一物一価と購買力平価#
import japanize_matplotlib
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import py4macro
import statsmodels.formula.api as smf
# numpy v1の表示を使用
np.set_printoptions(legacy='1.21')
# 警告メッセージを非表示
import warnings
warnings.filterwarnings("ignore")
はじめに#
通常,経済の生活水準の指標には一人当たりGDPが使われる。データはそれぞれの国が集めており,日本では内閣府がGDP関連のデータを公表している。当たり前だが,GDPなどの変数はその経済の貨幣単位で表される。自国通貨建てのデータは国内で使うには十分だが,他国と比較する場合は共通の貨幣で表す必要がある。例えば,日本と米国の生活水準や政府の教育関連支出額の違いを知るためには,両国のデータを円もしくは米ドルに返還する必要がある。また,変数の水準だけではなく成長率を考える際も同様である。
では,ある通貨を他の通貨単位に換算する際,新聞やインターネットで見る市場為替レートを使えば良いのだろうか。答えは否である。その理由を理解するのが本章の1つの目的となる。異なる経済のデータを比べる際は購買力平価(PPP; Purchasing Power Parity)と呼ばれる「為替レート」を使う必要がある。実際,py4macroモジュールに含まれるデータセットpwt(Penn World Table)はPPPで換算したマクロデータを使っている。
以下では、まずPPPと関連が深い一物一価の法則について国内のデータを使い考える。その後,経済間のデータとしてビッグマック(マクドナルドのハンバーガー)のデータを使い経済間での一物一価を考察する。また一般物価水準についても考察し,経済間で一般物価水準が異なる要因として所得水準を考え,所得水準の影響が大きいことを明らかにする。特に,所得水準の影響により,市場為替レートを使い計算した一人当たりGDPの比較をおこなうと,経済間の所得格差が歪められることになる。そのような歪みを排除して経済間の生活水準を比べるためには,PPPレートを使う必要があることを示す。
Note
私たちの周りには価格が法的に定められたものがある。例えば,
鉄道運賃(JR,通学定期,JR西日本,幹線,高校,20km):38,650円(2023年4月)
この価格は鉄道事業法(昭和61年法律第92号)に基づいている。以下では,法律ではなく市場によって価格が決まる財・サービスを考える。
国内での一物一価#
説明#
一物一価の法則とは,市場の働きにより同質財・サービスは同じ価格で販売される,ということを意味する。直感的に説明するために,A市とB市で同質財が販売されているとしよう(A市を1つの市場,B市をもう1つの市場と考えると良いだろう)。話を簡単にするために,輸送費用,取引費用や価格の硬直性など市場の「摩擦」が無い理想的な状況の下,A市では80円で,B市では100円で販売されているとしよう。B市で高値で商品が売れるのであれば,A市で安く購入してB市で80円<価格<100円の価格で売れば利潤を得ることができる。例えば,ある企業はA市で財をX個仕入れて,それをB市で販売する場合,利潤\(\pi\)は次式となる。
ここで\(p_BX\)が総収入であり,\(p_AX\)が総費用である。\(p_B<p_A\)が成立する限り\(\pi>0\)となる。一方で,利潤があれば,同様のことをする企業が参入する。この様な裁定取引により,A市での需要が増加し価格が上昇する。一方,B市では供給が増えるので価格は下落する。参入は利潤がなくなるまで続くことになり,最終的には財の価格は収斂することになる。即ち,
このように,一物一価は非常に直感的な概念である。では,データではどのようになっているのだろうか。以下では小売物価統計調査(動向編)のデータを用いる。使うデータはチョコレート,アイスクリーム,ガソリンの2022年平均価格であり,pandasを使ってe-Stat(政府統計の総合窓口)から直接ダウンロードする。
Note
手動でダウンロードする場合は,次の順番でリンクを辿っていけば良いだろう。
小売物価統計調査(動向編) →
調査の結果をクリック →全品目:平成13年(2001年)~2022年をクリック →2022年報をクリック →統計表をクリック →2022年をクリックチョコレートとアイスクリームのデータは
【09】「1701 ようかん」 ~ 「1784 ゼリー」の右側にあるEXCELをクリックするとダウンロードできる。ガソリンは
【26】「7691 鉄道運賃」 ~ 「7413 通信料」の右側にあるEXCELをクリックするとダウンロードできる。
チョコレート#
板チョコレート,50~55g,「明治ミルクチョコレート」,「ロッテガーナミルクチョコレート」又は「森永ミルクチョコレート」
このチョコレートの定義に従って作成されたデータをダウンロードし,変数chocoにDateFrameとして割り当てる。
url_choco = 'https://www.e-stat.go.jp/stat-search/file-download?statInfId=000040047298&fileKind=0'
choco = pd.read_excel(url_choco, sheet_name='1761チョコレート',
skiprows=15, usecols=[8,10])
🐍 コードの説明
pd.read_excel()はExcelファイルを読み込む関数url_choco:その上のURLを文字列としてファイルを指定する引数(URLでなくてもファイル名でも良い)sheet_name:Excelのシート名を指定する引数skiprows:最初の何行を飛ばして読み込むかを指定する引数usecols:何番目の列を読み込むかを指定する引数
pd.read_excel()を使うにはモジュールopenpyxlが事前にインストールされている必要がある。参照リンク。
最初の5行を表示してみよう。
choco.head()
| 地域 | 年平均 | |
|---|---|---|
| 0 | 札幌市 | 227 |
| 1 | 函館市 | 211 |
| 2 | 旭川市 | 209 |
| 3 | 青森市 | 220 |
| 4 | 八戸市 | 225 |
列ラベルが全角になっている。そのままでも良いが,ここでは次の様に半角に変更する。
choco.columns = ['area', 'price']
次にデータ型や欠損値を調べてみよう。
choco.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 81 entries, 0 to 80
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 area 81 non-null object
1 price 81 non-null int64
dtypes: int64(1), object(1)
memory usage: 1.4+ KB
どのような地域が含まれているか確認してみよう。
choco['area'].tolist()
['札幌市',
'函館市',
'旭川市',
'青森市',
'八戸市',
'盛岡市',
'仙台市',
'秋田市',
'山形市',
'福島市',
'郡山市',
'水戸市',
'日立市',
'宇都宮市',
'小山市',
'前橋市',
'さいたま市',
'熊谷市',
'川口市',
'所沢市',
'千葉市',
'佐倉市',
'浦安市',
'東京都区部',
'八王子市',
'立川市',
'府中市',
'横浜市',
'川崎市',
'相模原市',
'横須賀市',
'新潟市',
'長岡市',
'富山市',
'金沢市',
'福井市',
'甲府市',
'長野市',
'松本市',
'岐阜市',
'静岡市',
'浜松市',
'富士市',
'名古屋市',
'岡崎市',
'津市',
'松阪市',
'大津市',
'京都市',
'大阪市',
'堺市',
'枚方市',
'東大阪市',
'神戸市',
'姫路市',
'西宮市',
'伊丹市',
'奈良市',
'和歌山市',
'鳥取市',
'松江市',
'岡山市',
'広島市',
'福山市',
'山口市',
'宇部市',
'徳島市',
'高松市',
'松山市',
'今治市',
'高知市',
'福岡市',
'北九州市',
'佐賀市',
'長崎市',
'佐世保市',
'熊本市',
'大分市',
'宮崎市',
'鹿児島市',
'那覇市']
兵庫県からは神戸市,姫路市,西宮市,伊丹市が含まれている。
記述統計も確認しよう。
choco['price'].describe()
count 81.000000
mean 217.604938
std 8.204692
min 192.000000
25% 212.000000
50% 218.000000
75% 223.000000
max 242.000000
Name: price, dtype: float64
最安値は192円,最高値は242円であり,その差は50円!
価格の分布を調べるために,平均からの乖離率を計算しよう。
ここで\(i\)は地域を表しており,\(\overline{P}\)は\(P_i\)の平均である。新たな列mean_deviationとして追加しよう。
choco['mean_deviation'] = choco['price'] / choco['price'].mean() - 1
choco.plot.hist(y='mean_deviation', bins=12, ec='white')
pass
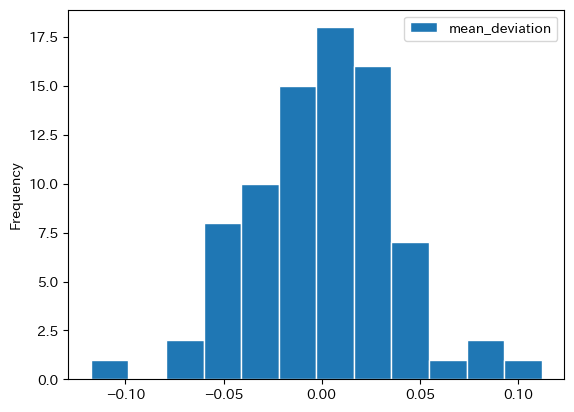
0は平均と等しいという意味である。0.10は平均より10%高い価格であり,-0.10は平均より10%安いチョコレートである。明らかに一物一価は成立していない。
価格のばらつき具合を確認するために標準偏差を計算しよう。
print(
choco['mean_deviation'].std()
)
0.03770453161138014
乖離率(57)の標準偏差は次式で定義される変動係数(Coefficient of Variation)と等しい。
試しに変動係数を直接計算してみよう。
print(
choco['price'].std() / choco['price'].mean()
)
0.03770453161138012
同じ値である。変動係数の利点は,変数の平均で除している為,単位(ここでは,円)や平均の大小に関係なく,異なるデータのばらつき具合を比べることができることである。
最後に,チョコレートが最安値の地域はどこか確認してみよう。
cond = ( choco['price']==choco['price'].min() )
choco.loc[cond,:]
| area | price | mean_deviation | |
|---|---|---|---|
| 7 | 秋田市 | 192 | -0.117667 |
秋田市ではチョコレートが平均よりも約11.8%も安い。(甘党の楽園かも!?)
アイスクリーム#
アイスクリームの定義
バニラアイスクリーム,カップ入り(110mL入り),「ハーゲンダッツ バニラ」
データをダウンロードして,変数iceに割り当てよう。
url_ice = 'https://www.e-stat.go.jp/stat-search/file-download?statInfId=000040047298&fileKind=0'
ice = pd.read_excel(url_ice, sheet_name='1782アイスクリーム',
skiprows=15, usecols=[8,10])
最初の5行の表示
ice.head()
| 地域 | 年平均 | |
|---|---|---|
| 0 | 札幌市 | 296 |
| 1 | 函館市 | 286 |
| 2 | 旭川市 | 281 |
| 3 | 青森市 | 260 |
| 4 | 八戸市 | 258 |
列ラベルの変更
ice.columns = ['area', 'price']
データの確認
ice.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 81 entries, 0 to 80
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 area 81 non-null object
1 price 81 non-null int64
dtypes: int64(1), object(1)
memory usage: 1.4+ KB
記述統計
ice['price'].describe()
count 81.000000
mean 263.888889
std 18.672172
min 210.000000
25% 258.000000
50% 267.000000
75% 276.000000
max 300.000000
Name: price, dtype: float64
最安値は210円,最高値は300円であり,その差は90円!(著者のように)ハーゲンダッツ好きにとっては無視できない価格差である。
ice['mean_deviation'] = ice['price'] / ice['price'].mean() - 1
ice.plot.hist(y='mean_deviation', bins=16, ec='white')
pass
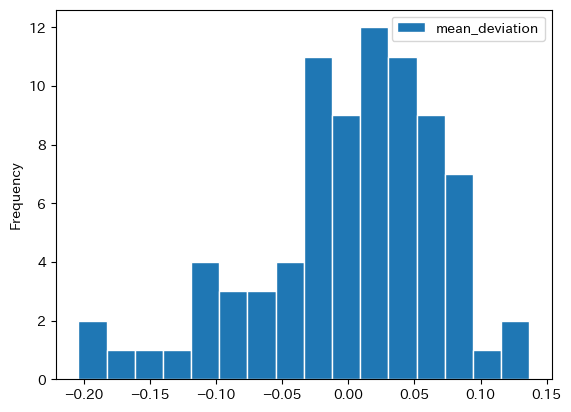
安いところは平均よりも約20%もお得!いずれにしろ,一物一価は成立していない。
価格のばらつき具合を確認するために標準偏差(変動係数)を計算してみよう。
print(
ice['mean_deviation'].std()
)
0.0707577036906862
チョコレートと比較すると価格のばらつきが大きい。
安い地域と高い地域を確認してみよう。
ice.sort_values(by='price', ascending=False)
| area | price | mean_deviation | |
|---|---|---|---|
| 80 | 那覇市 | 300 | 0.136842 |
| 0 | 札幌市 | 296 | 0.121684 |
| 35 | 福井市 | 289 | 0.095158 |
| 60 | 松江市 | 288 | 0.091368 |
| 1 | 函館市 | 286 | 0.083789 |
| ... | ... | ... | ... |
| 15 | 前橋市 | 232 | -0.120842 |
| 21 | 佐倉市 | 223 | -0.154947 |
| 22 | 浦安市 | 216 | -0.181474 |
| 37 | 長野市 | 211 | -0.200421 |
| 38 | 松本市 | 210 | -0.204211 |
81 rows × 3 columns
この順番を見て何か言えることがあるだろうか。考えてみよう!
ガソリン#
ガソリンの定義
レギュラー・ガソリン1L
変数gasにDataFrameとして割り当てよう。
url_gas = 'https://www.e-stat.go.jp/stat-search/file-download?statInfId=000040047335&fileKind=0'
gas = pd.read_excel(url_gas, sheet_name='7301ガソリン',
skiprows=15, usecols=[8,10])
最初の5行の表示
gas.head()
| 地域 | 年平均 | |
|---|---|---|
| 0 | 札幌市 | 167 |
| 1 | 函館市 | 167 |
| 2 | 旭川市 | 169 |
| 3 | 青森市 | 166 |
| 4 | 八戸市 | 164 |
列ラベルの変更
gas.columns = ['area', 'price']
データの詳細
gas.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 81 entries, 0 to 80
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 area 81 non-null object
1 price 81 non-null int64
dtypes: int64(1), object(1)
memory usage: 1.4+ KB
記述統計
gas['price'].describe()
count 81.000000
mean 170.604938
std 4.718790
min 160.000000
25% 168.000000
50% 170.000000
75% 174.000000
max 184.000000
Name: price, dtype: float64
最安値は160円,最高値は184円であり,その差は24円。平均からの乖離のヒストグラムをプロットしよう。
gas['mean_deviation'] = gas['price'] / gas['price'].mean() - 1
gas.plot.hist(y='mean_deviation', ec='white')
pass
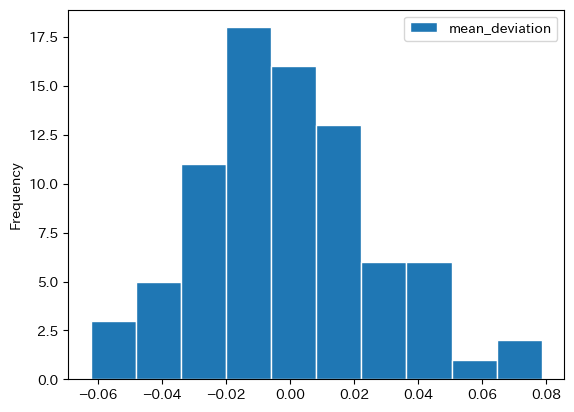
平均から高くても約7.9%,安くても約6.2%程しか違わない。標準偏差(変動係数)を計算してみよう。
print(
gas['mean_deviation'].std()
)
0.02765916186178425
アイスクリームよりも価格のばらつきは小さい。直感的に,ガソリンスタンドへは車やバイクで行くことになり,消費者が価格を比較し少しでも安いスタンドへ行く費用が安いためかも知れない。
最高値の地域は?
cond = ( gas['price']==gas['price'].max() )
gas.loc[cond,:]
| area | price | mean_deviation | |
|---|---|---|---|
| 77 | 大分市 | 184 | 0.078515 |
結論#
データを見る限り一物一価の法則は成立していない。主な理由は,前提となっている条件が満たされていないためである。冒頭でA市とB市の例を挙げたが,離れている場合は輸送費用がかかる。また,距離が遠くなれば情報の収集にもコストが掛かることになるだろうし,市場が異なれば取引費用も違ってくるかも知れない。このような費用を財1単位当たりで\(\tau\)と表すと,利潤(55)は次式となる。
ここで,\(\tau X\)が輸送費用などを捉えている。利潤がゼロになるまで企業が参入したとしても,
となり,A市の財ががB市よりも安いままの状態が続くことになる。
経済間での一物一価:Big Mac#
はじめに#
国内市場では一物一価の法則は成立しないことが分かった。では,経済間ではどうだろうか。国際貿易の輸送費用は更に高く,国境を跨ぐ情報伝達も時間がかかり,ビジネス慣例が違うことにより取引費用もかさむだろう。更には,そもそも貿易されない財・サービス(例えば,理髪)が存在し,裁定取引が成立しない。このように考えると,経済間でも一物一価の法則が成り立たないことは明らかだろう。
しかし,2つ疑問点が残る。第1に,経済間における価格の散らばりの程度はどれくらいなのだろうか。国内市場よりも経済間の価格差の方が大きいと推測できるが,変動係数で考えるとどれほどの差が存在するのだろうか。2倍もしくは10倍だろうか?第2に,経済間の所得格差は大きく,日本の一人当たりGDPの5%に満たない国も存在する(発展会計を参照)。所得格差は財・サービスの需要の大きさに反映される。正常財であれば,所得が高い経済の需要は高くなり,価格は高くなるのではないかと想像できる。また所得が高い国では生産性も高い。実際,生産性が高く(従って,所得が高い)経済では価格が高い傾向になることが知られている。この節では,世界中で概ね同質財と考えられるマクドナルドのハンバーガーBig Macを取り上げ,これらの問いを考察する。
Big Macの違い
国毎にBig Macは多少の違いがあるようだ。このリンクを参照。
データ#
py4etricsに含まれるデータ・セットbigmacを使って議論を進める。まず含まれる変数の定義を表示してみよう。
py4macro.data('bigmac', description=True)
| `year`: 年(2000年〜)
| `country`: 国名
| `iso`: ISO国コード
| `currency_code`: 通貨コード
| `price_local`: Big Macの価格(自国通貨単位)
| `exr`: 名目為替レート(自国通貨単位/米ドル)
| `gdppc_local`: 名目一人当たりGDP(自国通貨単位)
|
| * 年次データ
|
| <出典>
| https://github.com/TheEconomist/big-mac-data (Copyright The Economist)
データセットを変数bigmacに割り当てて,最初の5行を表示してみる。
bigmac = py4macro.data('bigmac')
bigmac.head()
| year | country | iso | currency_code | price_local | exr | gdppc_local | |
|---|---|---|---|---|---|---|---|
| 0 | 2000 | Argentina | ARG | ARS | 2.50 | 1.00 | 9283.18 |
| 1 | 2000 | Australia | AUS | AUD | 2.59 | 1.68 | 32394.17 |
| 2 | 2000 | Brazil | BRA | BRL | 2.95 | 1.79 | 6029.89 |
| 3 | 2000 | Canada | CAN | CAD | 2.85 | 1.47 | 31222.68 |
| 4 | 2000 | Switzerland | CHE | CHF | 5.90 | 1.70 | 61942.36 |
このでは2023年のデータを使う。2023年のデータだけを抽出しbigmacに再割り当てしよう。
cond = ( bigmac['year']==2023 )
bigmac = bigmac.loc[cond,:].copy()
コードの説明
ここで説明している問題を避けるために,メソッド.copy()を使っている。ここで使わなくても問題はないが,使わなければ警告が表示されることになる。
それぞれの変数のデータ型と欠損値を確認しよう。
bigmac.info()
<class 'pandas.core.frame.DataFrame'>
Index: 72 entries, 1159 to 1230
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 year 72 non-null int64
1 country 72 non-null object
2 iso 72 non-null object
3 currency_code 72 non-null object
4 price_local 72 non-null float64
5 exr 72 non-null float64
6 gdppc_local 72 non-null float64
dtypes: float64(3), int64(1), object(3)
memory usage: 4.5+ KB
一物一価#
これから行う作業を説明するために変数を定義しよう。
\(P_i=\) \(i\)国のBig Macの価格(自国通貨)
\(P_{\text{JP}}=\) 日本のBig Macの価格(円)
\(P_{\text{US}}=\) 米国のBig Macの価格(米ドル)
bigmacの列price_localに対応
\(e_i=\) 名目為替レート(\(i\)国通貨/米ドル)
\(e_{\text{JP}}=\) 名目為替レート(円/米ドル)
\(e_{\text{US}}=1\)
bigmacの列exrに対応
これらの変数を使うと,\(i\)国のBig Macの米ドル表示価格は次式で計算できる。
一物一価が成立する場合は\(\dfrac{P_i}{e_i}\)と\(P_{\text{US}}\)(ドル表示)が等しくなる。
Hint
単位を確認することで為替レートが入る数式を簡単に理解できる。例えは,\(c_i\)を\(i\)国の通貨単位として,(61)の右辺を単位で表してみよう。
となり,単位が米ドルになっているのが分かる。また,式(63)の右辺を考えてみよう。
1円に対する\(i\)国の貨幣単位になっている。次に,実質為替レート(72)の右辺を単位で表してみよう。
となり,貨幣単位がキャンセルされて無くなってしまう。実質為替レートは,実質変数であり貨幣単位から独立しているためである。
このまま\(i\)国と米国を考えて議論を進めることもできるが,以下では円を基準に置いて分析を進めよう。その場合,\(i\)国のBig Macの円表示価格は次式で計算できる。
ここで
は\(i\)国通貨/円の市場為替レートである。\(\dfrac{P_i}{e_{iJP}}\)と\(P_{\text{JP}}\)(円表示)が等しくなると一物一価の成立となるが,そうならないことをデータで確認することになる。
国内財と同様に,平均価格を基準にし乖離率を考えることもできるが,日本と比べてどれだけ違うかを計算するために,ここでは日本のBig Macの価格に対しての乖離率を考える。
まず式(64)を計算するために,変数ejpに円/ドル為替レートを割り当てよう。
cond = ( bigmac['iso']=='JPN' )
ejp = bigmac.loc[cond,'exr'].iloc[0]
print(ejp)
142.08
ejp,local_price,exrを使い各国のBig Macを円表示に変換し,新たな列yen_priceとしてbigmacに追加しよう。
bigmac['price_yen'] = ( bigmac['price_local']/bigmac['exr'] )*ejp
日本の価格を確認してみよう。
cond = ( bigmac['iso']=='JPN' )
bigmac.loc[cond,['price_local','price_yen']]
| price_local | price_yen | |
|---|---|---|
| 1195 | 450.0 | 450.0 |
米国の価格はどうだろう。
cond = ( bigmac['iso']=='USA' )
bigmac.loc[cond,['price_local','price_yen']]
| price_local | price_yen | |
|---|---|---|
| 1227 | 5.58 | 792.8064 |
日本の価格450円と比べると,米国でのBig Macの価格は少し高く感じる。記述統計を確認してみよう。
bigmac['price_yen'].describe()
count 72.000000
mean 647.093073
std 169.651670
min 339.076894
25% 505.350594
50% 666.820588
75% 767.585089
max 1098.155390
Name: price_yen, dtype: float64
最安値339と最高値1098には大きな差(759円)があることが分かる。平均価格647円は日本の価格450円を上回っている。
次に,日本の価格からの乖離率を計算しよう。
# 日本の価格
cond = ( bigmac['iso']=='JPN')
yen_price_jpn = bigmac.loc[cond,'price_yen'].iloc[0]
# 米国の価格に対してi国の価格の乖離率
bigmac['price_yen_deviation'] = bigmac['price_yen'] / yen_price_jpn - 1
ヒストグラムをプロットする。
bigmac.plot.hist(y='price_yen_deviation', ec='white')
pass
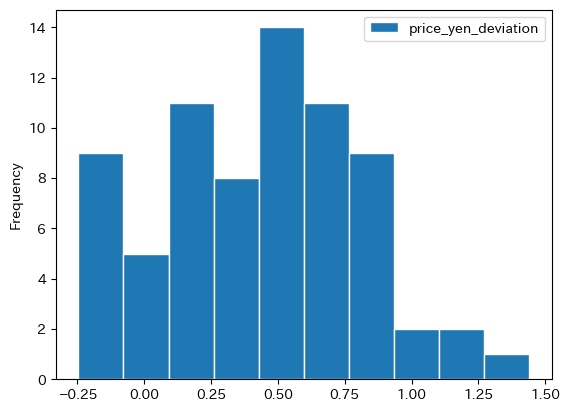
0.0が日本となる。一番高い国を調べてみよう。
cond = ( bigmac['price_yen'] == bigmac['price_yen'].max() )
bigmac.loc[cond,['country','price_yen','price_yen_deviation']]
| country | price_yen | price_yen_deviation | |
|---|---|---|---|
| 1168 | Switzerland | 1098.15539 | 1.440345 |
Switzerlandの価格は約1098円となっている。次に,価格が最も低い国を表示してみよう。
cond = ( bigmac['price_yen']==bigmac['price_yen'].min() )
bigmac.loc[cond,['country','price_yen','price_yen_deviation']]
| country | price_yen | price_yen_deviation | |
|---|---|---|---|
| 1224 | Taiwan | 339.076894 | -0.246496 |
Taiwanが一番安く,日本より約24.6%も安価である。
明らかにBig Macの一物一価は成立していない。
価格のばらつき具合を確認し,上で確認した国内財の価格と比較するために,変動係数(平均からの乖離の標準偏差と同じ)を計算しよう。
print(
bigmac['price_yen'].std() / bigmac['price_yen'].mean()
)
0.26217506693057535
国内のチョコレート,アイスクリーム,ガソリン価格の標準偏差よりも非常に大きな値となっている。
理由として次のことが言えるだろう。
Big Macは消耗財であり,貿易されずに生産された地域で消費される。言い換えると,消耗財が故に輸送費用は非常に高い非貿易財である。
非貿易財の場合,国境を超えた競争が妨げられる。神戸のマクドナルドは,ロンドンやシンガポールのマクドナルドと価格競争をしているとは言い難い。
所得の影響#
価格が最も高い15カ国国をリストアップしてみよう。
bigmac_sorted = (
bigmac.sort_values('price_yen',ascending=False)
.loc[:,['country','price_yen','price_yen_deviation']]
)
bigmac_sorted.head(15)
| country | price_yen | price_yen_deviation | |
|---|---|---|---|
| 1168 | Switzerland | 1098.155390 | 1.440345 |
| 1207 | Norway | 983.106806 | 1.184682 |
| 1226 | Uruguay | 974.413346 | 1.165363 |
| 1193 | Italy | 908.570106 | 1.019045 |
| 1180 | Finland | 900.737605 | 1.001639 |
| 1160 | Argentina | 851.628372 | 0.892507 |
| 1174 | Germany | 836.511097 | 0.858914 |
| 1206 | Netherlands | 834.944597 | 0.855432 |
| 1181 | France | 830.245096 | 0.844989 |
| 1179 | Euro area | 827.112096 | 0.838027 |
| 1221 | Sweden | 814.957088 | 0.811016 |
| 1177 | Spain | 814.580095 | 0.810178 |
| 1175 | Denmark | 802.961253 | 0.784358 |
| 1191 | Ireland | 798.915093 | 0.775367 |
| 1227 | United States | 792.806400 | 0.761792 |
コードの説明
丸括弧()の中にコードを書く場合,任意の箇所で改行してもエラーにはならない。1行で長いコードを書く場合に便利なので覚えておこう!
全て所得が高い先進国となっている。価格が最も安い10カ国を確認してみよう。
bigmac_sorted.tail(10)
| country | price_yen | price_yen_deviation | |
|---|---|---|---|
| 1185 | Hong Kong | 419.023683 | -0.068836 |
| 1204 | Malaysia | 414.360612 | -0.079199 |
| 1225 | Ukraine | 403.948396 | -0.102337 |
| 1212 | Philippines | 400.954028 | -0.108991 |
| 1230 | South Africa | 398.666873 | -0.114074 |
| 1228 | Venezuela | 386.278992 | -0.141602 |
| 1176 | Egypt | 372.141633 | -0.173019 |
| 1190 | India | 361.035298 | -0.197699 |
| 1189 | Indonesia | 358.026525 | -0.204385 |
| 1224 | Taiwan | 339.076894 | -0.246496 |
貧しい国が並んでいる。実は,この結果は偶然ではない。Big Macの価格と所得の散布図を使い相関関係を確かめてみるために,円表示の一人当たりGDPを計算しよう。新たな列gdppc_yenを作成する
bigmac['gdppc_yen'] = ( bigmac['gdppc_local']/bigmac['exr'] )*ejp
散布図をプロットしよう。
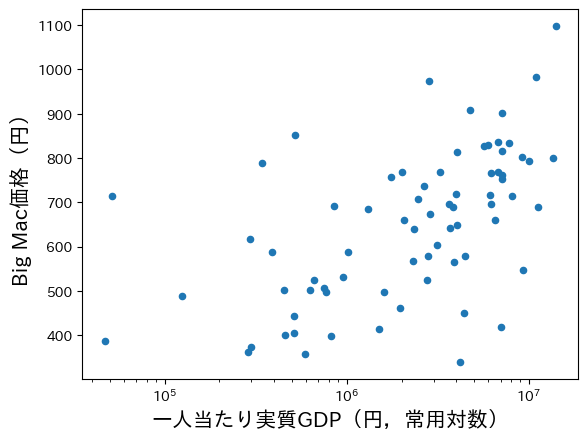
ax = bigmac.plot.scatter(x='gdppc_yen', y='price_yen', logx=True)
ax.set_xlabel('一人当たり実質GDP(円,常用対数)', fontsize=15)
ax.set_ylabel('Big Mac価格(円)', fontsize=15)
pass
コードの説明
1行目のlogx=Trueは,横軸の変数gdppc_yenを対数化することを指定している。もし縦軸も対数化したければlogy=Trueを使うと良いだろう。これらの引数を使うことにより,対数化した変数をbigmacに追加することなく図示できる。便利なので覚えておこう!
明らかに所得が高い国ではBig Macの価格は高くなっている。理由は,市場為替レートを使い円に変換していることに起因する。この現象の経済学的な含意については後ほど議論することにする。
Note
価格水準と所得の正の関係は経済間だけではなく,国内のデータでも観測されている。Cheung and Fujii (2014)は日本のデータを使い,都道府県の価格と所得の間に正の相関があることを報告している。
購買力平価と物価水準の分布#
PPPとは#
前節の分析から分かったことは,市場為替レートで各国のBig Macの価格を共通貨幣単位(上の例では円)で表し価格を比べてみると,一物一価は成立していないということである。また,国内財と比較して分布の幅は大きいことも確認できた。今度は逆に,Big Macの一物一価が成立する場合の交換レートはどのように定義されるかを考えてみよう。
\(e_{i}^{\text{BM}}\)がBig Macの一物一価レートであり,単位は「\(i\)国通貨/米ドル」である。左辺では\(e_{i}^{\text{BM}}\)により\(i\)国通貨表示の価格\(P_i\)が米ドルに換算され,右辺の\(P_{\text{US}}\)と等価となっている。この式を書き換えると
となる。
Big Macだけではなく財・サービスの種類を大幅に広げて,上述の考えを適用したのが購買力平価(PPP, Purchasing Power Parity)レートである。それぞれの経済で消費される同じような典型的な共通の財・サービスを集めて大きなバスケット(大きな籠)に入れることを想像しよう。多くの財・サービスが入ったバスケットを1つの財(合成財)として考え,バスケット財と呼ぶことにしよう。バスケット財に含まれる様々な財の価格は各経済で異なることになり,その結果,バスケット財の価格も異なる。バスケット財には多種多様の財・サービスが含まれているため,その価格を各国の一般物価水準と考えることができる。購買力平価(PPP)レートとは,バスケット財が等価となる為替レートとして算出される。次式は\(i\)国の対米国PPPレートである。
\(P_i\):\(i\)国の自国通貨価格で表した一般物価水準(バスケット財の価格)
\(P_{\text{US}}\):米国の自国通貨価格(米ドル)で表した一般物価水準(バスケット財の価格)
\(\varepsilon_i\):\(i\)国のPPPレート(\(i\)国通貨/米ドル)
式(67)について4つ説明を加える。
右辺の単位は\(i\)国の通貨/ドルとなり,\(e_i^{\text{BM}}\)と同じ単位である。実際,\(\varepsilon_i\)は為替レートの一種であり,市場為替レートと異なるため特別な呼称「購買力平価レート」が付いている。
上の式は\(P_i/\varepsilon_i=P_{\text{US}}\)と書くことができる。この式の右辺は米国のバスケット財の価格,即ち,一般物価水準であり,左辺は\(i\)国のバスケット財,即ち,一般物価水準を米ドルに換算した価格である。等号は,それらが等しいことを意味しており,その意味では,バスケット財の一物一価が成立する場合の為替レートということになる。まとめると,PPPレートは次のように解釈することができる。
購買力平価レート\(\varepsilon_i\)は,バスケット財の一物一価が成立する(一般物価水準が同じになる)ために必要な為替レート(注意:バスケット財に含まれる個々の財・サービスの価格が全て等しいとは限らない。)
次の変数を考えよう。
\(Q_i\)と\(Q_{\text{US}}\):\(i\)国と米国でのバスケット財の数量
\(P_i\)と\(P_{\text{US}}\):\(i\)国と米国でのバスケット財の価格
\(M_i\):\(i\)国の自国通貨の数量
\(M_{\text{US}}\):米ドルの数量
それぞれの通貨はバスケット財の支出に使われる場合を考えると次の関係になる。
(68)#\[ M_i=P_iQ_i,\qquad M_{\text{US}}=P_{\text{US}}Q_{\text{US}} \]またバスケット財で測ったそれぞれの通貨の購買力は次式で表される。
(69)#\[ \frac{M_i}{P_i}=Q_i,\qquad \frac{M_{\text{US}}}{P_{\text{US}}}=Q_{\text{US}} \]それぞれの通貨の購買力が等しくなる場合,\(Q_i=Q_{\text{US}}\)が成立する。即ち,
(70)#\[ \frac{M_i}{P_i}=\frac{M_{\text{US}}}{P_{\text{US}}} \qquad\Rightarrow\qquad \frac{M_i}{M_{\text{US}}}=\frac{P_i}{P_{\text{US}}} \]となる。右の式の左辺は,1米ドルと\(i\)国通貨の交換レート(単位は\(i\)国通貨/1米ドル)を表している。それを\(\varepsilon_i\)と置き換えるとPPPレート
(71)#\[ \varepsilon_i=\frac{P_i}{P_{\text{US}}} \]となる。このことから次のように解釈できる。
購買力平価レート\(\varepsilon_i\)は2つの通貨の購買力を等しくする交換レート
実質為替レートは次式で与えられる。
(72)#\[ \eta_i=\frac{e_iP_{\text{US}}}{P_i}=\frac{e_i}{\varepsilon_i} \]ここで\(\varepsilon_i\)は式(67)で与えられるPPPレートであり,\(e_i\)は市場為替レートである。更に,
(73)#\[ \eta_i=1 \quad\Leftrightarrow\quad e_i=\varepsilon_i \]が成立することになる。即ち,実質為替レートが
1の場合に\(e_i=\varepsilon_i\)となり,「購買力平価が成立した」という。
Note
PPPレートは次のようにも解釈できる。式(72)と(72)から,PPPの下では次式が成立する。
分子の\(P_i\)の単位は「\(i\)国の通貨」であり,\(\varepsilon_i\)の単位は「\(i\)国の通貨/ドル」となるため,分子の単位はドルとなることが分かる(\(i\)国の通貨単位がキャンセルされる)。分母の単位はもちろん米ドルである。更に,次のように書き換えよう。
分子は1万ドルで米国のバスケット財をいくつ購入できるかを表しており,それが米ドルの購買力である。同様に,分母は1万ドルで購入できる\(i\)国のバスケット財の数量を表し,\(i\)国のバスケット財で測った米ドルの購買力となる。即ち,右辺は1万ドルの米国での購買力と\(i\)国での購買力の割合となる。右辺が1と等しいということは,1万ドルの米国での購買力と\(i\)国での購買力は同じだということを意味する。
以上の説明から,一物一価の法則と購買力平価が密接に関係していることは直感的に理解できるだろう。以下では,バスケット財の価格は経済間で大きく異なり,購買力平価は成立していないことを示す。更には,その原因と含意についても考察することにする。
PPPレートと市場為替レートのデータ#
使用するデータ#
経済間のバスケット財の価格の違いを確認するために,py4macroモジュールに含まれるPenn World Tableのデータセットを使う。
pwt = py4macro.data('pwt')
変数の定義を確認しておこう。
py4macro.data('pwt', description=True)
| Variable definition | |
|---|---|
| Identifier variables | NaN |
| countrycode | 3-letter ISO country code |
| country | Country name |
| currency_unit | Currency unit |
| year | Year |
| Real GDP, employment and population levels | NaN |
| rgdpe | Expenditure-side real GDP at chained PPPs (in mil. 2021US$) |
| rgdpo | Output-side real GDP at chained PPPs (in mil. 2021US$) |
| pop | Population (in millions) |
| emp | Number of persons engaged (in millions) |
| avh | Average annual hours worked by persons engaged |
| hc | Human capital index, based on years of schooling and returns to education; see Human capital in PWT9. |
| Current price GDP, capital and TFP | NaN |
| ccon | Real consumption of households and government, at current PPPs (in mil. 2021US$) |
| cda | Real domestic absorption, (real consumption plus investment), at current PPPs (in mil. 2021US$) |
| cgdpe | Expenditure-side real GDP at current PPPs (in mil. 2021US$) |
| cgdpo | Output-side real GDP at current PPPs (in mil. 2021US$) |
| cn | Capital stock at current PPPs (in mil. 2021US$) |
| ck | Capital services levels at current PPPs (USA=1) |
| ctfp | TFP level at current PPPs (USA=1) |
| cwtfp | Welfare-relevant TFP levels at current PPPs (USA=1) |
| National accounts-based variables | NaN |
| rgdpna | Real GDP at constant 2021 national prices (in mil. 2021US$) |
| rconna | Real consumption at constant 2021 national prices (in mil. 2021US$) |
| rdana | Real domestic absorption at constant 2021 national prices (in mil. 2021US$) |
| rnna | Capital stock at constant 2021 national prices (in mil. 2021US$) |
| rkna | Capital services at constant 2021 national prices (2021=1) |
| rtfpna | TFP at constant national prices (2021=1) |
| rwtfpna | Welfare-relevant TFP at constant national prices (2021=1) |
| labsh | Share of labour compensation in GDP at current national prices |
| irr | Real internal rate of return |
| delta | Average depreciation rate of the capital stock |
| Exchange rates and GDP price levels | NaN |
| xr | Exchange rate, national currency/USD (market+estimated) |
| pl_con | Price level of CCON (PPP/XR), price level of USA GDPo in 2021=1 |
| pl_da | Price level of CDA (PPP/XR), price level of USA GDPo in 2021=1 |
| pl_gdpo | Price level of CGDPo (PPP/XR), price level of USA GDPo in 2021=1 |
| Data information variables | NaN |
| i_cig | 0/1/2/3/4: relative price data for consumption, investment and government is extrapolated (0), benchmark (1), interpolated (2), ICP PPP timeseries: benchmark or interpolated (3) or ICP PPP timeseries: extrapolated (4) |
| i_xm | 0/1/2: relative price data for exports and imports is extrapolated (0), benchmark (1) or interpolated (2) |
| i_xr | 0/1: the exchange rate is market-based (0) or estimated (1) |
| i_outlier | 0/1: the observation on pl_gdpe or pl_gdpo is not an outlier (0) or an outlier (1) |
| i_irr | 0/1/2/3: the observation for irr is not an outlier (0), may be biased due to a low capital share (1), hit the lower bound of 1 percent (2), or is an outlier (3) |
| cor_exp | Correlation between expenditure shares of the country and the US (benchmark observations only) |
| Shares in CGDPo | NaN |
| csh_c | Share of household consumption at current PPPs |
| csh_i | Share of gross capital formation at current PPPs |
| csh_g | Share of government consumption at current PPPs |
| csh_x | Share of merchandise exports at current PPPs |
| csh_m | Share of merchandise imports at current PPPs |
| csh_r | Share of residual trade and GDP statistical discrepancy at current PPPs |
| Price levels, expenditure categories and capital | NaN |
| pl_c | Price level of household consumption, price level of USA GDPo in 2021=1 |
| pl_i | Price level of capital formation, price level of USA GDPo in 2021=1 |
| pl_g | Price level of government consumption, price level of USA GDPo in 2021=1 |
| pl_x | Price level of exports, price level of USA GDPo in 2021=1 |
| pl_m | Price level of imports, price level of USA GDPo in 2021=1 |
| pl_n | Price level of the capital stock, price level of USA in 2021=1 |
| pl_k | Price level of the capital services, price level of USA=1 |
以下の分析では次の変数を使う。
xr:市場為替レート(名目,\(i\)国通貨/米ドル)pl_gdpo:cgdpoの計算に使った相対物価水準(米ドル,2017年の米国の値=1)cgdpo:産出データに基づいGDP(2017年百万米ドル)時系列的には名目(ある年での経済間の生産能力(水準)の比較に適している)
pl_gdpoを使って計算している
Note
cgdpoは産出データに基づいたGDPだが,その代わりに支出データに基づいたcgdpeを使うこともできる。その場合,相対物価水準の変数にはpl_daを使う必要がある。試してみよう!
8_Solow.ipynbpwtの中にはPPPレートのデータは含まれていないが,xrとpl_gdpoを使い次のように計算することができる。pl_gdpoは次式に従い計算されている。
ここで\(\epsilon_i\)は式(67)で与えられるPPPレートであり,\(e_i\)は市場為替レートとなる。従って,\(e_i\)に列xrを使い次式でPPPレートを計算することができる。
この式に従って,新たな列pppをpwtに追加しよう。
pwt['ppp'] = pwt['pl_gdpo'] * pwt['xr']
例:日本#
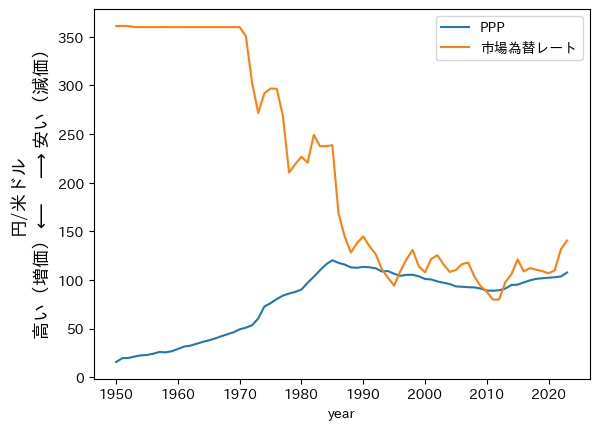
まず,PPPレートと市場為替レートがどれほど違うかを日本の時系列データで確認するために,日本のデータのみを抽出する。日本のPPPと市場為替レートをプロットしてみよう。
cond = ( pwt['countrycode']=='JPN' )
ax = pwt.loc[cond,:].plot(x='year', y=['ppp','xr'], label=['PPP','市場為替レート'])
ax.set_ylabel('円/米ドル\n'+
r'高い(増価)$\longleftarrow\quad\longrightarrow$安い(減価)', fontsize=13)
pass
Note
上のプロットの縦軸は円/米ドルであり,値が低く(高く)なると円は強く(弱く)なる。増価,減価とも表現される。分かりにくいようであれば,次のように考えてみてはどうだろう。
為替レートが100円/ドルということは,100円で1ドルを買うことができる。
為替レートが80円/ドルの場合は,80円で1ドルを買うことができる。即ち,より安くドルを買うことができるので,円の購買力は高くなる。そういう意味で,円は強くなった(増価した)と言える。
為替レートが120円/ドルの場合は,120円で1ドルを買うことになる。即ち,より高い価格でドルを買うことになるので,円の購買力は低下している。そういう意味で,円は弱くなった(減価した)と言える。
このプロットから次のことが言える。市場為替レートは1973年2月14日に変動相場制へ移行するまで360円/1米ドルで固定されていた。1980年代半ば頃までは,PPPレートと比べて市場為替レートは高い値となっている。従って,PPPレートを基準とすると円はドルに対して弱すぎる,即ち,過小評価されていたことが分かる。長期的にはPPPレートと為替レートは収斂したことが確認できる。しかし,1980年代半ば以降,市場為替レートはPPPレートの周りを上下していおり,ある程度の乖離は解消されていない。
このように,PPPレートと市場為替レートは乖離することが常であり,異なる要因によって決定されるためである。PPPは式(67)が示すように財・サービスの価格の比率であり,一般物価水準そしてその変化率(インフレ率)も持続性が高い(粘着生)ためPPPの動きは緩やかである。一方,市場為替レートは貨幣単位の比率であり,国際収支の状況にも大きく依存する。国際収支には(1)経常収支(財・サービスの収支など),(2)資本移転等収支(例えば,特許権などの知的財産権),(3)金融収支(直接投資,証券投資,金融派生商品など金融資産に伴う取引)があるが,特に(2)と(3)は一般物価水準との関係は少なくとも短期的には弱い。従って,市場為替レートは経済情報や政治状況,更には,中央銀行総裁や政治家の発言で影響を受け大きく瞬時に変動することがある。しかし,上の日本のレートのプロットが示すように,長期的には乖離が持続的に拡大するような発散は起きていない。1980年代半ばまでの時系列データが示すように,お互いに時間をかけて収束する経済メカニズムが裏で働いていると考えられる。
上のプロットではPPPレートと市場為替レートを別々にプロットしたが,一つの指標としてまとめる方が分かりやすい場合もある。式(72)を使い日本の実質為替レート\(\eta_{\text{JP}}\)を考えてみよ。
ここで\(e_{\text{JP}}\)は市場為替レート(円/米ドル)であり,\(\varepsilon_{\text{JP}}\)はPPPレートである。この式から次のことが分かる。
\(\eta_{\text{JP}}=1\quad\Rightarrow\quad e_{\text{JP}}=\varepsilon_{\text{JP}}\)
購買力平価の成立
日本のバスケット財1単位で米国のバスケット財1単位を購入できる(等価で交換できる)。
\(\eta_{\text{JP}}<1\quad\Rightarrow\quad e_{\text{JP}}<\varepsilon_{\text{JP}}\)
PPPレートと比較しては強すぎる(過大評価)
例えば,\(\eta_{\text{JP}}=1/2\)の場合,日本のバスケット財1単位で米国のバスケット財2単位も購入できる(交換できる)。そういう意味で,円の購買力は高過ぎる(強過ぎる)。
\(\eta_{\text{JP}}>1\quad\Rightarrow\quad e_{\text{JP}}>\varepsilon_{\text{JP}}\)
PPPレートと比較して円は弱すぎる(過小評価)
例えば,\(\eta_{\text{JP}}=2\)の場合,日本のバスケット財1単位で米国のバスケット財1/2単位しか購入できない(交換できない)。そういう意味で,円の購買力は低過ぎる(弱過ぎる)
式(76)と(78)を比べると,\(\eta_{\text{JP}}\)はpl_gdpoの逆数となることがわかる。実質為替レートを新たな列real_xrとしてpwtに追加しよう。
pwt['real_xr'] = 1 / pwt['pl_gdpo']
1980年以降のデータをプロットしよう。
cond_jp = ( pwt['countrycode']=='JPN' )
cond_yr = ( pwt['year']>=1980 )
cond = cond_jp & cond_yr
ax = pwt.loc[cond,:].plot(x='year', y='real_xr', legend=False)
ax.axhline(1, color='red')
ax.set_title('実質為替レート(円/米ドル)', fontsize=20)
pass
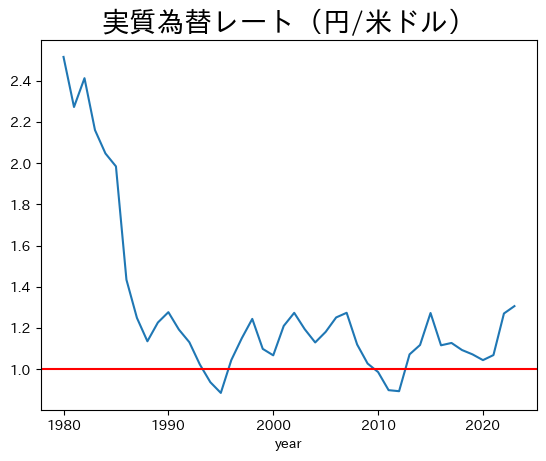
この図は,上の図の情報を実質為替レート(円/ドル)としてまとめている。実質為替レートでも,縦軸での円安・円高の方向は同じとなることに注意しよう。1980年代半ばまで円高に動いていること(増価)が分かる。
Note
国際通貨研究所では円(対米ドル)の購買力平価を公表しているが,pwtのデータとは大きく異なる。理由は,それぞれの目的とアプローチが違うためである。Penn World Tableで使うPPPは,共通の財・サービスの分類に基づいた国際比較プログラム(International Comparison Programme:省略ICP)により計算された情報を使っており,参加国(2017年には176カ国)のGDPや支出項目が比較可能になるPPPの算出を目的としている。従って,大掛かりな作業が必要であり,毎年ではなく数年に一度公表される(1970年, 1973年, 1975年, 1980年, 1985, 1993年, 2005年, 2011年, 2017年)。Penn World Tableのデータでは,それ以外の年は内挿(interpolate)もしくは外挿(extrapolate)することによりPPPを計算している。一方,国際通貨研究所で公表しているPPPは,1973年を基準としてシンプルに日米の消費者物価指数などを使って算出されており,指数の計算に使われる財・サービスは厳密に共通化されている訳ではない。後者は円ドル市場為替相場の予測や日本経済の国際競争力を知る上では有用な情報となるだろう。
相対一般物価水準の分布#
Big Macは世界中で消費され,世界中のBig Macは概ね同質と考えることができる。そのような財でさえ一物一価が成立していないことを考えると,バスケット財の一物一価の成立を疑いたくなる。実際,以下で示すように,データは一般物価の等価は成立しない。では,
バスケット財の価格(一般物価水準)はどのような分布になっているのだろうか。
この問を考察するために,米国を基準とする米ドル表示の相対一般物価水準考えることにする。相対価格で考える利点は,その分布をPPPレートと市場為替レートを使うことにより簡単に計算できることである。
式(76)から列pl_gdpoの定義は次のようになっている。
相対一般物価水準の分布を調べるためにはpl_gdpoを使えば良いということだ。
まず2023年を変数latest_yrに割り当てよう。
latest_yr = pwt['year'].max()
latest_yr
2023
この変数を使い、2023年のデータを抽出してdfに割り当てる。
cond = ( pwt['year']==latest_yr )
df = pwt.loc[cond,:].copy()
pl_gdpoが欠損値ではない国の数を確認しておこう。
df['pl_gdpo'].notna().sum()
185
このデータを使い相対価格のヒストグラムをプロットするが,視覚的に確認し易いように対数化した列を作成し図示する。(試しに,対数を使う目的を理解するためにpl_gdpoのヒストグラムと比べてみてはどうだろう。)
df['pl_gdpo_log'] = np.log( df['pl_gdpo'] )
df.plot.hist(y='pl_gdpo_log', ec='white')
pass
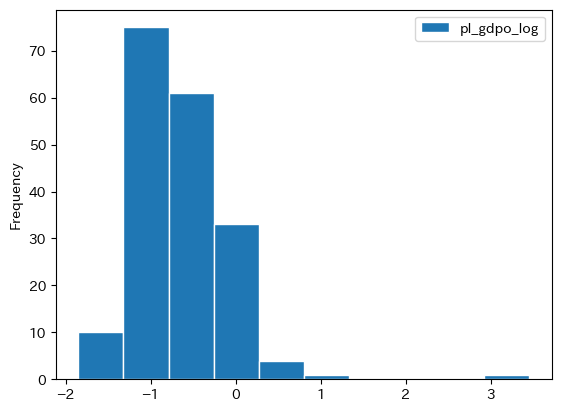
次のような解釈となる。
0と等しい場合:米国の2021年の物価水準と同じ0を上回る場合:米国の2021年の物価水準を上回る0を下回る場合:米国の2021年の物価水準を下回る
その内訳を確認してみよう。
cond = ( df['pl_gdpo_log']>=0 )
print(f'相対一般物価水準が1以上の国の数:{df.loc[cond,:].shape[0]:>3}')
print(f'相対一般物価水準が1未満の国の数:{df.loc[~cond,:].shape[0]:>3}')
相対一般物価水準が1以上の国の数: 18
相対一般物価水準が1未満の国の数:167
コードの説明
最後の行に~condとなっているが,~はビット演算子の一つである。condはTrueもしくはFalseが要素となるSeriesであるが,~をcondの前に付けると全ての真偽値を反転(TrueはFalseに,FalseはTrueに)させる。ビット演算子には他に&,|,^,などがある。
一般物価水準の相対価格の分布には大きな偏りが確認できる。pl_gdpo(対数ではない)の記述統計を表示してみよう。
df['pl_gdpo'].describe()
count 185.000000
mean 0.749977
std 2.305667
min 0.157181
25% 0.368505
50% 0.474792
75% 0.739722
max 31.620178
Name: pl_gdpo, dtype: float64
価格水準が最も低い国は米国の物価水準(2021年)の約15.7%しかなく,最も高い国は米国の約31.6倍も高い。上位5カ国を表示してみよう。
df.sort_values('pl_gdpo',ascending=False)[['country','pl_gdpo']].head()
| country | pl_gdpo | |
|---|---|---|
| 13245 | Venezuela (Bolivarian Republic of) | 31.620178 |
| 11987 | Turks and Caicos Islands | 2.313789 |
| 1923 | Barbados | 2.210862 |
| 1701 | Bermuda | 2.023847 |
| 3255 | Cayman Islands | 1.445766 |
ベネズエラのpl_gdpoの値は突出している。ベネズエラの2018年のインフレは1,700,000%(年率)のハイパーインフレが発生しており,その影響かもしれないが,他の経済の傾向と大きく異なる「外れ値」の可能性を払拭できない。以下ではベネズエラを除外して分析を進めることにする。
cond = ~( df['countrycode']=='VEN' )
df = df.loc[cond,:].copy()
ベネズエラを除いたデータでpl_gdpoの変動係数を計算してみよう。
print(
df['pl_gdpo'].std() / df['pl_gdpo'].mean()
)
0.5680280895931845
この値をBig Macの値と比べてみよう。Big Macの変動係数は0.262であり,0.3にも満たない。バスケット財に含まれる財・サービスはBig Mac程規格が統一されていないことを考えると一般物価水準の変動係数が大きいことは理解できるのではないだろうか。
Note
上で計算したBig Mac価格の変動係数は,相対価格ではなくBig Mac価格(円表示)の変動係数である。米国のBig Mac価格に対する相対価格の変動係数を次のコードで計算することができるが,同じ値を返すことになる。
bigmac['price_dollar'] = bigmac['price_local'] / bigmac['exr']
cond = ( bigmac['iso']=='USA' )
bigmac['relative_price_dollar'] = bigmac['price_dollar'] / bigmac.loc[cond,'price_dollar'].iloc[0]
bigmac['relative_price_dollar'].std() /bigmac['relative_price_dollar'].mean()
物価水準に対する所得の影響#
所得の影響#
相対物価水準のヒストグラムをプロットしたが,どのような国がどのような順番並んでいるか表示してみよう。表示するリストを見やすくするために,183カ国全てを表示せずに,行avh(人的資本ストック)に欠損値がない国だけを表示しよう。このルールに特別な意味はないが,国の数を減らすには丁度良いだろう。
コードの説明
#1:.dropna(subset=['avh])を使い列avhに欠損値がある行のみを削除し,.sort_values(‘pl_gdpo_log’)によってpl_gdpo_logの昇順に並び替え,最初の5行を省いたDataFrameをdf_dropped`に割り当てている。#2:.stem()はステムプロットを表示するメソッドであり,横軸に列country,縦軸にpl_gdpo_logを指定している。#3:orientationはステムプロットの向きを横向きに指定する引数。この引数により,縦軸・横軸が逆になる。#4:bottomは値の基準を指定する引数。ここでは0に赤い線が引かれる。#5:dataは使用するデータを指定する。#6:横軸の値範囲を指定している。#7:.axhline()は横線を表示するメソッド。Japanは縦軸のJapanで横線を引くことを指定し,linestyle=':'は点線を 指定している。#8:.tick_params(axis='y', labelsize=8)は縦軸に表示されている国名の表示サイズを調整している。#9:.margins()はボックスの中のマージンを調整しており,y=0.01は上下のマージンを、x=0は左右のマージンを設定する。#10:df_dropped.shape[0]でdf_droppedの行数を抽出し,f-stringを使い`結果を表示している。
#1
df_dropped = df.dropna(subset=['avh']).sort_values('pl_gdpo_log').iloc[5:,:]
fig, ax = plt.subplots(figsize=(6,17))
ax.stem('country', 'pl_gdpo_log', #2
orientation='horizontal', #3
bottom=0, #4
data=df_dropped) #5
ax.set_xlim(-1.5,0.5) #6
ax.set_title('米国の2017年の物価水準と比較して\n'+
r'低い $\longleftarrow\quad$2019年の物価水準$\quad\longrightarrow$ 高い',
size=17)
ax.axhline('Japan', linestyle=':') #7
ax.tick_params(axis='y', labelsize=8) #8
ax.margins(x=0, y=0.01) #9
#10
print(f'このプロットには{df_dropped.shape[0]}カ国が含まれる。')
このプロットには124カ国が含まれる。
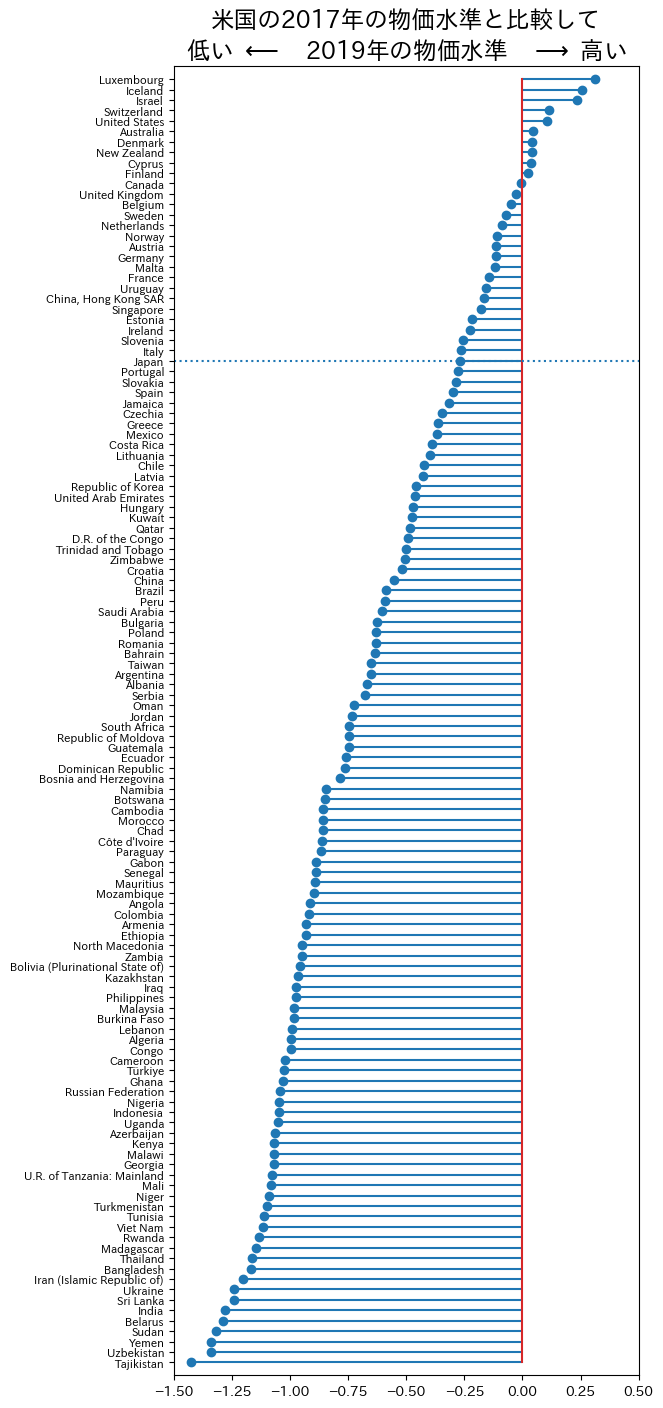
リストの上には所得が高い国が列挙されており,所得が低い国はリストの下の方にある。この傾向はBig Macの場合と同じである。
物価水準と所得の関係を散布図を使って確認するために,一人当たりGDPとその対数値を新たな列cgdpo_pcとcgdpo_pc_logを追加しよう。
df['cgdpo_pc'] = df['cgdpo']/df['pop']
df['cgdpo_pc_log'] = np.log( df['cgdpo_pc'] )
またpl_gdpoの対数の値を新たな列pl_gdpo_logとして追加しよう。
df['pl_gdpo_log'] = np.log( df['pl_gdpo'] )
cgdpo_pc_logを横軸にしてpl_gdpo_logの散布図を表示しよう。
ax = df.plot.scatter(x='cgdpo_pc_log', y='pl_gdpo_log')
ax.set_xlabel('一人当たりGDP(対数,百万米ドル)', fontsize=15)
ax.set_ylabel('米国の2017年価格を基準とした\n2019年相対価格(対数)', fontsize=15)
pass
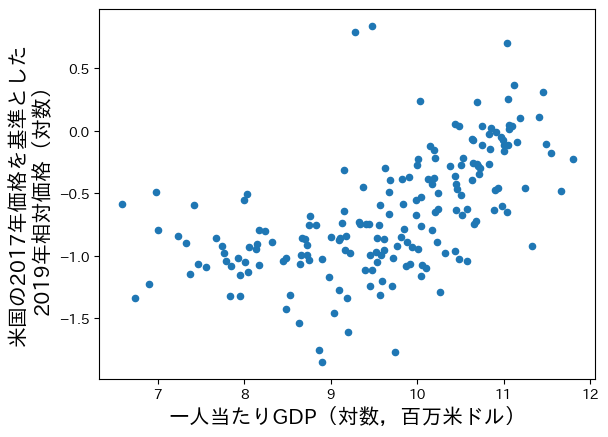
直線トレンドを想像してみよう。明らかに右上がりであり,所得が高い経済ほど物価水準が高いことが確認できる。これはバラッサ・サミュエルソン効果と呼ばれる。直感的には,所得が高い経済の生産性と価格は高く,多くが貿易財である。一方,所得が低い国の非貿易財(例えば,不動産)やサービス(例えば,散髪)は比較的に安い。右上がりの直線トレンドはそれらの反映と考えられる。
しかし,非線形のトレンドを想像するとどうだろう。U字のトレンドを描くことができないだろうか。所得が高い経済では右上がりとなるが,所得が低い経済では逆に緩やかな右下がりとなり,U字の底が一人当たりGDP(対数)が8.8辺りだろうか。この場合,バラッサ・サミュエルソン効果は所得が比較的高い経済では強く現れるが,所得が低い経済では弱いと解釈できる。
このような非線形の相関を考慮して,次節では所得の効果の推定をおこなうことにする。
所得効果の分離#
ここで考える問題は
所得効果を他の影響からどのように分離することができるだろうか。
所得効果は価格の散らばりの何%を説明できるだろうか。
ここでは,まず問題1について考える。相対価格の決定要因は次式に従って分解できると仮定しよう。
\(p_i\equiv\dfrac{P_{i}/e_i}{P_{\text{US}}}\):相対価格
\(D_i^{\text{所得}}\):所得効果の部分
\(D_i^{\text{その他}}\):所得以外の要因によって決まる部分
2つの項については次の仮定を置く。
\(x_i=\dfrac{i\text{国の一人当たりGDP(米ドル)}}{\text{米国の一人当たりGDP(米ドル)}}\)
\(b\):所得効果の強さを捉えるパラメーター
\(c\):所得効果の非線形の効果を捉えるパラメーター
\(a\):その他の要因によって決定される定数
\(u_i\):その他のランダムな要因(誤差項)
(注意) \(D_i^{\text{所得}}\)の右辺にある\(x_i\)の指数は\(b+c\log(x_i)\)となっているが,\(c\log(x_i)\)が上述のU字型の相関関係を捉える項となる。
式(80)に対数を取ると次式となる。
\(d_i^{\text{所得}}\equiv\log\left(D_i^{\text{所得}}\right) =\left[b+c\log\left(x_i\right)\right]\log\left(x_i\right) =b\log(x_i)+c\left[\log\left(x_i\right)\right]^2\)
\(d_i^{\text{その他}}\equiv\log\left(D_i^{\text{その他}}\right)=a+u_i\)
式(82)を回帰式として次のようにまとめることができる。
式(83)をOLS推定し,\(\hat{a}\),\(\hat{b}\),\(\hat{c}\)をパラメーターの推定値,\(\hat{u}_i\)を残差とすると,次式が成立する。
これらの推定値を使い,次のように\(\log\left(p_i\right)\)を2つの要因にに分解することができる。
ここで
\(\hat{d}_i^{\text{所得}}=\hat{b}\log\left(x_i\right)+\hat{c}\left[\log\left(x_i\right)\right]^2\)
\(\hat{d}_i^{\text{その他}}=\hat{a}+\hat{u}_i\)
以下では\(\hat{d}_i^{\text{所得}}\)と\(\hat{d}_i^{\text{その他}}\)を計算し,それぞれの要因によって発生する相対価格の対数\(\log\left(p_i\right)\)のばらつき具合(具体的には,分散)を確認することにする。
Note
なぜ\(\hat{a}\)は\(\hat{D}_i^{\text{その他}}\)に含まれるか考えてみよう。式(83)の代わりに次の定数項のみの推定式を使って\(a\)を推定したとしよう。
Pythonで学ぶ計量経済学で説明しているように,この場合の推定値\(\overline{a}\)は\(\log\left(y_i\right)\)の平均と等しい。ここで重要な点は,\(\overline{a}\)は所得効果を含んだ\(y_i\)の平均値だということである。一方,推定式(83)には\(x_i\)が入っているため,定数項の推定値\(\hat{a}\)は,所得効果を取り除いた後の\(y_i\)の平均値という解釈が成り立つ。この考え方に従うと,\(\log\left(y_i\right)\)の平均値\(\overline{a}\)は次の2つに分解することができる。
\(\overline{a}-\hat{a}\):\(y_i\)の平均値における所得効果の部分
\(\hat{a}\):\(y_i\)の平均値におけるその他の部分
この解釈に基づき,\(\hat{a}\)は\(\hat{D}_i^{\text{その他}}\)に含めている。
推定#
OLSを使って式(83)を推定するが,まず\(\log\left(x_i\right)\)と\([\log\left(x_i\right)]^2\)の変数に使う値を作成する。
cond = ( df['countrycode']=='USA' )
df['cgdpo_pc_ratio_log'] = ( df['cgdpo_pc_log'] -
df.loc[cond,'cgdpo_pc_log'].iloc[0] )
df['cgdpo_pc_ratio_log_2'] = df['cgdpo_pc_ratio_log']**2
この2変数を使い回帰式を推定する。
formula = 'pl_gdpo_log ~ cgdpo_pc_ratio_log + cgdpo_pc_ratio_log_2'
res = smf.ols(formula, data=df).fit()
print(res.summary(slim=True))
OLS Regression Results
==============================================================================
Dep. Variable: pl_gdpo_log R-squared: 0.405
Model: OLS Adj. R-squared: 0.398
No. Observations: 184 F-statistic: 61.60
Covariance Type: nonrobust Prob (F-statistic): 3.93e-21
========================================================================================
coef std err t P>|t| [0.025 0.975]
----------------------------------------------------------------------------------------
Intercept -0.1137 0.059 -1.922 0.056 -0.230 0.003
cgdpo_pc_ratio_log 0.5668 0.072 7.908 0.000 0.425 0.708
cgdpo_pc_ratio_log_2 0.0887 0.018 4.876 0.000 0.053 0.125
========================================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
\(\hat{b}\)と\(\hat{c}\)の統計的な優位性は非常に高い。また\(\hat{c}>0\)はU字型のトレンドを示している。
データの散布図に回帰線を重ねて表示して当てはまり具合を視覚的に確認してみることにしよう。式(80)から予測値は
となる。この式を使い,予測値の値を新たな列としてdfに追加しよう。
# パラメーターの推定値
ahat = res.params.iloc[0]
bhat = res.params.iloc[1]
chat = res.params.iloc[2]
# 予測値
df['fitted'] = ( ahat+
bhat*df['cgdpo_pc_ratio_log']+
chat*df['cgdpo_pc_ratio_log_2']
)
プロットしてみよう。
# 散布図
ax = df.plot.scatter(x='cgdpo_pc_ratio_log', y='pl_gdpo_log')
ax.set_xlabel('米国を基準とした一人当たりGDP(対数,2019年)', fontsize=15)
ax.set_ylabel('米国の2017年価格を基準とした\n2019年相対価格(対数)', fontsize=15)
# 回帰曲線
df.sort_values('cgdpo_pc_ratio_log').plot(x='cgdpo_pc_ratio_log', #1
y='fitted',
color='red',
ax=ax)
pass
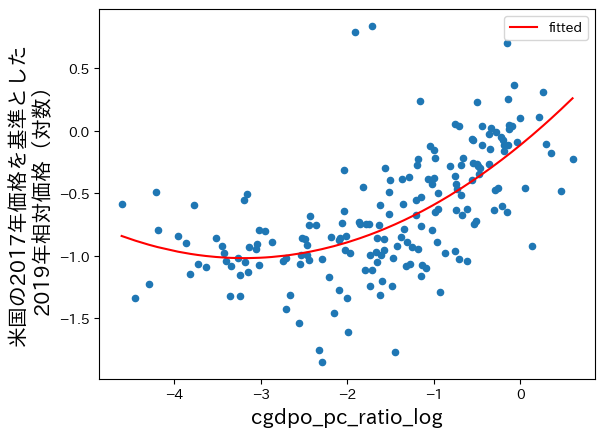
コードの説明
#1のdf.sort_values('cgdpo_pc_ratio_log'))は,列cgdpo_pc_ratio_logの値に従ってdfを昇順に並び替えている。これによりスムーズな回帰曲線を表示できるようになる。並び替えないとどうなるか試してみよう。
ヒストグラムの比較#
式(85)にある3つの項\(\log\left(p_i\right)\),\(\hat{d}_i^{\text{所得}}\),\(\hat{d}_i^{\text{その他}}\)のヒストグラムを比較してみよう。まず,\(\hat{d}_i^{\text{所得}}\)と\(\hat{d}_i^{\text{その他}}\)の定義に基づいてdfに新たな列を作成しよう。
# 所得の影響
df['income_effect'] = ( bhat * df['cgdpo_pc_ratio_log']+
chat * df['cgdpo_pc_ratio_log_2']
)
# 所得以外の効果
df['other_effect'] = ahat + res.resid
3つの変数のヒストグラムを並べて表示する。
col_lst = ['pl_gdpo_log','income_effect','other_effect']
title_lst = ['相対価格(対数)','所得効果(対数)','その他の効果(対数)']
ax = df[col_lst].plot.hist(bins=20,
ec='white',
subplots=True,
legend=False,
figsize=(6,10))
for i, s in enumerate(title_lst):
ax[i].set_title(s, fontsize=18)
ax[i].axvline(0, color='k', linestyle=':')
pass
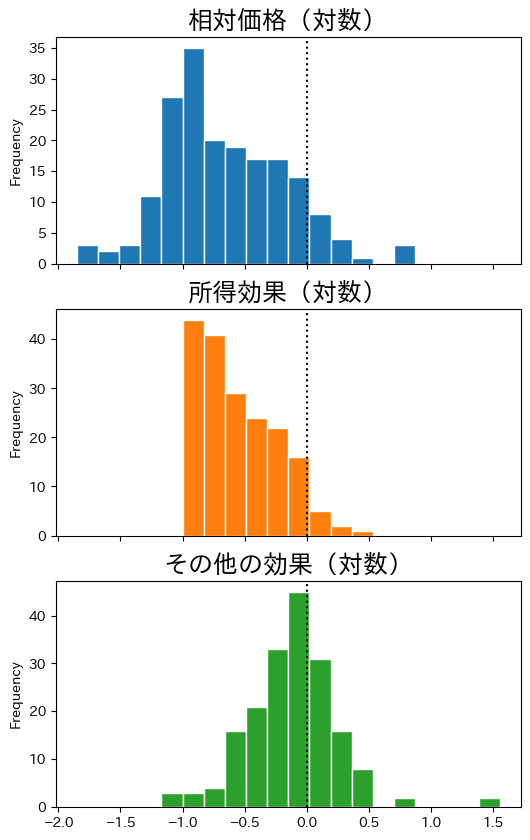
0.0(縦の点線)で\(\dfrac{P_i/e_i}{P_{\text{US}}}=1\)となることに注意しよう。次のことが言える。
所得とその他の効果を足し合わせることで一番上の相対価格の分布となる。言い換えると,相対価格の分布から所得効果を取り除くことにより一番下のその他の効果となる。
所得効果の分布の最頻値は負の値となっており,米国の物価水準より低い経済において所得効果が大きいということを意味する。
その他の効果は
0.0を中心に分布している。若干,相対価格が低い階級に国の数が多いように見える。
所得効果の大きさ#
ここでは次の問いを考察する。
相対価格のばらつきの何割が所得効果に起因するのだろうか。
\(y_i=\log\left(p_i\right)\)として式(80)を再掲する。
この式の両辺の分散を次のように計算することにより,所得効果の割合を計算することが可能となる。まず,\(p_i\)の分散を\(d_i^{\text{所得}}\)と\(d_i^{\text{その他}}\)の分散に分解しよう。
上の計算では,\(d_i^{\text{所得}}\)と\(d_i^{\text{その他}}\)の共分散が存在するため,それを所得とその他に等分している。
更に,この結果を次のように書き直すことができる(「回帰分析」の章を参照)。
この式に従って計算してみよう。
# 所得効果の割合
income = df[['pl_gdpo_log','income_effect']]
print(
income.cov().iloc[0,1] / income.cov().iloc[0,0]
)
0.4049924405126257
# 所得以外の効果の割合
other = df[['pl_gdpo_log','other_effect']]
print(
other.cov().iloc[0,1] / other.cov().iloc[0,0]
)
0.5950075594873743
分散の割合で考えた場合,所得効果は全体の約40%を占めている。一般物価水準の一物一価が成立しない大きな理由が所得の差ということが明らかになった。一方で,所得以外の要因も大きな影響を及ぼしている。「その他」の要因は大きく2つに分けることができる。
財・サービスの貿易(国際収支における貿易・サービス収支に該当)
国境をまたぐ国際貿易での輸送費用は非常に大きく,一物一価の大きな妨げとなっている。
Big Macのように非貿易財(例えば,教育,建設,不動産,政府サービス)も存在する。輸送費用は著しく大きいため,貿易されない財と考えることができる。非貿易財の存在は経済間の一物一価の妨げとなっている。
一般物価水準を説明する上でバスケット財という合成財を考えた。しかし,全ての国で全く同じ財がある訳ではない。また,一般物価水準を計算する上で,各国の支出データを使いウェイトを算出し加重平均を計算することになるが,経済によって支出割合は異なるためウェイトも異なることになる。
経済間の金融取引(国際収支における金融収支などに該当)
経済間では財・サービスだけではなく金融資本の取引がおこなわれる。例えば,直接投資,証券投資,金融派生商品などである。長期的な投資だけではなく,短期的な投資や投機も含まれるため,資金が瞬時に動くことになり市場為替レートが大きな影響を受けることになる。
Note
式(88)は次のように書き直すことも可能である。
回帰分析の結果が含まれるresを使って確認してみよう。
res.rsquared
上で計算した所得効果の割合と等しいことが確認できるはずだ。
所得効果の含意#
PPPレートと市場為替レート:再考#
上の分析で一般物価水準が経済によって大きく異なることを示すために,式(79)を使った。その式を式(76)と(72)を使って次のように表すことができる。
即ち,相対一般物価水準はPPPレートと市場為替レートに分解することができるということであり,経済間での相対一般物価水準の違いは,PPPレートと市場為替レートの乖離として現れるということである。この点を踏まえると,次のことが分かる。
pl_gdpo\(=1\):\(\varepsilon_{i}=e_{i}\)\(i\)国の物価水準は米国と同じ場合,PPPレートと市場為替レートは同じ。
pl_gdpo\(>1\):\(\varepsilon_{i}>e_{i}\)\(i\)国の物価水準は米国よりも高い場合,PPPレートと比較して\(i\)国の通貨は強すぎる。
pl_gdpo\(<1\):\(\varepsilon_{i}<e_{i}\)\(i\)国の物価水準は米国よりも低い場合,PPPレートと比較して\(i\)国の通貨は弱すぎる。
更に,相対一般物価水準の違いは所得水準の違いに大きな影響を受けることが明らかになったが,式(91)によると,所得効果はPPPレートと市場為替レートの乖離にも大きな影響を与えることが分かる。次のようにまとめることができる。
所得が高い経済の通貨は強く,所得が低い経済の通貨は弱い傾向となっている。
ペン効果#
PPPレートと市場為替レートの乖離は所得水準に影響されることが明らかになったが,その経済学的な含意は次のようにまとめることができる。
市場為替レートを使いGDPを評価すると,貧しい国の貧しさは誇張される。
これはペン効果と呼ばれる。英語ではPenn Effectと呼ばれ,Pennは本章で使ったデータセットPenn World TableのPennから来ている。
ペン効果を簡単な数値例で説明するために,Big Macだけを生産する2国を考えてみよう。A国は豊かな経済であり,B国は貧しい経済としよう。A国は年間\(Y_A=10\)個のBig Mac,B国は\(Y_B=5\)個のBig Macを生産している。A国の貨幣単位は\(\$_A\)であり,B国の貨幣は\(\$_B\)とし,価格は\(P_A=\$_A10\),\(P_B=\$_B10\)としよう。それぞれの自国通貨で評価すると,A国のGDPは\(10\times\$_A10=\$_A100\)であり,A国のGDPは\(5\times\$_B10=\$_B50\)である。
この場合,PPPレートは
となる。まず,一物一価が成立したとしよう。この場合,市場為替レートを\(e_{B/A}\)(単位:\(\$_B/\$_A\))とすると,\(\varepsilon_{B/A}=e_{B/A}=1\)が成立することになり,A国の通貨\(\$_A\)で表した相対価格は
となる。購買力平価が成立する場合のGDPの比率は次のようになる。
B国のGDPはA国の半分ということだ。
次に,ペン効果を導入する。所得の影響により為替レートは\(e_{B/A}=2\)と仮定しよう。即ち,B国は比較的に貧しいため,B国の通貨は弱いという仮定である。この場合,A国の通貨\(\$_A\)で表した相対価格は
となり,A国の価格がB国よりも高く一物一価は成立しない。上述のデータと合致したパターン(豊かな国の価格が高い)となっている。相対的なGDPを計算してみよう。
B国のGDPはA国の25%しかない。所得効果がない購買力平価が成立する場合の50%と対照的であり,ペン効果により所得格差が誇張されている。
一人当たりGDPの分布#
上の数値例をデータを使って確認してみよう。ここではdfを使い,PPPレートで計算された一人当たりGDPと市場為替レートに基づいた一人当たりGDPを計算し比較する。
変数cgdpo_pcはPPPレートで計算した一人当たりGDP(2017年米ドル)である。具体的に説明するために,次の変数を定義しよう。
\(Y_i\):\(i\)国の産出量
\(P_i\):\(i\)国の貨幣表示の物価水準
\(L_i\):\(i\)国の人口
\(\varepsilon_i\):1米ドル当たりの\(i\)国のPPPレート
cgdpo_pcは次のように計算されている。
dfに市場為替レートのGDPを新たな列cgdpo_pc_xrとして追加するとしよう。cgdpo_pcを使うと次の計算となる。
列cgdpo_pc_xrを追加する。
df['cgdpo_pc_xr'] = df['cgdpo_pc'] * df['ppp'] / df['xr']
対数値も作成しておこう。
df['cgdpo_pc_xr_log'] = np.log( df['cgdpo_pc_xr'] )
まず散布図を使ってペン効果を確かめてみる。
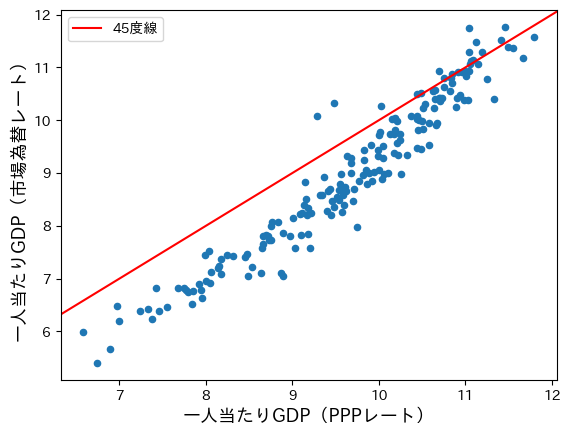
ax = df.plot.scatter(x='cgdpo_pc_log', y='cgdpo_pc_xr_log')
ax.axline((9, 9), (10, 10), color='red', label='45度線') #1
ax.set_xlabel('一人当たりGDP(PPPレート)', fontsize=13)
ax.set_ylabel('一人当たりGDP(市場為替レート)', fontsize=13)
ax.legend()
pass
コードの説明
#1:.axline()は直線を表示するメソッドであり,引数で指定された座標2つを通過する直線がプロットされる。(9,9)は横軸9と縦軸9の座標であり,(10,10)は横軸10と縦軸10の座標となる。
横軸はPPPレートで計算した一人当たりGDPであり,縦軸には市場為替レートに基づく一人当たりGDPとなっている。それぞれのレートで計算した一人当たりGDPが等しければ45度線(赤線)上に観測値は並んでいるはずである。しかし,観測値は45度線よりも下に位置する傾向があり,特に所得が低い経済においては顕著である。即ち,市場為替レートを使い計算した一人当たりGDPは低く算出される傾向にあり,所得が低い経済においてその傾向は強い。
一人当たりGDPの分布を図示するためにカーネル密度推定をプロットしよう。(直感的には,カーネル密度推定とはヒストグラムの情報を使い,そのサンプルを生成した連続的な分布を推定する方法と考えれば良いだろう。)
ax = df.plot.kde(y=['cgdpo_pc_log','cgdpo_pc_xr_log'])
ax.legend(['PPPレート','市場為替レート'], fontsize=13)
ax.set_title('一人当たりGDP(米ドル,対数)', fontsize=20)
pass
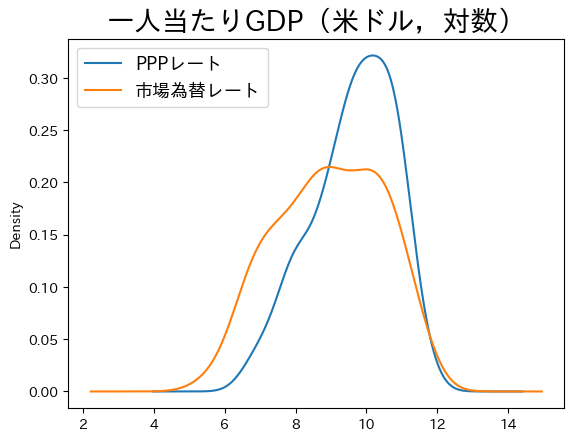
PPPレートGDPと比べて市場為替レートGDPは全体的に左(小さい値)にシフトしている。所得が中程度の国が減少し,所得が低い国が増加している。
記述統計を比べてみよう。
#1
stats_ppp = df['cgdpo_pc_log'].describe().to_frame('PPPレートGDP')
stats_xr = df['cgdpo_pc_xr_log'].describe().to_frame('市場為替レートGDP')
pd.concat([stats_xr,stats_ppp], axis='columns') #2
| 市場為替レートGDP | PPPレートGDP | |
|---|---|---|
| count | 184.000000 | 184.000000 |
| mean | 8.966500 | 9.630805 |
| std | 1.489969 | 1.161306 |
| min | 5.404184 | 6.583673 |
| 25% | 7.809507 | 8.860137 |
| 50% | 8.992879 | 9.789785 |
| 75% | 10.242803 | 10.542301 |
| max | 11.767071 | 11.796463 |
コードの説明
#1:.describe()は記述統計をSeriesとして返すメソッド。to_frame('PPPレートGDP')はSeriesをDataFrameに変換するメソッドであり,引数’PPPレートGDP’を列ラベルに使う。#2:pd.concat()はPandasのDataFrameを結合する関数。引数
[stats_xr,stats_ppp]は結合するDataFrameをリストとして指定する。axis='columns'は各DataFrameを列として結合することを指定している。(注意)
pd.concat()は行ラベルが合っているかはチェックしない。上のコードでは,行ラベルが同じだと分かっているので問題ないが,行ラベルが異なるDataFrameを結合する場合はpd.merge()を使うことを勧める。
上の結果をまとめると次のようになる。市場為替レートを使うことにより,
GDPの平均,最小値,25%分位数,中央値,75%分位数は減少している。
GDPの標準偏差と最大値は増加している。
これらは市場為替レートにより経済間の不平等が大きく計測されていることを示唆する。不平等の一つに変動係数(Coefficient of Variation)があるが(式(58)を参照),それを使って比較してみよ。
変動係数が大きければ,所得不平等は大きいことを意味する。
cc_ppp = df['cgdpo_pc_log'].std() / df['cgdpo_pc_log'].mean()
cc_xr = df['cgdpo_pc_xr_log'].std() / df['cgdpo_pc_xr_log'].mean()
print('--- GDPの変動係数 ---')
print(f'PPPレート:{cc_ppp:>8.3f}')
print(f'市場為替レート:{cc_xr:.3f}')
--- GDPの変動係数 ---
PPPレート: 0.121
市場為替レート:0.166
市場為替レートに含まれる所得の影響がペン効果として現れていることが確認できる。
まとめ#
国内市場で財・サービスの一物一価は成立していない。
経済間でBig Macの価格の一物一価は成立していない。
経済間で一般物価水準は異なる。
購買力平価レートは2つの通貨の購買力を等しくする交換レート。
所得が高い(低い)経済の一般物価水準は高い(低い)傾向にある(所得効果)。
所得効果により,所得が低い経済の通貨は購買力平価レートと比べて弱い傾向にある。
市場為替レートを使い共通通貨で一人当たりGDPを比較すると,所得が低い経済の貧しさは誇張される。