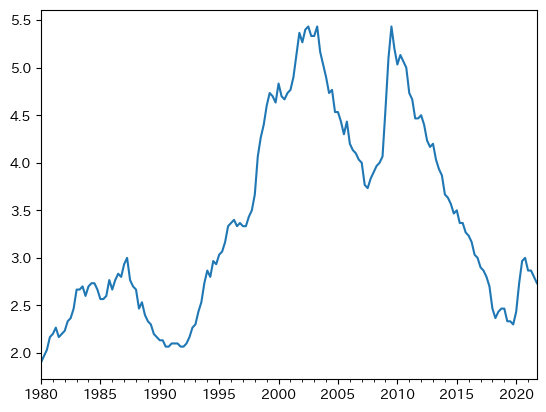
最初に気づく点は,前章で説明した持続性(変化が正(もしくは負)であれば正(もしくは負)の期間が続く傾向にある特徴)が高いとことである。実際,メソッド.autocorr()を使い自己相関係数を計算すると非常に高い値が返される。
df['unemployment_rate'].autocorr()
0.9919258402544141
次に,GDPのトレンドからの乖離(%)と失業率のトレンドからの乖離(%ポイント)を比べてみる。まず失業に関する変数を作成するが,対数を取らずに差分をトレンドからの乖離とする。
df['u_rate_trend'] = py4macro.trend(df['unemployment_rate'])
df['u_rate_cycle'] = df['unemployment_rate'] - df['u_rate_trend']
ここで作成した変数は次の変数を表している。
unemployment_rate_cycle:\(u_t-\bar{u}_t\)\(\bar{u}_t\):トレンド失業率
次にGDPのトレンドからの乖離率を計算しよう。
gdp_cycle:\(\dfrac{Y_t}{\bar{Y}_t}-1 \approx \log\left(\dfrac{Y_t}{\bar{Y}_t}\right) =\log(Y_t) - \log(\bar{Y}_t) \)\(\bar{Y}_t\):トレンドGDP
df['gdp_cycle'] = 100*(
np.log(df['gdp']) - py4macro.trend( np.log(df['gdp']) )
)
GDPの乖離と重ねて動きを確認してみる。
df.loc[:,['u_rate_cycle','gdp_cycle']].plot(secondary_y='u_rate_cycle')
pass
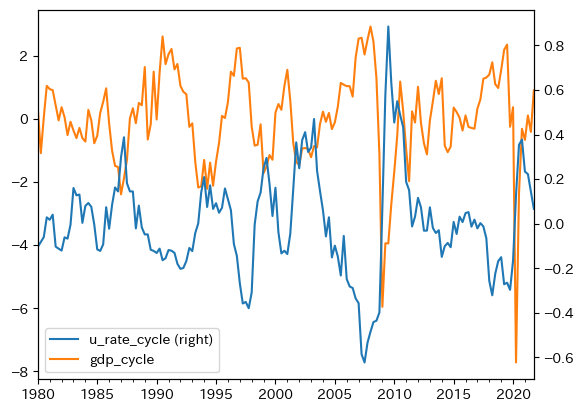
概ね逆方向に上下していることがわかる。またバブル景気の崩壊後やリーマン・ショック後に,2変数は逆方向に大きく動いていることも確認できる。相関度を確かめるために,dfのメソッドcorr()を使い相関係数を計算しよう。
df.loc[:,['u_rate_cycle','gdp_cycle']].corr()
| u_rate_cycle | gdp_cycle | |
|---|---|---|
| u_rate_cycle | 1.000000 | -0.627466 |
| gdp_cycle | -0.627466 | 1.000000 |
右上と左下の値が2変数の相関係数であり,値は約-0.63は強い逆相関を意味する。
また上の図から持続性が高いことが伺える。自己相関係数を計算してみよう。
df['gdp_cycle'].autocorr()
0.680888809545929
df['u_rate_cycle'].autocorr()
0.876025030648204
両変数ともトレンドからの乖離は持続性が非常に高いと言える。
回帰分析#
では実際に式(107)のスロープ変数\(b\)を推定してみよう。
formula = 'gdp_cycle ~ u_rate_cycle' # 1
model = sm.ols(formula, data=df) # 2
result = model.fit() # 3
コードの説明
回帰式を文字列で作成し変数
formulaに割り当てる。smの関数.olsを使い最小二乗法の準備をし,変数modelに割り当てる。引数は(1)の
formulaとdataに使用するDataFrame(ここではdf_okun)を指定する。
modelのメソッド.fit()を使い自動計算し,その結果をresultに割り当てる。
resultのメソッド.summary()を使い結果を表として表示しよう。
print(result.summary())
OLS Regression Results
==============================================================================
Dep. Variable: gdp_cycle R-squared: 0.394
Model: OLS Adj. R-squared: 0.390
Method: Least Squares F-statistic: 107.8
Date: Sun, 24 Mar 2024 Prob (F-statistic): 8.95e-20
Time: 03:43:57 Log-Likelihood: -261.32
No. Observations: 168 AIC: 526.6
Df Residuals: 166 BIC: 532.9
Df Model: 1
Covariance Type: nonrobust
================================================================================
coef std err t P>|t| [0.025 0.975]
--------------------------------------------------------------------------------
Intercept 3.854e-11 0.089 4.33e-10 1.000 -0.176 0.176
u_rate_cycle -4.0106 0.386 -10.383 0.000 -4.773 -3.248
==============================================================================
Omnibus: 104.252 Durbin-Watson: 1.095
Prob(Omnibus): 0.000 Jarque-Bera (JB): 989.767
Skew: -2.099 Prob(JB): 1.19e-215
Kurtosis: 14.125 Cond. No. 4.34
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
表の中段から次のことがわかる。
定数項の推定値は非常に小さい。即ち、失業率の乖離がゼロある場合、GDPの乖離率もぜろになることを示しており、定数項がない式(107)と整合的であることわかる。
パラメータ
bの推定値は負の値となっていおり、失業率が自然失業率を上回るとGDP乖離率は減少することが確認できる。
<コメント>
Durbin-Watson比は誤差項に正の自己相関が疑われことを示しており,\(t\)検定の解釈には注意が必要となるが,この点ついての議論は割愛する。
回帰分析の結果を踏まえると,失業率の乖離がx%ポイントの場合にGDPのトレンドからの乖離率(%)を計算する関数は次のようになる。
def growth_deviation(x):
g = result.params[0]+result.params[1]*x
print(f'失業率の乖離が{x:.1f}%ポイントの場合のGDPのトレンドからの乖離率は約{g:.2f}です。')
xが1%ポイントの場合を考えよう。
growth_deviation(1)
失業率の乖離が1.0%ポイントの場合のGDPのトレンドからの乖離率は約-4.01です。
この値を解釈してみよう。失業率が1%ポイント乖離するとしよう。GDPの乖離率は約-4.1%になることを示しているが、この値は非常に大きい。例えば、上のプロットで示したGDPのトレンドからの乖離率を考えてみよう。バブル崩壊時の乖離率は約2.6%,リーマン・ショック時では約6%,コロナ禍では7.7%である。これは日本の雇用制度を反映していると考えられる。またトレンドを計算する際に使ったHodrick–Prescottフィルターの影響もあるだろう。
次に、標本の散布図に回帰直線を重ねて表示してみる。まずresultの属性.fittedvaluesを使い非説明変数の予測値を抽出することができるので、dfにfittedのラベルを使って新たな列として追加する。
df['fitted_okun'] = result.fittedvalues
図を重ねて表示する。
ax_ = df.plot(x='u_rate_cycle',
y='gdp_cycle',
kind='scatter')
df.plot(x='u_rate_cycle',
y='fitted_okun',
kind='line',
color='red',
ax=ax_)
pass
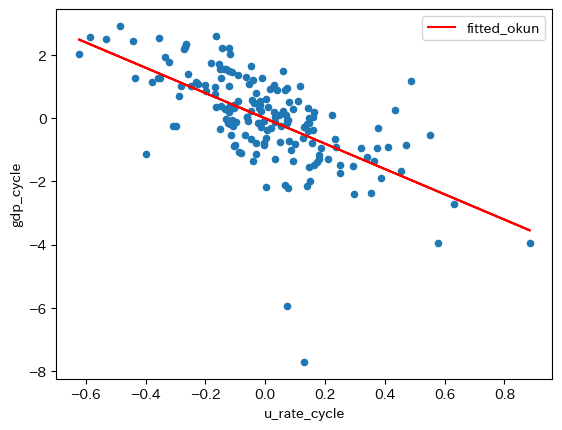
Note
係数の推定値は、resultの属性paramsでアクセスできることを説明したが、この値を使い次のコードでgdp_cycleの予測値を計算することも可能である。
ahat = result.params[0]
bhat = result.params[1]
df['fitted'] = ahat + bhat * df['u_rate_cycle']
プロットの下中央にある2点がリーマン・ショックとコロナ禍によるGDPの乖離率である。この2点に関連して次のことが言える。GDPの乖離率の観点から考えると,2つのショックは「外れ値」的な存在であり,大きなショックだったことがうかがえる。一方,2つのショックに伴う失業率の乖離は大きくなく,0に近い値となっている。これはGDPに対するショックが,失業率に影響を及ぼすには時間的なラグが発生することの反映であろう。その結果,回帰直線の傾きに対する影響は限定的だと言える(例えば,失業率の乖離が0.8近傍であれば,傾きは絶対値でより大きな値となっていただろう)。従って,傾きが約-4.1という結果は,数少ない大きなショックによって大きく影響を受けたものではないとして理解して良いだろう。
フィリップス曲線#
説明#
マクロ経済学を学んだ人にとって最も馴染み深い関係の一つがフィリップス曲線(PC曲線)ではないだろうか。失業率とインフレ率の関係を示すが,典型的なPC曲線は次式で与えられる。
\(\pi_t\):インフレ率
\(\text{E}\pi_t\):期待インフレ率
\(u_t\):失業率
\(\bar{u}\):自然失業率(長期的な失業率)
\(v\):供給サイドのショック
通常,式(108)では分析の簡単化のために自然失業率\(\bar{u}\)はトレンドであり一定と仮定され,その周辺を経済が変動すると考える。
失業率の特徴については「失業率の特徴」の節で議論したので,以下では式(108)の左辺にあるインフレ率について考えることにする。
インフレ率の特徴#
上で使用したdfにinflationが含まれているので図示してみよう。
df.loc[:,['inflation']].plot()
pass
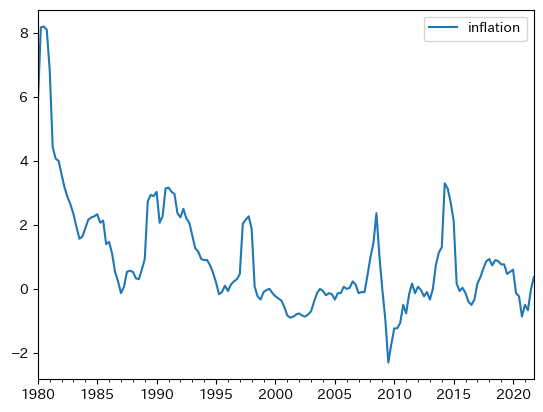
上下しているのが,過去約35年間は非常に安定している。図から持続性が強いことがわかるが,実際に計算してみよう。
df.loc[:,'inflation'].autocorr()
0.9486542725385126
0.949は非常に高い持続性を意味しており,インフレが増加すると持続傾向にあることがわかる。次にトレンドからの乖離(%ポイント)を計算し,GDPのトレンドからの乖離と重ねて図示してみよう。
df['inflation_trend'] = py4macro.trend(df['inflation'])
df['inflation_cycle'] = df['inflation'] - df['inflation_trend']
df[['gdp_cycle','inflation_cycle']].plot()
pass
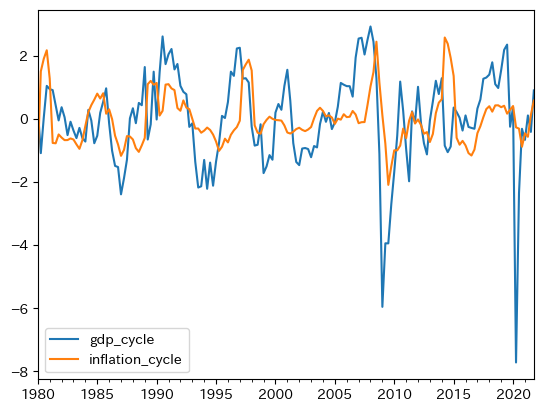
同じ方向に動く傾向が確認できる。相関係数を計算してみる。
df[['inflation_cycle','gdp_cycle']].corr()
| inflation_cycle | gdp_cycle | |
|---|---|---|
| inflation_cycle | 1.000000 | 0.308714 |
| gdp_cycle | 0.308714 | 1.000000 |
絶対値でみると失業程ではないが,正の相関性があることが確認できる。この結果から,インフレ率と失業率の負の相関が予測される。次に、自己相関係数を確認する。
df['inflation_cycle'].autocorr()
0.7771024330909484
トレンドからの乖離も強い持続性があることを示している。
フラット化するフィリップス曲線#
まずインフレ率と失業率の散布図をプロットしよう。
df.plot(x='unemployment_rate', y='inflation', kind='scatter')
pass
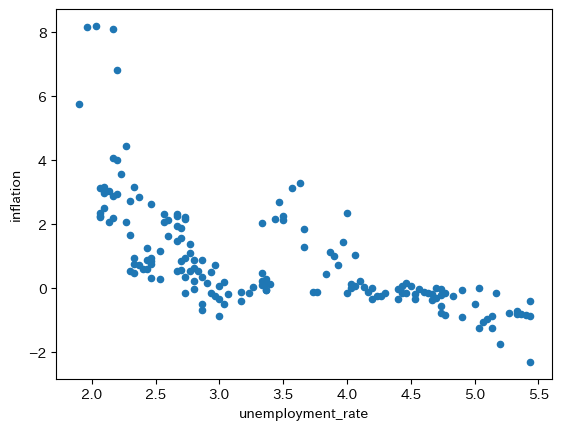
右下がりであり式(108)と整合的にみえる。上の散布図に1つの曲線を描いてそれをPC曲線と呼ぶこともできるだろう。一方で,次の問題を考えてみよう。
過去40年間,フィリプス曲線は変化した可能性はないのか。即ち,真のメカニズムが変わりながら生成されたデータが表示されているのではないか,という問題である。
式(108)には期待インフレ率がり,また供給サイドのショックもあり得る(例えば,コロナ禍)。それらをどう考えるかという問題がある。
第二の問題を扱うことはこのサイトの範囲を超えるので,ここでは扱わず議論を進めることにする。以下では第一の問題を考察してみよう。
景気循環のマクロ経済学での短期は何ヶ月または何年以下で,長期は何年以上なのだろうか。実は,曖昧で学者・学派によって見解が別れる事になる。ここでは10年間は長期に入ると考えることにする(多くの経済学者は同意するだろう)。この考えに基づき,10年毎のデータを検討しPC曲線に変化があるかどうかを確かめることにする。
まず10年毎のデータを使うために,次のコードを使い新たな列decadeをdfに追加しよう。
df['decade'] = df.index.year // 10 * 10
df['decade']
1980-03-31 1980
1980-06-30 1980
1980-09-30 1980
1980-12-31 1980
1981-03-31 1980
...
2020-12-31 2020
2021-03-31 2020
2021-06-30 2020
2021-09-30 2020
2021-12-31 2020
Name: decade, Length: 168, dtype: int32
コードの説明
df.indexは行ラベルを抽出するが,その属性.yearは行ラベルから年だけを抽出する。年を切り捨て除算演算子//を使い次の様に変換する
1980 → 198
1981 → 198
1982 → 198
...
更に,それぞれの数字を*10により10倍することにより,次のような変換となる。
1980 → 1980
1981 → 1980
1982 → 1980
...
それを新たな列decadeに割り当てている。
新たな列とforループを使い,式(108)の係数\(a\)と\(b\)を推定してみよう。大きな差が無ければ,フィリップス曲線は概ね一定だと考えることができる。
decade_list = list( range(1980, 2011, 10) ) #1
a_list = [] #2
b_list = [] #3
for d in decade_list: #4
cond = ( df['decade'] == d ) #5
res = sm.ols('inflation ~ unemployment_rate', #6
data=df.loc[cond,:]).fit() #7
df[f'{d}年代データ'] = res.fittedvalues #8
a_list.append(res.params[0]) #9
b_list.append(res.params[1]) #10
コードの説明
#1:1980,1990,2000,2010の4つの要素からなるリストをdecade_listに割り当てる。#2:定数項の推定値を格納する空のリスト。#3:スロープ係数の推定値を格納する空のリスト。#4:decade_listを使いforループを開始。#5:列decadeがdと等しい行のみがTrueになる条件をcondに割り当てる。#6:OLS推定の結果をresに割り当てる。#7:OLS推定に使用するDataFrameを指定するが,.loc[cond,:]を使い10年間だけのデータを抽出する。#8:res.fittedvaluesはOLSの予測値だが,新たな列としてdfに追加している。列ラベルとして
1980年代データのように設定しており,下でプロットする際の凡例に使うためである。f-stringを使うためにfを置き{}の中に文字列を代入している。
#9:res.paramsはOLS推定値のSeriesを返すので,その0番目の要素(定数項)をa_listに追加している。#10:res.paramsはOLS推定値のSeriesを返すので,その1番目の要素(スロープ係数)をb_listに追加している。
結果をprint関数を使い表示する。
print('--- 定数項の推定値 -------------\n')
for d, a in zip(decade_list, a_list):
print(f'{d}年代:{a:>5.2f}')
print('\n--- スロープ係数の推定値 --------\n')
for d, b in zip(decade_list, b_list):
print(f'{d}年代:{b:.2f}')
--- 定数項の推定値 -------------
1980年代:18.58
1990年代: 4.37
2000年代: 4.58
2010年代: 2.11
--- スロープ係数の推定値 --------
1980年代:-6.43
1990年代:-1.04
2000年代:-1.03
2010年代:-0.48
定数項の推定値もスロープ係数の推定値も変化が大きく,特に1980年代の値とそれ以降の値の差が顕著である。傾きが緩やかになっているので,PC曲線のフラット化(需給ギャップに対してのインフレ率の弾性値の低下)と呼ばれている。研究では,日本だけではなく欧米でもPC曲線のフラット化が指摘されている。プロットして確認してみよう。
color_list = ['orange','black', 'blue', 'red'] # 1
fig, ax = plt.subplots()
for d, c in zip(decade_list, color_list):
cond = ( df['decade'] == d )
ax.scatter('unemployment_rate',
'inflation',
data=df.loc[cond,:],
edgecolor=c, # 2
facecolor='white', # 3
label='')
ax.plot('unemployment_rate',
f'{d}年代データ',
data=df.loc[cond,:].sort_values(f'{d}年代データ'),
color=c, # 4
linewidth=2 # 5
)
ax.set_title('フラット化するフィリップス曲線', size=20)
ax.set_xlabel('失業率', fontsize=15)
ax.set_ylabel('インフレ率', fontsize=15)
ax.legend()
pass
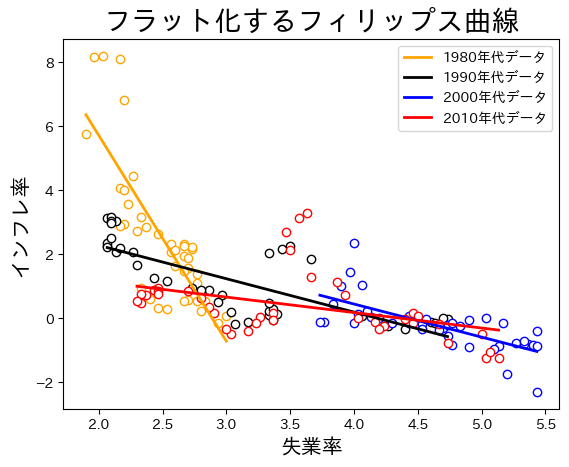
コードの説明
色のリスト
['orange','k', 'b', 'r']としてもOK。
edgecolorは散布図の円形マーカーの縁の色を指定する引数。facecolorは散布図の円形マーカーの内側の色を指定する引数。colorは直線の色を指定する引数。linewidthは直線幅を指定する引数。
上の図をDataFrameのメソッド.plot()を使い図示する方法
ax = df.iloc[0:0,:].plot.scatter('unemployment_rate', 'inflation', label='')
for d, c in zip(decade_list, color_list):
cond = ( df['decade'] == d )
ax.scatter('unemployment_rate',
'inflation',
data=df.loc[cond,:],
edgecolor=c,
facecolor='white',
label='')
ax.plot('unemployment_rate',
f'{d}年代データ',
data=df.loc[cond,:].sort_values(f'{d}年代データ'),
color=c,
linewidth=2
)
ax.set_title('フラット化するフィリップス曲線', size=20)
ax.set_xlabel('失業率', fontsize=15)
ax.set_ylabel('インフレ率', fontsize=15)
ax.legend()
時間が経つにつれてPC曲線は右に横滑りしていることが確認できる。失業率に対してのインフレ率の反応が鈍くなっていることを示しているが,フラット化の原因は定かではなく,活発な研究がおこなわれている。原因として次の点が指摘されている。
中央銀行の政策決定の透明化や政策のアナウンスメント,フォーワード・ガイダンス(将来の政策についてのガイダンス)などにより,中央銀行の物価安定(インフレ安定)重視のスタンスが民間に十分に浸透したと考えられる。失業が変化しても,インフレ率のの安定化を図る中央銀行の政策スタンスが民間の期待に織り込まれ,インフレ率の変化は小さくなったと思われる。この解釈が正しければ,日銀は素晴らしい仕事をしたということである。
グローバル化や規制改革により競争環境が変化し(例えば,需要曲線の変化や寡占化),その結果,企業の価格設定行動がも変化したためである。
1980年代のPC曲線の傾きは,データ上では大きく見えるが,真のPC曲線はフラットだったという解釈である。上の散布図は観測されたデータを単純にプロットしただけであり,データだけを見てもその裏にあるデータ生成メカニズムは分からない。更には,1980年代にインフレ率が急に減少しているが,インフレ率の下落はPC曲線の下方シフトとして発生したと考えられ,それがデータ上ではPC曲線の急な傾きとして観測されているに過ぎない。
PC曲線は直線ではなく非線形であり,失業率が高くなると傾きが緩やかになる。直感的には次のように理解できる。企業にとって価格改定にはコストがかかる。従って,インフレ率が高い場合は企業は価格改定をしないと損をするのでより頻繁に価格を上昇させる。一方,インフレ率が低いと,価格改定しない場合の損失は大きくないので,価格の変化は頻繁に起こらなくなる。
解釈1〜3によると,「真のメカニズム」が変化したと考えることができる。一方,解釈4では「真のメカニズム」は変わらないという事になる。どの解釈がより妥当なのだろうか。非常に難しい問題であり,その解明が経済学の進歩につながる事は言うまでもない。(データと整合的な解釈が複数存在することは経済学でよくあることである。)
経済学に関するジョークに,真っ暗な部屋で黒猫を探す経済学者が登場するものがある。それを模して黒猫がPC曲線だとしよう。最初に黒猫の小さな可愛い鳴き声が聞こえ,5分後にまた同じ方向から鳴き声が聞こえたとする。それだけで,黒猫がいた場所が少しでも変わったかどうかを判断するとした場合,様々な解釈が成立する。「右に10cm動いているようだ。」「いや左に5cm。」「1m程右に動いて元の位置に戻っている。」「そもそも猫は2匹いて,最初の黒猫は他の場所に移り,もう一匹の三毛猫が鳴いたのではないか。」「2回目の鳴き声は幻聴だ。」非常に難しそうである。
黒猫のジョーク
A mathematician, a theoretical economist and an econometrician are asked to find a black cat (who doesn’t really exist) in a closed room with the lights off:
The mathematician (数学者) gets crazy trying to find a black cat that doesn’t exist inside the darkened room and ends up in a psychiatric hospital.
The theoretical economist (理論経済学者) is unable to catch the black cat that doesn’t exist inside the darkened room, but exits the room proudly proclaiming that he can construct a model to describe all his movements with extreme accuracy.
The econometrician (計量経済学者,特に経済データを用いて実証研究をする学者) walks securely into the darkened room, spend one hour looking for the black cat that doesn’t exits and shouts from inside the room that he has it catched by the neck.”
インフレ率とマネーストックの増加率#
説明#
貨幣数量説は次式で表される。
\(P_t\):一般物価水準
ある期間(1年間)で取引された財の集計物価水準
\(Y_t\):実質支出(GDP)
ある期間(1年間)で取引された財に対する実質支出額
\(M_t\):マネーストック
ある期間(1年間)平均で流通した貨幣量
\(V_t\):貨幣の流通速度
ある期間(1年間)平均で貨幣1単位が何回使用されたかを示す
式(109)に対数を取り時間微分すると次式となる。
ここで
\(\pi_t=\dfrac{\dot{P}_t}{P_t}\):インフレ率
\(g_t=\dfrac{\dot{Y_t}}{Y_t}\):実質GDPの成長率
\(m_t\equiv\dfrac{\dot{M}_t}{M_t}\):マネーストックの増加率
\(v_t=\dfrac{\dot{V}_t}{V_t}\):貨幣の流通速度の変化率
式(109)は恒等式であり,式(110)も常に成り立つ関係である。ここで長期均衡を考えてみよう。GDPは供給サイドで決定され,成長率は一定(\(g_t=\overline{g}\))としよう(ソロー・モデルを考えてみよう)。更に貨幣の流通速度は一定とする。この仮定のもと式(110)は次式としてまとめることができる。
この式によると,長期的なインフレ率はマネーストックの増加率によって決定される。この節では,式(111)の予測がデータと整合的かどうかを議論する。次の2つのデータ・セットを使いこの問題を考察する。
日本の時系列データ
世界経済のパネル・データ
手法としては散布図と回帰直線の傾きに基づいて正の相関があるかを考える。
日本の時系列データ#
説明#
py4macroにはjpn-moneyというデータ・セットが含まれており,その内容は次のコードで確認できる。
py4macro.data('jpn-money', description=1)
| `cpi`: 消費者物価指数
| * 2015年の値を`100`
| * 季節調整済み
| `money`: マネーストック(M1)
| * 2015年の値を`100`
| * 季節調整済み
|
| * 月次データ
| * 1955年1月〜2021年12月
| * 行ラベル:毎月の最終日
|
| <出典>
| OECD Main Economic Indicators
1955年1月から2021年4月までの月次データであり,消費者物価指数とマネーストックの2つの変数が含まれている。マネーストックにはM1が使われており,現金通貨と要求払預金(預入期間の設定がなく自由に出し入れができる預金のことであり,普通預金が典型的な例)で構成される。詳しくはマネーストック統計の解説を参考にしてほしい。M1を使う大きな理由は長い時系列データが存在することであり,長期的な関係である式(111)を考えるには適しているためである。
一方で長い時系列データであれば長期的な関係を捉えることができるという訳ではない。ここでの長期的な関係とは,ある作用が発生した後,その効果が現れるのに時間が掛かるという意味である。例えば,今日マネーストックの増加率が上昇したとしても,明日すぐにインフレ率の上昇につながるという訳ではなく,その効果が浸透しデータの数字に現れるまで数ヶ月掛かる事になる。この点を示すために次のステップで進めることにする。
月次データを変換して次のデータを作成する。
四半期データ
年次データ
1期を3年とするデータ(ここでは「3年次データ」と呼ぶ)
月次データを含む4つのデータ・セットを使い,2変数の散布図と回帰分析をおこなう。
resample()#
まず四半期データへの変換を考えよう。1四半期には3ヶ月の値があり,その平均を1四半期の値とする。同様に,年次データおよび3年次データに変換する場合は,12ヶ月間もしくは36ヶ月間の値を使い平均を計算することになる。このような計算は「連続的な時系列のグループ計算」として捉えることができる。グループ計算のメソッドにgroupbyがあるが,カテゴリー変数に基づいてグループ分けするので,この問題に使うことはできない。その代わりに,時系列用グループ計算メソッドとしてresampleが用意されている。ここではresampleの使い方を紹介するが,異なる方法として移動平均を使うことも可能であり,興味がある人はこちらを参照してみよう。
Note
resampleはグループ計算だけではなく,その「逆の計算」もすることができるがここでは触れない。以下では,「時系列グループ計算用」としてのみ考える。
resampleの使い方を説明するために,次のDataFrame(変数名はdf_ex)を考えよう。
Show code cell source
date_index = pd.date_range('2020-01-31','2021-12-31', freq='M')
df_ex = pd.DataFrame({'X':list(range(10,120+1,10))*2,
'Y':np.random.normal(5,1,size=12*2)},index=date_index)
df_ex
| X | Y | |
|---|---|---|
| 2020-01-31 | 10 | 4.063971 |
| 2020-02-29 | 20 | 6.742936 |
| 2020-03-31 | 30 | 6.017196 |
| 2020-04-30 | 40 | 6.059804 |
| 2020-05-31 | 50 | 5.479802 |
| 2020-06-30 | 60 | 4.082977 |
| 2020-07-31 | 70 | 5.438169 |
| 2020-08-31 | 80 | 4.595037 |
| 2020-09-30 | 90 | 4.588115 |
| 2020-10-31 | 100 | 6.758865 |
| 2020-11-30 | 110 | 4.854873 |
| 2020-12-31 | 120 | 5.033107 |
| 2021-01-31 | 10 | 7.114900 |
| 2021-02-28 | 20 | 6.417685 |
| 2021-03-31 | 30 | 4.646108 |
| 2021-04-30 | 40 | 4.155000 |
| 2021-05-31 | 50 | 4.485911 |
| 2021-06-30 | 60 | 5.644347 |
| 2021-07-31 | 70 | 5.089469 |
| 2021-08-31 | 80 | 2.348687 |
| 2021-09-30 | 90 | 4.133709 |
| 2021-10-31 | 100 | 4.836414 |
| 2021-11-30 | 110 | 5.864602 |
| 2021-12-31 | 120 | 5.652975 |
df_exには時系列用の行ラベルがが使われており,毎月の最後の日がラベルとなっている。列Xには10から120までの整数が昇順に並んでおり,Yにはランダムは値が並んでいる。
2つのステップに分けて説明する。
ステップ1:グループ化の期間を指定する
最初のステップでは,グループ化する期間を引数として.resample()を実行する。指定する期間は次のように文字列として指定する。
AもしくはY:1年を基準としてグループ化Q:四半期を基準としてグループ化M:1ヶ月を基準としてグループ化3ヶ月であれば
3M,1年であれば12Mとできるが,QとA(Y)と挙動が少し異なるので注意が必要である。
df_exを四半期でグループ化するには次のようになる。
df_ex.resample('Q')
<pandas.core.resample.DatetimeIndexResampler object at 0x134e75d20>
このコードはDataFrameを返すわけではない。返すのは時系列グループ計算用のオブジェクトであり,それを使ってグループ計算をおこなう事になる。
ステップ2:計算内容を指定する。
どのような計算をしたいかを指定する。ここではメソッド.mean()を使って指定した期間内の平均を計算してみよう。
df_ex.resample('Q').mean()
| X | Y | |
|---|---|---|
| 2020-03-31 | 20.0 | 5.608034 |
| 2020-06-30 | 50.0 | 5.207528 |
| 2020-09-30 | 80.0 | 4.873774 |
| 2020-12-31 | 110.0 | 5.548948 |
| 2021-03-31 | 20.0 | 6.059564 |
| 2021-06-30 | 50.0 | 4.761753 |
| 2021-09-30 | 80.0 | 3.857288 |
| 2021-12-31 | 110.0 | 5.451330 |
行ラベルには四半期の最後の日が使われている。列Xに並んでいる数字から,毎四半期の期間内平均であることが確認できる。
次のコードは年平均を計算している。
df_ex.resample('A').mean()
| X | Y | |
|---|---|---|
| 2020-12-31 | 65.0 | 5.309571 |
| 2021-12-31 | 65.0 | 5.032484 |
平均以外にも様々な計算ができるようになっている。py4macroモジュールに含まれるsee()関数を使って属性を調べてみよう。
py4macro.see(df_ex.resample('A'))
.X .Y .agg .aggregate
.apply .asfreq .ax .bfill
.binner .count .ffill .fillna
.first .get_group .groups .include_groups
.indices .interpolate .kind .last
.max .mean .median .min
.ndim .nearest .ngroups .nunique
.ohlc .pipe .prod .quantile
.sem .size .std .sum
.transform .var
主なメソッドとして次を挙げることができる(これらの計算で欠損値は無視される)。
mean():平均median():中央値max():最大値min():最小値std():標準偏差var():分散sum():合計first():最初の値last():最後の値count():要素数
このリストにない計算をしたい場合は,上のリストにある.agg()(aggregate()も同じ)を使いNumPyや自作の関数を指定することができる。例えば,変動係数(coefficient of variation)を計算したいとしよう。
def cv(x):
return x.std() / x.mean()
この関数のxは,時系列グループ計算で取り出されたSeriesもしくはDataFrameと考えれば良いだろう。使い方は簡単で,.agg()の引数としてcvを指定するだけである。
df_ex.resample('A').agg(cv)
| X | Y | |
|---|---|---|
| 2020-12-31 | 0.5547 | 0.176261 |
| 2021-12-31 | 0.5547 | 0.246863 |
Warning
.agg()の引数はcvでありcv(x)ではない。関数名だけを.agg()に渡し,.agg()が渡された関数を実行するというイメージである。cv(x)を引数に使うと,cv(x)を実行した結果を.agg()に渡すことになりエラーとなってしまう。
データの作成#
では実際にjpn-moneyのデータを使いデータを整形しよう。まず月次データを読み込みmonthに割り当てる。
month = py4macro.data('jpn-money')
month.tail()
| cpi | money | |
|---|---|---|
| 2021-08-31 | 101.618532 | 158.215194 |
| 2021-09-30 | 101.729035 | 158.977241 |
| 2021-10-31 | 101.401104 | 160.060574 |
| 2021-11-30 | 101.956670 | 161.054055 |
| 2021-12-31 | 102.045185 | 161.869633 |
いつもの通り.info()を使ってデータの内容を確認しよう。
month.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 804 entries, 1955-01-31 to 2021-12-31
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 cpi 804 non-null float64
1 money 804 non-null float64
dtypes: float64(2)
memory usage: 18.8 KB
行ラベルがDatetimeIndexとなっており,時系列データ用に設定されていることが分かる。
四半期データに変換して変数quarterに割り当てることにする。
quarter = month.resample('Q').mean()
これで3ヶ月の値の平均からなる四半期データを作成した事になる。確かめてみよう。
quarter.head()
| cpi | money | |
|---|---|---|
| 1955-03-31 | 17.236707 | 0.347656 |
| 1955-06-30 | 16.874004 | 0.357257 |
| 1955-09-30 | 17.035517 | 0.384201 |
| 1955-12-31 | 16.875107 | 0.400080 |
| 1956-03-31 | 17.108284 | 0.394544 |
四半期の最後の日が行ラベルになっていることが分かる。同様に,年次データ作成しよう。
annual = month.resample('A').mean()
annual.head()
| cpi | money | |
|---|---|---|
| 1955-12-31 | 17.005334 | 0.372299 |
| 1956-12-31 | 17.072603 | 0.424722 |
| 1957-12-31 | 17.601583 | 0.478435 |
| 1958-12-31 | 17.517496 | 0.505580 |
| 1959-12-31 | 17.707073 | 0.588486 |
1年の最後の日が行ラベルになっている。次に3年次データを作成しよう。
annual3 = month.resample('36M',closed='left',label='right').mean() # 1
annual3.index = annual3.index - pd.tseries.frequencies.to_offset('M') # 2
annual3.head()
| cpi | money | |
|---|---|---|
| 1957-12-31 | 17.226506 | 0.425152 |
| 1960-12-31 | 17.854861 | 0.599932 |
| 1963-12-31 | 20.666763 | 1.039100 |
| 1966-12-31 | 24.291933 | 1.641735 |
| 1969-12-31 | 28.080477 | 2.570458 |
このコードはquarterとannualのコード少し異なる。コードの具体的な説明は割愛するが,何をしているかを簡単に説明する。1行目の引数36Mは36ヶ月を意味している。3Aとすることもできるが,変わった挙動をするので月数(つきすう)を使っている。また引数closed='left'とlabel='right'が追加されているが,quarterとannualと同様の計算・表示になるようにするためである。2行目は行ラベルが3年次の最後の日になるように設定している。
次にインフレ率とマネーストックの増加率の変化を計算し,新たな列としてそれぞれのDataFrameに追加しよう。増加率の公式に従ってコードを書いても良いが,DataFrameのメソッド.pct_change()を紹介する。これは名前が示すように(percent changeの略)列の変化率を計算するメソッドである。ここで注意が必要な点は,.pct_change()はデフォルトで前期比の増加率を返す。例えば,次のコードはcpiの前月と比べた増加率を計算している。
month.loc[:,'cpi'].pct_change()
同年同期比の増加率を計算したい場合は,12ヶ月前の値と比べたいので引数に12を指定すれば良い。例として,quarterでcpiの同年同期比のインフレ率を計算する場合は次のようになる。
month.loc[:,'cpi'].pct_change(4)
以下では,デフォルトで.pct_change()を使い計算する。
df_list = [month, quarter, annual, annual3]
for df in df_list:
df['inflation'] = df.loc[:,'cpi'].pct_change()
df['money_growth'] = df.loc[:,'money'].pct_change()
monthを確認してみよう。
month.head()
| cpi | money | inflation | money_growth | |
|---|---|---|---|---|
| 1955-01-31 | 17.219573 | 0.347029 | NaN | NaN |
| 1955-02-28 | 17.351247 | 0.350938 | 0.007647 | 0.011264 |
| 1955-03-31 | 17.139301 | 0.345003 | -0.012215 | -0.016910 |
| 1955-04-30 | 16.964259 | 0.353125 | -0.010213 | 0.023541 |
| 1955-05-31 | 16.720857 | 0.354401 | -0.014348 | 0.003613 |
行1955-01-01のinflationとmoney_growthの値はNaNとなっている。これは前期の値がないためである。
散布図とトレンド線#
forループを使ってOLSの計算とプロットを同時におこなおう。
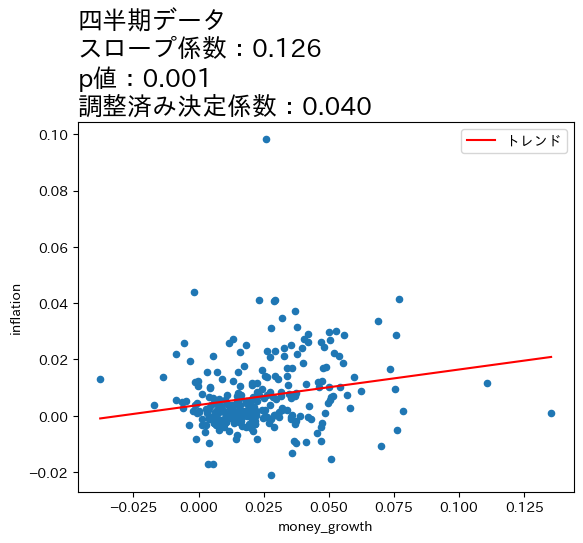
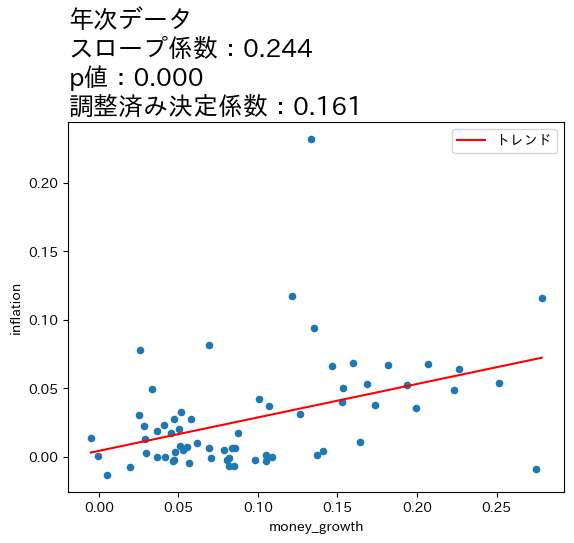
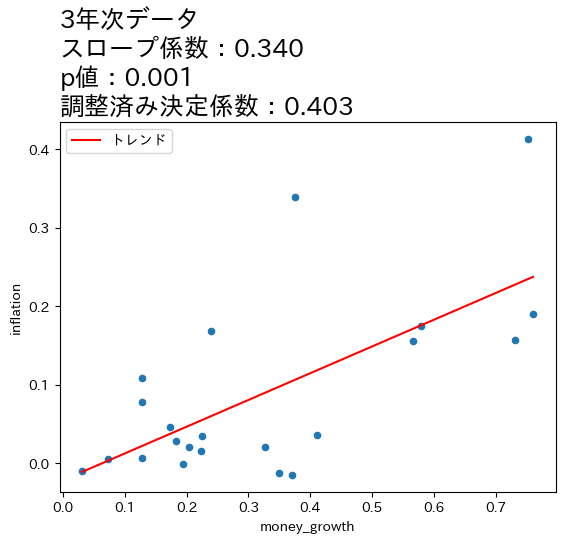
title_list = ['月次データ','四半期データ','年次データ','3年次データ'] # 1
for df, t in zip(df_list,title_list):
res = sm.ols('inflation ~ money_growth', data=df).fit() # 2
df['トレンド'] = res.fittedvalues # 3
ax_ = df.plot('money_growth', 'inflation', kind='scatter') # 4
df.sort_values('トレンド').plot('money_growth','トレンド', # 5
color='r', ax=ax_) # 6
ax_.set_title(f'{t}\n' # 7
f'スロープ係数:{res.params[1]:.3f}\n' # 8
f'p値:{res.pvalues[1]:.3f}\n' # 9
f'調整済み決定係数:{res.rsquared_adj:.3f}', # 10
size=18, loc='left') # 11
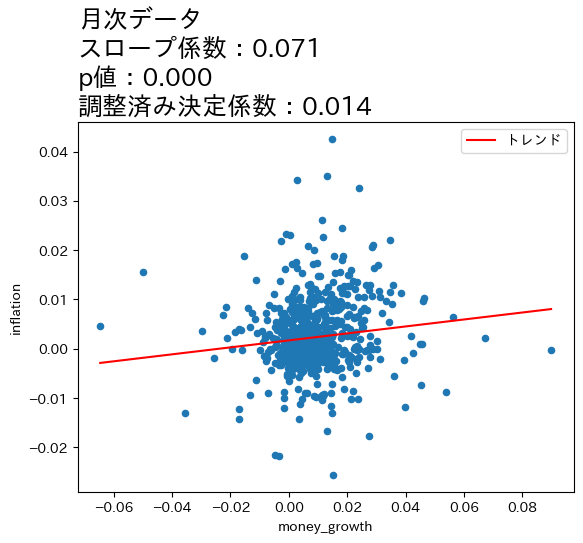
コード説明
それぞれのプロットのタイトルのリスト。
最小二乗法の結果を変数
resに割り当てる。res.fittedvaluesはOLSの予測値であり,新たな列としてそれぞれのDataFrameに追加する。その際の列名をトレンドとする。散布図を描き,生成される「軸」を
ax_に割り当てる。トレンド線を描く。
.sort_values('トレンド')を使って列トレンドを昇順に並び替える。color='r'は色を赤に指定する。ax=ax_はトレンド線を描く際,「軸」ax_を使うことをしてしている。f-stringを使ってタイトルを{t}に代入している。f-stringを使ってスロープ係数の推定値を代入している。.pvaluesは推定値を抽出するresのメソッドであり,1番目の要素であるスロープ係数を[1]で指定している。:.3fは小数点第三位まで表示することを指定している。
p値に関して(8)と同じことを行なっている。
調整済み決定係数に対して(8)と同じことを行なっている。
locはタイトルの位置を設定する引数。'left'は左寄せ'right'は右寄せ'center'は中央(デフォルト)
上の図とOLSの推定結果から次のことが分かる。
全てのケースで統計的優位性は高い。
データの期間が長くなるとともに,スロープ係数の値が増加し,調整済み決定係数も高くなっている。
これらのことからマネーストックの変化の影響は,より長い期間をかけてインフレへの影響が発生していることが伺える。この結果は,式(111)は長期的に成立することと整合的であると言えそうだ。
一方で,式(111)は係数が1になることを予測しているが,上の4つのケースの係数は全て1よりも低い値となっている。この点を念頭に,次の節では日本だけではなく170国以上のデータを使い,問題を再検討することにする。また,OLS結果は因果関係を示しておらず単なる相関関係を表していることは念頭に置いておこう。
Note
4つの図の縦軸・横軸の値を比べると,データが長くなるにつれて値が大きくなることがわかる。期間が長くなると増加率も上昇するということである。注意してほしいのは,増加率が上昇したために正の相関が強くなったという訳ではなく,増加率がより高くなっても正の相関は弱いまま,もしくは相関が存在しない場合もあり得る。図が示しているのは,データの期間が長くなると正の相関が「炙り出される」ということである。
世界経済のパネルデータ#
説明#
前節では日本のデータを使い,インフレ率に対するマネーストック増加率の影響が現れるには時間が掛かることを示した。一方でトレンド線の傾き(回帰分析のスロープ)は1よりも小さいが,式(111)は線形であり,\(m_t\)の計数は1である。即ち,マネーストックの増加率が1%上昇するとインフレ率も1%増加するという予測である。データと理論予測の齟齬をどう考えれば良いだろうか。一つの問題はノイズである。年次データであっても3年次データであってもその期間に短期的なありとあらゆるランダムな要素(ノイズ)が含まれている。ノイズは正や負の両方の影響があると考えられ,その分変化が激しいと思われる。長期的な関係は,正と負の影響が相殺し,その結果残った関係と考えることができる。この考えをデータで捉えるためにデータ全体の平均を計算すれば良いことになる。しかし前節で使用した日本の1955年から2020年のデータを使い,インフレ率とマネーストトック増加率の平均を計算すると,標本の大きさは1となってしまう。これではどうしようもないので,国数を増やし,観測値を増やす必要がある。従って,ここでは世界経済のパネルデータを使い2変数の関係を探ることにする。
py4macroに含まれるworld-moneyというデータ・セットを使うが,その内容は次のコードで確認できる。
py4macro.data('world-money',description=1)
| `iso`: ISO国コード
| `country`: 国名
| `year`: 年
| `income_group`: 世界銀行が定義する所得グループ
| * High income
| * Upper Middle income
| * Lower Middle income
| * Low income
| `money`: マネーストック(M1)
| `deflator`: GDPディフレーター
|
| * 年次データ
|
| <注意点>
| * `money`と`deflator`が10年間以上連続で欠損値がない経済(177ヵ国)のみが含まれている。
| * 国によって含まれるデータの`year`が異なる。
| * 所得グループに関する情報
| https://datahelpdesk.worldbank.org/knowledgebase/articles/906519-world-bank-country-and-lending-groups
|
| <出典>
| World Bank Development Indicators
国によってデータが使える期間が異なることに注意しよう。
まず変数worldにデータを割り当てる。
world = py4macro.data('world-money')
world.head()
| iso | country | year | income_group | money | deflator | |
|---|---|---|---|---|---|---|
| 0 | ALB | Albania | 1994 | Upper middle income | 3.876590e+10 | 35.739368 |
| 1 | ALB | Albania | 1995 | Upper middle income | 5.925260e+10 | 39.302820 |
| 2 | ALB | Albania | 1996 | Upper middle income | 9.040510e+10 | 54.305537 |
| 3 | ALB | Albania | 1997 | Upper middle income | 9.166720e+10 | 60.409306 |
| 4 | ALB | Albania | 1998 | Upper middle income | 8.372854e+10 | 64.475001 |
いつも通り.info()を使って内容を確かめてみよう。
world.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6584 entries, 0 to 6583
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 iso 6584 non-null object
1 country 6584 non-null object
2 year 6584 non-null int64
3 income_group 6584 non-null object
4 money 6584 non-null float64
5 deflator 6584 non-null float64
dtypes: float64(2), int64(1), object(3)
memory usage: 308.8+ KB
欠損値はないことが確認できる。
変化率の計算#
worldには経済ごとに10年以上に渡ってインフレ率とマネーストック増加率が含まれている。国ごとの変数の変化率を計算するには,以前紹介した.pivot()を使うことも可能だが,少し回りくどい計算になっている。ここでは異なる方法として.groupby()を紹介する。.groupby()はグループ内で何らかの計算をする際に非常に便利なメソッドである。次のステップに従って説明する。
DataFramをどの変数でグループ化するかを指定し,グループ化計算用のオブジェクトを用意する。ここでは経済ごとの平均を計算したいので,国
iso(もしくはcountry)でグループ化する。
グループ計算したい列を選ぶ。
ここでは
moneyとdeflationとなる。
どのような計算をしたいのかを指定する。
ここでは増加率なので
.pct_change()を使う。
<ステップ1>
グループ化用のオブジェクトの作成するためにはDataFrameのメソッド.groupby()を使い,その引数にグループ化用の列を指定する。ここではworldをisoでグループ化した変数world_groupに割り当てる。
world_group = world.groupby('iso')
world_group
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x134a5fdf0>
DataFrameGroupBy objectが生成されたことを知らせるメッセージである。このオブジェクトはworld自体をグループ化計算用に変換したものであり,DataFrameのように.loc[]などのメソッドは用意されていないので注意しよう。
<ステップ2>
グループ計算したいのはmoneyとdeflatorである。同時に指定しても構わないが,ここでは一つずつ指定することにする。例としてmoneyを考えよう。列を指定するには[]を使う。
world_group['money']
<pandas.core.groupby.generic.SeriesGroupBy object at 0x134a5f370>
SeriesGroupBy objectが生成されたことを知らせるメッセージである。ステップ1で生成されたDataFrameGroupBy objectからmoneyの箇所を取り出したグループ計算用オブジェクトである。Seriesとなっていることから分かるように,isoでグループ化され列money専用のグループ計算オブジェクトである。
<ステップ3>
グループ計算に平均を使いたいので,ステップ2のオブジェクトに.pct_change()をつか加えるだけである。
world_group['money'].pct_change()
0 NaN
1 0.528472
2 0.525758
3 0.013960
4 -0.086603
...
6579 1.700756
6580 -0.538285
6581 -0.547881
6582 0.479342
6583 0.936070
Name: money, Length: 6584, dtype: float64
返されたのは国ごとに計算されたマネーストック増加率である。Seriesとして返されているが,行の並びはworldと同じである。従って,次のコードでマネーストック増加率の列をworldに追加できる。
world['money_growth'] = world_group['money'].pct_change()*100
world.head()
| iso | country | year | income_group | money | deflator | money_growth | |
|---|---|---|---|---|---|---|---|
| 0 | ALB | Albania | 1994 | Upper middle income | 3.876590e+10 | 35.739368 | NaN |
| 1 | ALB | Albania | 1995 | Upper middle income | 5.925260e+10 | 39.302820 | 52.847219 |
| 2 | ALB | Albania | 1996 | Upper middle income | 9.040510e+10 | 54.305537 | 52.575752 |
| 3 | ALB | Albania | 1997 | Upper middle income | 9.166720e+10 | 60.409306 | 1.396050 |
| 4 | ALB | Albania | 1998 | Upper middle income | 8.372854e+10 | 64.475001 | -8.660303 |
列money_growthが最後に追加さている。Albaniaの最初の行である0番目の行はNaNになっているが,増加率を計算する際に発生している。同様に,全ての国の最初の行にはNaNが入っている(確かめてみよう)。
次にインフレ率を計算する。次のコードは上で説明した手順を1行で書いている。
world['inflation'] = world_group['deflator'].pct_change()*100
試しに,日本のデータだけを抽出してみよう。
world.query('iso=="JPN"')
| iso | country | year | income_group | money | deflator | money_growth | inflation | |
|---|---|---|---|---|---|---|---|---|
| 3022 | JPN | Japan | 1961 | High income | 4.102000e+12 | 24.337971 | NaN | NaN |
| 3023 | JPN | Japan | 1962 | High income | 6.090000e+12 | 25.360063 | 48.464164 | 4.199578 |
| 3024 | JPN | Japan | 1963 | High income | 7.702000e+12 | 26.757522 | 26.469622 | 5.510469 |
| 3025 | JPN | Japan | 1964 | High income | 8.704000e+12 | 28.183351 | 13.009608 | 5.328706 |
| 3026 | JPN | Japan | 1965 | High income | 1.028700e+13 | 29.631090 | 18.187040 | 5.136857 |
| 3027 | JPN | Japan | 1966 | High income | 1.171600e+13 | 31.104013 | 13.891319 | 4.970869 |
| 3028 | JPN | Japan | 1967 | High income | 1.336900e+13 | 32.813300 | 14.108911 | 5.495390 |
| 3029 | JPN | Japan | 1968 | High income | 1.515500e+13 | 34.427341 | 13.359264 | 4.918863 |
| 3030 | JPN | Japan | 1969 | High income | 1.828200e+13 | 35.953642 | 20.633454 | 4.433399 |
| 3031 | JPN | Japan | 1970 | High income | 2.421400e+13 | 44.213162 | 32.447216 | 22.972693 |
| 3032 | JPN | Japan | 1971 | High income | 3.097200e+13 | 46.464210 | 27.909474 | 5.091352 |
| 3033 | JPN | Japan | 1972 | High income | 3.857900e+13 | 49.068260 | 24.560894 | 5.604422 |
| 3034 | JPN | Japan | 1973 | High income | 4.561100e+13 | 55.302577 | 18.227533 | 12.705396 |
| 3035 | JPN | Japan | 1974 | High income | 5.106500e+13 | 66.811071 | 11.957642 | 20.810050 |
| 3036 | JPN | Japan | 1975 | High income | 5.684700e+13 | 71.606396 | 11.322824 | 7.177441 |
| 3037 | JPN | Japan | 1976 | High income | 6.381800e+13 | 77.340555 | 12.262740 | 8.007886 |
| 3038 | JPN | Japan | 1977 | High income | 6.893500e+13 | 82.560351 | 8.018114 | 6.749107 |
| 3039 | JPN | Japan | 1978 | High income | 7.797000e+13 | 86.361230 | 13.106550 | 4.603758 |
| 3040 | JPN | Japan | 1979 | High income | 8.071200e+13 | 88.737573 | 3.516737 | 2.751631 |
| 3041 | JPN | Japan | 1980 | High income | 7.930300e+13 | 93.563108 | -1.745713 | 5.437984 |
| 3042 | JPN | Japan | 1981 | High income | 8.678700e+13 | 96.301543 | 9.437222 | 2.926833 |
| 3043 | JPN | Japan | 1982 | High income | 9.193400e+13 | 97.981975 | 5.930612 | 1.744969 |
| 3044 | JPN | Japan | 1983 | High income | 9.198900e+13 | 98.908551 | 0.059826 | 0.945660 |
| 3045 | JPN | Japan | 1984 | High income | 9.812700e+13 | 100.365852 | 6.672537 | 1.473382 |
| 3046 | JPN | Japan | 1985 | High income | 1.010060e+14 | 101.630611 | 2.933953 | 1.260150 |
| 3047 | JPN | Japan | 1986 | High income | 1.112170e+14 | 103.269102 | 10.109300 | 1.612202 |
| 3048 | JPN | Japan | 1987 | High income | 1.166330e+14 | 103.106047 | 4.869759 | -0.157894 |
| 3049 | JPN | Japan | 1988 | High income | 1.262110e+14 | 103.750762 | 8.212084 | 0.625293 |
| 3050 | JPN | Japan | 1989 | High income | 1.299050e+14 | 105.938752 | 2.926845 | 2.108890 |
| 3051 | JPN | Japan | 1990 | High income | 1.350370e+14 | 108.698779 | 3.950579 | 2.605305 |
| 3052 | JPN | Japan | 1991 | High income | 1.428830e+14 | 111.881314 | 5.810259 | 2.927848 |
| 3053 | JPN | Japan | 1992 | High income | 1.477900e+14 | 113.745972 | 3.434278 | 1.666639 |
| 3054 | JPN | Japan | 1993 | High income | 1.575810e+14 | 114.392473 | 6.624941 | 0.568373 |
| 3055 | JPN | Japan | 1994 | High income | 1.641370e+14 | 114.696203 | 4.160400 | 0.265515 |
| 3056 | JPN | Japan | 1995 | High income | 1.907660e+14 | 114.084345 | 16.223642 | -0.533460 |
| 3057 | JPN | Japan | 1996 | High income | 2.087810e+14 | 113.517931 | 9.443507 | -0.496487 |
| 3058 | JPN | Japan | 1997 | High income | 2.498136e+14 | 114.089868 | 19.653417 | 0.503830 |
| 3059 | JPN | Japan | 1998 | High income | 2.616490e+14 | 114.038391 | 4.737692 | -0.045120 |
| 3060 | JPN | Japan | 1999 | High income | 2.903745e+14 | 112.545067 | 10.978639 | -1.309492 |
| 3061 | JPN | Japan | 2000 | High income | 3.001829e+14 | 110.987797 | 3.377845 | -1.383686 |
| 3062 | JPN | Japan | 2001 | High income | 3.111430e+14 | 109.761918 | 3.651141 | -1.104517 |
| 3063 | JPN | Japan | 2002 | High income | 3.796386e+14 | 108.161276 | 22.014186 | -1.458286 |
| 3064 | JPN | Japan | 2003 | High income | 4.506541e+14 | 106.412328 | 18.706080 | -1.616981 |
| 3065 | JPN | Japan | 2004 | High income | 4.695480e+14 | 105.241010 | 4.192550 | -1.100736 |
| 3066 | JPN | Japan | 2005 | High income | 4.944894e+14 | 104.149203 | 5.311789 | -1.037435 |
| 3067 | JPN | Japan | 2006 | High income | 4.953890e+14 | 103.229172 | 0.181925 | -0.883378 |
| 3068 | JPN | Japan | 2007 | High income | 4.967105e+14 | 102.476136 | 0.266760 | -0.729480 |
| 3069 | JPN | Japan | 2008 | High income | 4.904771e+14 | 101.470952 | -1.254936 | -0.980895 |
| 3070 | JPN | Japan | 2009 | High income | 4.971079e+14 | 100.850688 | 1.351908 | -0.611273 |
| 3071 | JPN | Japan | 2010 | High income | 5.133780e+14 | 98.939403 | 3.272951 | -1.895164 |
| 3072 | JPN | Japan | 2011 | High income | 5.412710e+14 | 97.282835 | 5.433229 | -1.674326 |
| 3073 | JPN | Japan | 2012 | High income | 5.607333e+14 | 96.541973 | 3.595666 | -0.761555 |
| 3074 | JPN | Japan | 2013 | High income | 5.914823e+14 | 96.220317 | 5.483712 | -0.333177 |
| 3075 | JPN | Japan | 2014 | High income | 6.203437e+14 | 97.899664 | 4.879504 | 1.745314 |
上で説明したように,列money_growthとinflationの0番目の行の要素はNaNとなっている。
ハイパーインフレ#
ハイパーインフレの確固たる定義はないが,Mankiwの教科書「マクロ経済学」では年率50%以上と定義している。この定義に基づき,ハイパーインフレは観測値の何%を占めるかを計算してみよう。まずinflationでNaNではない行の数を数える。
notna = world.loc[:,'inflation'].notna().sum()
notna
6407
コードの説明
欠損値であるNaNはna(not available)とも呼ばれる。メソッド.notna()は文字通りnaではない要素にはTrueをnaである要素にはFalseを返す。.sum()はTrueの数を合計している。
inflationの値がNaNではない行は6407あることがわかった。次にinflationが50%以上の行数を数えてみよう。
hyper = len( world.query('inflation >= 50') )
hyper
300
print(f'観測値の{100*hyper/notna:.2f}%でハイパーインフレが発生している。')
観測値の4.68%でハイパーインフレが発生している。
次にinflationの上位5ヵ国を表示してみよう。
world.sort_values('inflation',ascending=False).head()
| iso | country | year | income_group | money | deflator | money_growth | inflation | |
|---|---|---|---|---|---|---|---|---|
| 1413 | COD | Congo, Dem. Rep. | 1994 | Low income | 3725130.0 | 0.001219 | 5635.381062 | 26765.858252 |
| 4277 | NIC | Nicaragua | 1988 | Lower middle income | 33480.0 | 0.000091 | 11673.429423 | 13611.634819 |
| 680 | BOL | Bolivia | 1985 | Lower middle income | 111800000.0 | 17.094034 | 3587.821612 | 12338.622324 |
| 4719 | PER | Peru | 1990 | Upper middle income | 707331500.0 | 3.608738 | 6724.820224 | 6261.239559 |
| 4279 | NIC | Nicaragua | 1990 | Lower middle income | 52778530.0 | 0.223530 | 6286.714344 | 5016.107950 |
トップはコンゴ共和国(COD)の年率26,766%!しかし,この数字はあまりピンとこないかもしれないので,次式を使って一日のインフレ率に換算してみよう。
ここで\(g_{{年}}\)は年率のインフレ率であり,\(g_{{日}}\)は1日当たりのインフレ率。この式を使い1に当たりの平均インフレ率を計算してみる。
inflation_cod = world.query('(iso=="COD") & (year==1994)').loc[:,'inflation']
inflation_cod_day = 100*( (1+inflation_cod/100)**(1/365)-1 )
inflation_cod_day
1413 1.544252
Name: inflation, dtype: float64
1日平均約1.54%のインフレ率となる。日本で考えると,最近の年率でのインフレ率よりも高い数字である(2021年8月現在)。もう少し身近に感じられるように,物価が2倍になるには何日かかるかを考えてみよう。\(t\)日後に物価は2倍になるとすると,次式が成立する。
この式を使って\(t\)を計算してみよう。
np.log(2)/np.log(1+inflation_cod_day/100)
1413 45.231317
Name: inflation, dtype: float64
約45日間で物価は2倍になることが分かる。
プロット#
全てのデータを使って散布図をプロットしトレンドを計算してみる。
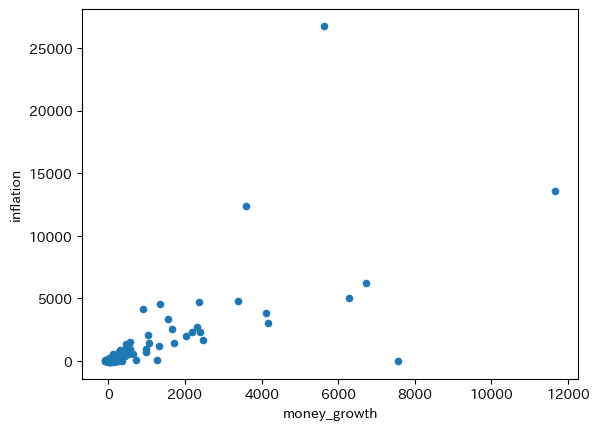
world.plot('money_growth','inflation',kind='scatter')
pass
コードの説明
worldにはinflationとmoney_growthがNaNとなっている行が含まれるが,上の図では自動的に省かれる。world.dropna().plot()としても図は変わらない。
横軸と縦軸の値(%)を確認してみると分かるが非常に大きい。ノイズの影響により変化が非常に激しいためである。トレンドのスロープを計算してみよう。
res_world = sm.ols('inflation ~ money_growth', data=world).fit()
print(f'標本の大きさ:{int(res_world.nobs)}')
print(f'調整済み決定係数:{res_world.rsquared_adj:.3f}')
res_world.summary().tables[1]
標本の大きさ:6407
調整済み決定係数:0.537
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -9.6447 | 3.843 | -2.510 | 0.012 | -17.178 | -2.112 |
| money_growth | 1.2802 | 0.015 | 86.259 | 0.000 | 1.251 | 1.309 |
トレンドのスロープは1.28であり,1に近いがノイズの影響が大きいようである。
この結果と比較したいのが,次のケースである。
それぞれの国で
inflationとmoney_growthの平均を計算し,その散布図をプロットするとともに傾きを計算する。
まず,それぞれの経済の2変数の平均を計算するが,一つ注意点がある。worldにinflationとmoney_growthがあるので,.mean()を使って平均を計算すれば良いと思うかもしれない。しかし.mean()は算術平均であり,計算したいのは増加率の平均なので可能であれば幾何平均を使うべきである。残念ながら,DataFrameには幾何平均のメソッドが良いされて良いないので,次のようにforループで計算することにする。
money_growth_mean_list = [] # 1
inflation_mean_list = [] # 2
iso_list = [] # 3
country_list = [] # 4
income_group_list = [] # 5
for c in world.loc[:,'iso'].unique(): # 6
df = world.query('iso==@c').reset_index() # 7
n = len(df) # 9
money_growth_mean = 100*( # 9
(df.loc[n-1,'money']/df.loc[0,'money'])**(1/(n-1))-1
)
inflation_mean = 100*( # 10
(df.loc[n-1,'deflator']/df.loc[0,'deflator'])**(1/(n-1))-1
)
# 11
money_growth_mean_list.append(money_growth_mean)
inflation_mean_list.append(inflation_mean)
iso_list.append(c)
# 12
country_list.append(df.loc[:,'country'].unique()[0])
# 13
income_group_list.append(df.loc[:,'income_group'].unique()[0])
# 14
world_mean = pd.DataFrame({'country':country_list,
'income_group':income_group_list,
'money_growth_mean':money_growth_mean_list,
'inflation_mean':inflation_mean_list,
'iso':iso_list}).set_index('iso')
コードの説明
マネーストックの平均増加率を格納する空のリスト。
平均インフレ率を格納する空のリスト。
国のisoを格納する空のリスト。
国名を格納するリスト。
所得グループ名を格納するリスト。
データにある経済全てに対しての
forループを開始world.loc[:,'iso']は列isoを抽出し,.unique()を使って経済のリストを作成する。
.query('iso==@c')でc国の行だけを抽出し,reset_index()で行インデックスを振り直す。c国のDataFrameをdfに割り当てる。dfの行数をnに割り当てる。dfの列moneyの最初と最後の行の値を使って平均増加率を計算する。100*で%表示にする。dfの列deflatorの最初と最後の行の値を使って平均インフレ率を計算する。100*で%表示にする。money_growth_mean,inflation_mean,cをそれぞれ対応するリストに追加する。国名を
country_listに追加する。df.loc[:,'country']で列countryを抽出し,.unique()で国名が入るarrayが返される。[0]はその0番目の要素を抽出している。
所得グループ名を
income_group_listに追加する。df.loc[:,'income_group']で列income_groupを抽出し,.unique()でグループ名が入るarrayが返される。[0]はその0番目の要素を抽出している。
money_growth_mean_list,inflation_mean_list,country_listを使いDataFrameを作成しworld_meanに割り当てる。.set_index('iso')はisoを行ラベルに設定している。
Tip
実は.groupby()使って幾何平均を計算することも可能である。例えば,次のコードでマネーストック増加率の幾何平均を計算できる。
from scipy.stats import gmean # 1
world.groupby('iso')['money'].agg(gmean) # 2
簡単なコードで良いが,(1)にある関数を導入する必要があり,また(2)の.agg()を使う必要がある。上のコードはforループに慣れることを一つの目的としている。
平均でハイパーインフレが発生している国は何ヵ国なるのか計算してみよう。
hyper = ( world_mean.loc[:,'inflation_mean'] >= 50 ).sum()
print(f'{len(world_mean)}ヵ国中{hyper}ヵ国でハイパーインフレが発生している。')
177ヵ国中7ヵ国でハイパーインフレが発生している。
コードの説明
world_mean.loc[:,'inflation_mean']でinflation_meanの列を抽出。world_mean.loc[:,'inflation_mean'] >= 50を使い,列inflation_meanの要素が50以上であればTrue,50未満であればFalseとなるSeriesを返す。Trueは1,Falseは0と等しいので,.sum()で合計することによってハイパーインフレ国の数が計算できる。
短期的なノイズの影響によってある年にハイパーインフレが発生する場合もあるだろう。しかしこの結果は,長期的にハイパーインフレに悩まされる国が存在することを示している。どのような国なのかを確認するために,インフレ率上位10ヵ国を表示してみよう。
world_mean.sort_values(by='inflation_mean', ascending=False).head(10)
| country | income_group | money_growth_mean | inflation_mean | |
|---|---|---|---|---|
| iso | ||||
| COD | Congo, Dem. Rep. | Low income | 122.442962 | 127.704505 |
| AGO | Angola | Lower middle income | 108.457354 | 92.231798 |
| BRA | Brazil | Upper middle income | 92.023344 | 88.882771 |
| ARG | Argentina | Upper middle income | 79.169900 | 74.971614 |
| NIC | Nicaragua | Lower middle income | 67.774841 | 62.717663 |
| BLR | Belarus | Upper middle income | 65.667637 | 62.536094 |
| UKR | Ukraine | Lower middle income | 58.537270 | 61.867179 |
| PER | Peru | Upper middle income | 54.905117 | 48.305760 |
| ARM | Armenia | Upper middle income | 48.970412 | 46.680070 |
| AZE | Azerbaijan | Upper middle income | 52.949213 | 45.247656 |
やはり所得水準が比較的に低い国が入っている。
world_meanを使いクロスセクションのデータをプロットしてみよう。
ax_ = world_mean.plot('money_growth_mean','inflation_mean', kind='scatter')
xpoints = ypoints = ax_.get_ylim()
ax_.plot(xpoints,ypoints,'r-', label='45度線')
ax_.set_title('平均インフレ率とマネーストトックの平均成長率', size='15')
ax_.legend()
pass
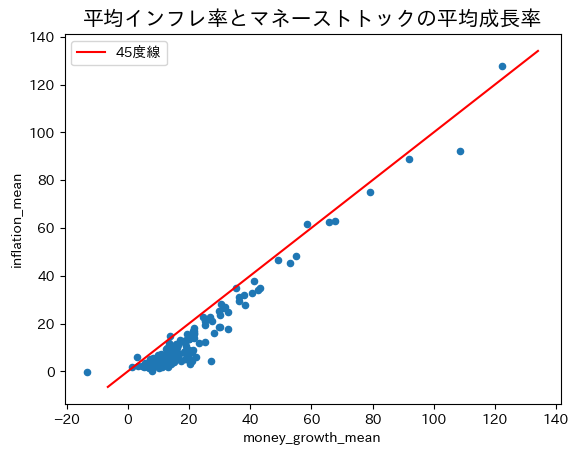
綺麗に45度線上に並んでいる。国ごとに平均を計算することによって短期的なノイズが相殺され長期的な関係が浮かび上がっている。トレンド線の傾きを計算してみよう。
res_world_mean = sm.ols('inflation_mean ~ money_growth_mean', data=world_mean).fit()
print(f'標本の大きさ:{int(res_world_mean.nobs)}')
print(f'調整済み決定係数:{res_world_mean.rsquared_adj:.3f}')
print(res_world_mean.summary().tables[1])
標本の大きさ:177
調整済み決定係数:0.945
=====================================================================================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------------------------------------------
Intercept -6.0805 0.461 -13.175 0.000 -6.991 -5.170
money_growth_mean 0.9847 0.018 54.876 0.000 0.949 1.020
=====================================================================================
推定値は1に非常に近い。もし図の左下にある外れ値のように見える値(ジンバブエ)を省くとスロープ係数は0.997になる。長期的には式(111)が示すように,マネーストック増加率の1%上昇はインフレ率1%上昇につかがること示す結果である。「真のメカニズム」の一部が垣間見えるような気がしませんか。