ランダム変数と全要素生産性#
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
import japanize_matplotlib
import py4macro
# numpy v1の表示を使用
np.set_printoptions(legacy='1.21')
# 警告メッセージを非表示
import warnings
warnings.filterwarnings("ignore")
はじめに#
この章の目的は2つある。 第一に,マクロ経済分析におけるランダム変数の役割と変数の持続性について考える。 第二に,景気循環を理解する上で全要素生産性の役割が強調される研究があるが,その導入として全要素生産性の特徴について検討する。またソロー・モデルを使い,全要素生産性が確率的に変動する簡単な景気循環モデルのシミュレーションを通してマクロ変数の特徴を考察する。
ランダム変数の役割#
# データの読み込み
df = py4macro.data('jpn-q')
# トレンドからの%乖離のデータの作成
df['gdp_cycle'] = 100 * (
np.log( df['gdp'] ) - py4macro.trend( np.log(df['gdp']) )
)
# プロット
ax = df.plot(y='gdp_cycle', title='GDPのトレンドからの乖離(%)')
ax.axhline(0, c='red')
pass
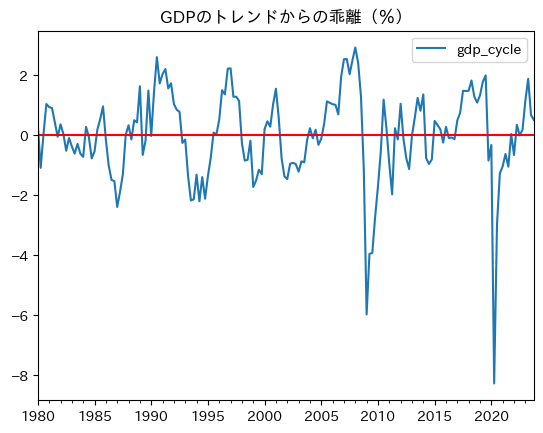
このようなGDPの変動を説明する方法として2つある。
決定的(deterministic)な過程で生成された時系列として捉える。
ランダム(stochastic)な過程で生成された時系列として捉える。
1の考えによると,差分方程式\(x_{t+1}=f(x_t)\)のように来期のGDPは今期のGDPに依存している。マクロ変数の持続性を捉えるには必要不可欠な特徴と言えるだろう。しかし,今期のGDP(\(x_t\))が与えられると来期のGDP(\(x_{t+1}\))は自ずと決定さることになり,来期のGDPの予測は簡単なものとなる。もしそうであれば政策運営は非常に簡単であろうが,現実はそうではない。そういう意味では,1は現実を十分に捉えることができていない。
一方,2の考えはランダム変数の実現値の連続としてGDPが観測され,今期のGDPが与えられても来期のGDPにはランダムな要素があるため,予測が難しいという特徴がある。この特徴こそが,マクロ変数の性質を捉えるには必要な要素であり,上のプロットに現れていると考えられる。主流のマクロ経済学では,消費者や企業の行動はフォーワード・ルッキングであり(将来を見据えた最適化行動であり),且つ経済全体ではランダムな(不確実な)要素が重要な役割を果たしているという考え基づいている。そのような分析枠組みの中で,景気循環のメカニズムを解明することが目的となっている。
以下では,まず,マクロ変数を捉えるにはどのようなランダム変数生成過程が妥当かを検討する。 次に、短期分析における全要素生産性の役割について説明する。またSolowモデルを使い簡単な景気循環モデルを展開する。
ホワイト・ノイズ#
説明#
時系列のランダム変数\(\varepsilon_t\),\(t=0,1,2,3,\cdots\)を考えよう。例えば,レストランの経営者の収入。ビジネスにはリスク(競争相手の出現やコロナ感染症問題)があるため変動すると考えるのが自然である。\(\varepsilon_t\)は\(t\)毎にある分布から抽出されると考えることができる。次の3つの性質を満たしたランダム変数をホワイト・ノイズ(White Noise)と呼ぶ。
平均は
0:\(\quad\text{E}\left[\varepsilon_t\right]=0\)分散は一定:\(\text{ E}\left[\varepsilon_t^2\right]=\sigma^2\)(\(\sigma^2\)に\(t\)の添字はない)
自己共分散(自己相関)は
0:\(\text{ E}\left[\varepsilon_t \varepsilon_{t-s}\right]=0\)(全ての\(s\ne 0\)に対して)。
<コメント>
平均
0と分散が\(\sigma^2\)のホワイト・ノイズを次のように表記する。\[ \varepsilon_t\sim\textit{WN}(0,\sigma^2) \]ホワイト・ノイズの例:
平均
0,分散\(\sigma^2\)の正規分布から抽出された\(\varepsilon_t\)最小値
10,最大値100からからランダム抽出された\(\varepsilon_t\)
正規分布や一様分布ではない分布でもホワイト・ノイズになる。
ホワイト・ノイズは独立同分布(Indepent and Identically Distributed)の1つである。
平均と分散#
以下では実際にランダム変数を発生させ,そのプロットと統計的な特徴について考察する。まず,平均と分散について確認するために,その準備として次のコードを実行しよう。
rng = np.random.default_rng()
rngはランダム変数を生成する「種」となるオブジェクトとして理解すれば良いだろう。
正規分布を生成する構文は次のようになる。
rng.normal(loc=0, scale=1, size=1)
loc:平均(デフォルトは0)
scale:標準偏差(デフォルトは1)
size:ランダム変数の数(デフォルトは1)
ここで、.normal()はrngのメソッドである。例として、平均5,標準偏差2の標準正規分布から10のランダム変数を生成しよう。
rng.normal(5, 2, 10)
array([4.89948968, 3.93552861, 4.47004945, 5.24012765, 6.93666361,
6.00112561, 4.99168641, 2.87226522, 2.82300823, 6.98596606])
Note
NumPyを使いランダム変数を生成する方法については,「経済学のためのPython入門」のNumpy: ランダム変数を参考にしてください。
では、標準正規分布からのランダム変数をn個抽出しプロットしてみよう。
n = 100
vals = rng.normal(size=n)
dfwn = pd.DataFrame({'WN':vals})
dfwn.plot(marker='.')
pass
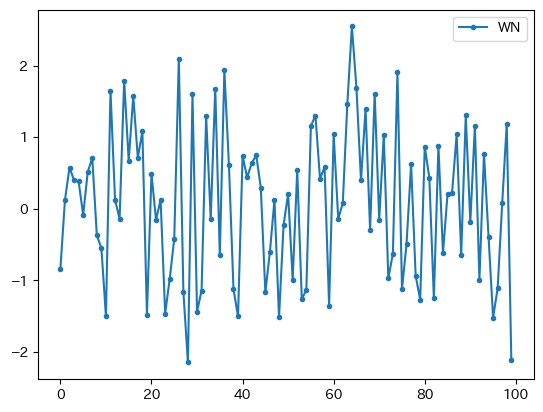
2つの特徴がある。
平均
0:0を中心に周辺を動いている。分散一定:
0から外れても0に戻っている。標準正規分布の場合、-2から2の間の値を取る確率が約95%になる性質からも理解できるだろう。
平均と分散を計算してみよう。
dfwn['WN'].mean(), dfwn['WN'].var()
(0.08723266527413064, 1.1309348641300627)
標準正規分布の母集団からのサンプル統計量であるため誤差が発生していることがわかる。
2つの特徴をを確認するためにPandasのplot()を使ってヒストグラムを描いてみよう。
dfwn.plot.hist(bins=30)
pass
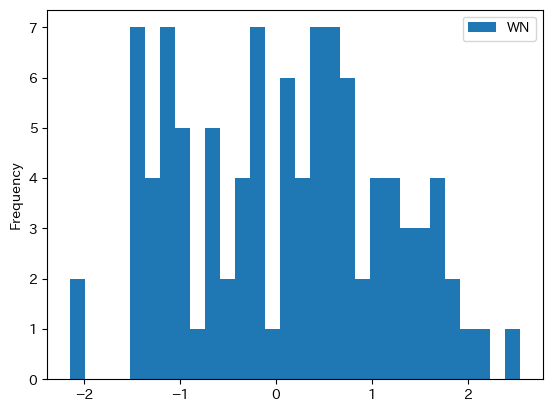
概ね0を中心に左右対象に動いている。即ち,平均0を反映している。また,0から離れている観測値が少ないことが分かる。これは0方向に戻ることを示しており,分散が一定となるためである。この性質はnを500や1000などの大きな数字に設定するより一層分かりやすいだろう。
自己共分散(自己相関)#
1期違いの自己共分散\(\sigma_{\varepsilon_t \varepsilon_{t-1}}\)を計算するために,dfwnの列WNを1期シフトさせた新たな列WNlagを作成しよう。
dfwn['WNlag'] = dfwn['WN'].shift()
dfwn.head()
| WN | WNlag | |
|---|---|---|
| 0 | -0.842237 | NaN |
| 1 | 0.120422 | -0.842237 |
| 2 | 0.575122 | 0.120422 |
| 3 | 0.396047 | 0.575122 |
| 4 | 0.382509 | 0.396047 |
WNlagの値はWNの値が1期シフトしていることが分かる。
0番目の行のWNが初期値であり、同じ値が1番目の行のWNlagに入っている。
即ち、1番目の行を見るとWNには1期の値、、WNlagには初期(0期)の値がある。
同様に、各行のWNにはt期の値、WNにt-1期の値が入っている。
この2つの列を使って散布図を描いてみる。Pandasのplot()で横軸・縦軸を指定し,引数kindで散布図を指定するだけである。
dfwn.plot.scatter(x='WNlag', y='WN')
pass
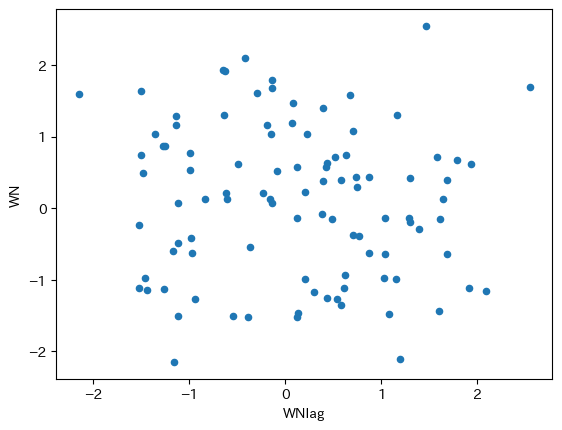
自己共分散がゼロであれば,ランダムに散らばっているはずであり,何らかのパターンも確認できないはずである。
ここで異なるプロットの方法を紹介する。Pandasのサブパッケージplottingにあるlag_plot()関数を使うと共分散の強さを示す図を簡単に作成することが可能となる。
必須の引数:1つの列
オプションの引数:
lagは時間ラグ(デフォルトは1)
pd.plotting.lag_plot(dfwn['WN'])
pass
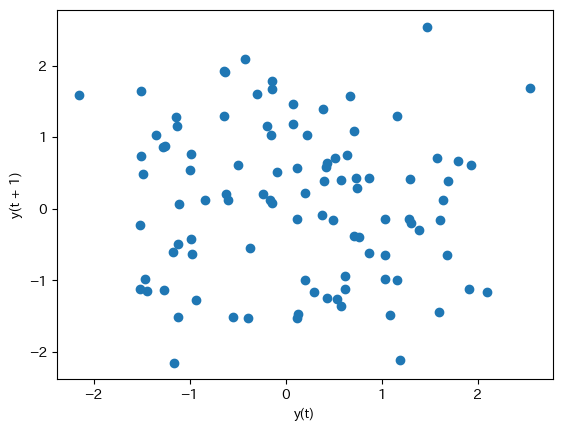
横軸:
t期の値縦軸:
t+1期の値
2つの図は同じであることが確認できる。
分散・自己共分散を計算してみよう。
dfwn.cov()
| WN | WNlag | |
|---|---|---|
| WN | 1.130935 | -0.086535 |
| WNlag | -0.086535 | 1.092725 |
左上と右下の対角線上にあるのは、WNとWNlagの不偏分散であり、1に近い値となっている。両変数は標準正規分布(分散1)から生成したためであり、1にならないのはサンプルの誤差である。(WNとWNlagの不偏分散は異なるが、その理由は?)一方、右上と左下の値(同じ値となる)が自己共分散であり、非常に小さな値であるが、自己共分散は0という仮定を反映している。
dfwn.cov()を使って自己相関係数を計算することができるが、一点注意する必要がある。dfwnの0行目には欠損値があるため、自己共分散を計算する際にその行は使われていない。同様に、自己相関係数を計算する際は欠損値がある行を使わずに計算する必要がある。この点に注意して、次のコードで計算することができる。
varcov = dfwn.dropna().cov()
varcov.iloc[0,1] / ( varcov.iloc[0,0]**0.5 * varcov.iloc[1,1]**0.5 )
-0.07775171668251629
メソッド.corr()を使っても同じ結果を得ることができる。
dfwn.corr()
| WN | WNlag | |
|---|---|---|
| WN | 1.000000 | -0.077752 |
| WNlag | -0.077752 | 1.000000 |
また、dfwon['WN']のメソッドautocorr()を使い、直接自己相関係数を計算することも可能である。
dfwn['WN'].autocorr()
-0.07775171668251629
まとめ#
GDPや構成要素を含め、マクロ変数の重要な特徴が持続性であることは既に確認済みだ。(自己共分散(自己相関)を参照しよう。)従って,上の結果からわかることは,自己共分散が0であるホワイト・ノイズだけではマクロ変数の持続性を説明できないということであり、景気循環を理解するためには自己共分散が正の値になる経済モデルが求められる。では、どのようなモデルなのだろうか?この問いに答えるために、まずは統計的なモデルである自己回帰モデルを考察し、それを出発点として議論を進めていく事にする。
自己回帰モデル:AR(1)#
説明#
ここでは持続性を捉える確率過程である自己回帰モデルを考える。英語でAugoregressive Modelと呼ばれ,AR(1)と表記され,次式で表される。(AR(1)の(1)は右辺と左辺の変数は1期しか違わないことを表している。)
ここで
\(y_t\):\(t\)期の\(y\)の値
\(-1<\rho<1\)
\(\varepsilon_t\sim WN(0,\sigma^2)\)(ホワイト・ノイズ)
次の特徴がある。第一に、\(\varepsilon_t\)を所与とすると\(y_t\)の差分方程式となっている。\(-1<\rho<1\)となっているため,安定的な過程であることがわかる。即ち,\(\varepsilon_t=0\)であれば、\(y_t\)は定常状態である\(0\)に近づいて行くことになる。しかしホワイト・ノイズである\(\varepsilon_t\)により、毎期確率的なショックが発生し\(y_t\)を定常状態から乖離させることになる。第二に、今期の値\(y_t\)は前期の値\(y_{t-1}\)に依存しており,その依存度はパラメータ\(\rho\)によって決定される。この\(\rho\)こそが\(y_t\)の持続性の強さを決定することになり,自己回帰モデル(145)の自己相関係数は\(\rho\)と等しくなる。即ち、持続性を捉えるためには、\(\rho\ne 0\)が必須である。
ここで考えるAR(1)の特徴をまとめておこう。
\(y_t\)の確率分布が変化しない定常過程
平均は一定:\(\quad\text{E}\left[y_t\right]=0\)
分散は一定:\(\text{E}\left[y_t^2\right]=\dfrac{\sigma^2}{1-\rho^2}\)(\(t\)の添字はない)
自己共分散は一定:\(\text{E}\left[y_t y_{t-s}\right]=\sigma_{y_t y_{t-s}}^2=\rho^s\dfrac{\sigma^2}{1-\rho^2}\)(\(s\ne 0\))。従って,
\[ \text{自己相関関数}(s)=\frac{\sigma_{y_t y_{t-s}}^2} {\sigma_{y_t}\times\sigma_{y_{t-s}}} =\rho^s \]であり,\(s=1\)の自己相関係数は\(\rho\)となる。
3つの例:持続性の違い#
直感的にマクロ変数の特徴である持続性とは,前期の値が今期の値にどれだけ影響を持っているかを示す。\(\rho\)の値を変えて持続性の違いを視覚的に確認するための関数を作成しよう。
def ar1_model(rho, y0=0, T=100):
"""引数:
rho: AR(1)の持続性を捉えるパラメータ
y0: 初期値
T: シミュレーションの回数(デフォルト:0)
戻り値:
matplotlibの図を示す
自己相関係数の値を表示する"""
y = y0 #1
y_lst = [y] #2
for t in range(1,T): #3
e = rng.normal() #4
y = rho*y + e #5
y_lst.append(y) #6
df_ar1 = pd.Series(y_lst) #7
ac = df_ar1.autocorr() #8
ax_ = df_ar1.plot(marker='.') #9
ax_.set_title(fr'$\rho$={rho} 自己相関係数:{ac:.3f}',size=20) #10
ax_.axhline(0, c='red') #11
コードの説明
#1:forループで使うアップデート用のyであり,初期値を割り当てている。#2:yの値を格納するリスト。初期値を入れてある。#3:T期間のforループの開始。変数tは(4)と(5)に入っていないので単にループの回数を数えている。range(1,T)の1はループの計算が\(t=1\)期のyの計算から始まるため。\(t=0\)期のyは(1)で与えられている。
#4:t期のホワイト・ノイズの生成。#5:右辺のeはt期のホワイトノイズであり,y前期のyとなっている。#6:y_listにyを追加。#7:y_listを使ってSeriesを作成しdf_ar1に割り当てる。#8:.autocorr()を使い己相関係数を計算しacに割り当てる。#9:yのプロットmarker='.'はデータのマーカーを点に設定。図の「軸」を
ax_に割り当てる。
#10:図のタイトルの設定frのfはf-stringを表し,{rho}と{ac:.3f}に数値を代入する。:.3fは小数点第三位までの表示を設定frのrは$\rho$をギリシャ文字に変換するためののも。$\rho$はLaTeXのコード。
#11:.axhline()は横線をひくメソッド。
ar1_model(0.1)
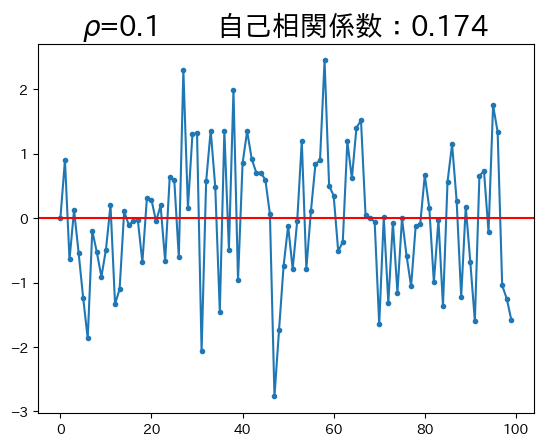
この例では\(\rho\)の値が低いため,\(y\)は定常状態の0に直ぐに戻ろうとする力が強い。従って、前期の値の今期の値に対する影響力が小さいため、持続性が低い。
ar1_model(0.5)
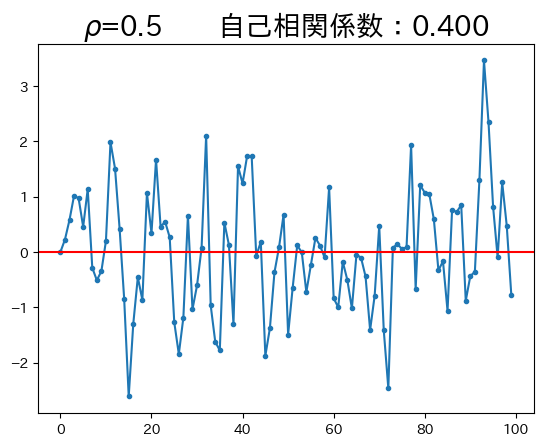
\(\rho\)の値が高くなると、定常状態の\(0\)に戻ろうとする作用が弱くなり、持続性が強くなることがわかる。
ar1_model(0.9)
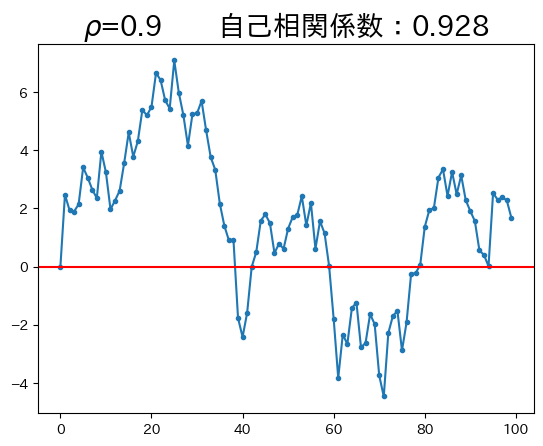
\(\rho\)が非常に高いため、持続性も非常に強くなっている。即ち、今期の値は前期の値に対する依存度が大きい。
全要素生産性#
説明#
マクロ変数の特徴を捉えるにはホワイト・ノイズよりもAR(1)の方がより適しているということが分かった。では,どの様な形でAR(1)をマクロ・モデルに導入すれば良いのだろうか。現在盛んに行われている景気循環研究はDSGEモデル(Dynamic Stochastic General Equilibrium Model)と呼ばれるモデルに基づいており、DSGEは名前が示すように次のような特徴がある。
時間軸に沿ってマクロ変数の変化を考察する動学的な特徴
確率的な要因の重要な役割
合理的期待に基づく将来を見据えた消費者と企業の最適行動
一般均衡のモデル
そして,DSGE研究の先駆けとなったモデルが実物的景気循環モデル(Real Business Cycles Model; RBCモデル)と呼ばれる理論である。詳細については後の章に譲るが,基本的なアイデアは簡単で全要素生産性(TFP)がAR(1)に従って確率的に変動し,それが消費者と企業の経済行動に影響することにより景気循環が発生するという理論である。ここではデータを使い全要素生産性の性質を考察する。RBCモデルで需要な役割を果たす労働時間についてもデータを使い特徴を探ることにする。
データ#
次の生産関数を仮定する。
\(Y_t\):GDP
\(K_t\):資本ストック
\(H_t\):総労働時間(労働者数\(\times\)労働者平均労働時間)
\(A_t\):TFP
TFPについて解くと次式を得る。
景気循環を考えているため、TFPを計算する際には次の点を考慮することが望ましい。
年次データではなく四半期データを使う(年次データでは短期的な変動を捉えることができない)。
\(H_t\)は労働者数ではなく,総労働時間とする(短期的な労働供給の変化を捉えるため)。
\(K_t\)は資本ストックの稼働率を考慮したデータとする(短期的に実際に生産に使われた資本ストックの変化を捉えるため)。
ここでは1と2のみを考慮したデータを使いTFPの変動を考えることにする。これにより資本ストックの稼働率はTFPの一部となってしまうが,RBCモデルの基本的なアイデアは変わらない。
上で読み込んだデータdfには次の変数が含まれている(詳細はGDP:水準・トレンド・変動を参照)。
期間:1980年Q1〜2021年Q4
gdp:国内総生産(支出側)capital:資本ストックemployed:就業者hours:労働者1人あたり月平均就業時間(以下では「平均労働時間」と呼ぶ)total_hours:総労働時間(hours\(\times\)employed)
労働時間と雇用の特徴#
平均労働時間hours,就業者数employed,総労働時間total_hoursの特徴を考えてみる。まずサイクルを計算するが、次の点に留意し計算方法が異なる。
hoursは上限があり、長期間持続的に上昇もしくは減少しない。employedは長期間持続的に上昇もしくは減少することは可能な変数。total_hoursは、hoursとemployedの掛け算となっているため、長期間持続的に上昇もしくは減少することは可能な変数。
df['hours_trend'] = py4macro.trend(df['hours'])
df['hours_cycle'] = 100 * np.log( df['hours']/df['hours_trend'] )
df['employed_trend_log'] = py4macro.trend( np.log(df['employed']) )
df['employed_cycle'] = 100 * ( np.log( df['employed'] ) - df['employed_trend_log'] )
df['total_hours_trend_log'] = py4macro.trend( np.log(df['total_hours']) )
df['total_hours_cycle'] = 100 * ( np.log( df['total_hours'] ) - df['total_hours_trend_log'] )
最初に,平均労働時間を考えよう。
df.plot(y=['hours','hours_trend'])
pass
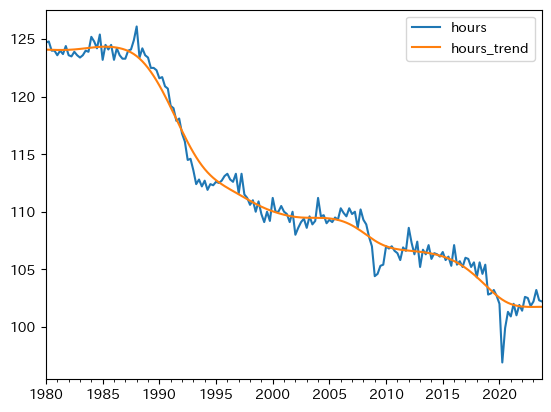
平均労働時間は長期的に減少傾向にある。2020年の平均が100に標準化しているので,1980年代には約25%長かったことを示している。次に,就業者数を図示する。
ax_ = df.plot(y='employed')
np.exp( df['employed_trend_log'] ).plot(ax=ax_)
pass
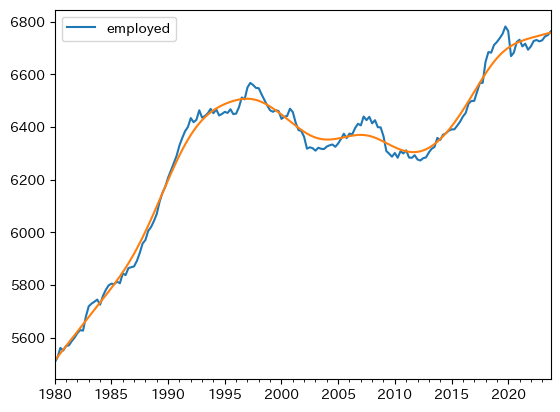
コードの説明
df['employed_trend_log']は、トレンドを対数化した値となる。指数化し元の数値に戻すためにnp.exp()を使っている。また、np.exp(df['employed_trend'])はSeriesを返すことになり、そのメソッドplot()を使って図示している。
一方,雇用者数は増加傾向にある。女性の労働市場参加率の増加や,雇用形態の変化(非正規など)の影響と考えられる。
上の2つの変化を反映したのが総労働時間の変化である。
ax_ = df.plot(y='total_hours')
np.exp( df['total_hours_trend_log'] ).plot(ax=ax_)
pass
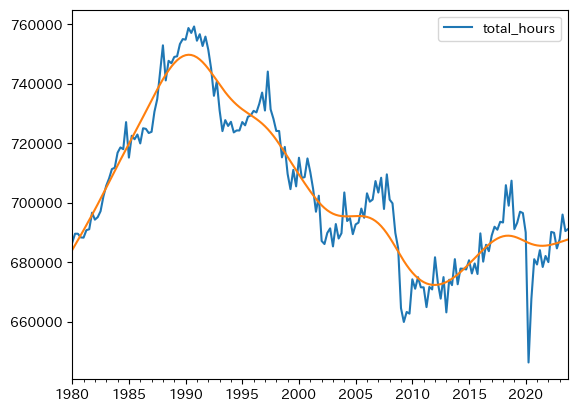
バブル崩壊後は減少傾向にあるが,過去10年間に持ち直して来ている。これは雇用の拡大の要因が大きい。
雇用と労働時間の変動(トレンドからの乖離率)を比べてみよう。
ax_ = df.plot(y=['hours_cycle','employed_cycle'])
ax_.axhline(0, c='red', lw=0.5)
pass
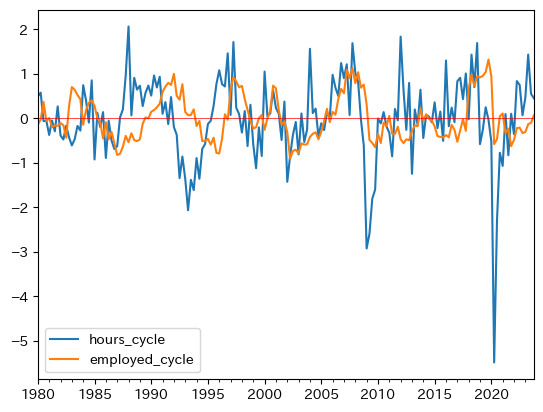
次の2つの点を指摘できる。
労働時間の方が変動が大きい。即ち,総労働時間の調整は就業者数よりも労働時間を通して行われていることが伺える。
就業者数の変化は、労働時間の変化を後追いする傾向がある。これは就業者の調整費用がより高いためであろう。
自己相関係数を計算してみる。
cycle_list = ['hours_cycle','employed_cycle','total_hours_cycle']
var_list = ['平均労働時間','就業者数','総労働時間']
print(' 自己相関係数\n----------------------')
for c, v in zip(cycle_list,var_list):
ac = df[c].autocorr()
print(f'{v:<5}\t{ac:.3f}') # 1
自己相関係数
----------------------
平均労働時間 0.486
就業者数 0.830
総労働時間 0.580
コードの説明
:<5はf-stringで代入する変数vのスペースを5に設定し左寄せ<にすることを指定している。また:.3fは小数点第三位までの表示を指定している。
就業者数がより大きな自己相関係数の値となっており,就業者での調整により時間がかかるためである。即ち,今期の就業者数は前期の就業者数に依存するところが大きいという意味である。
次に,GDPのトレンドからの乖離との相関係数を計算してみる。
print('GDPサイクルとの相関係数')
print('-------------------------')
for c, v in zip(cycle_list,var_list):
corr = df[['gdp_cycle',c]].corr().iloc[0,1]
print(f'{v:<9}\t{corr:.3f}')
GDPサイクルとの相関係数
-------------------------
平均労働時間 0.747
就業者数 0.451
総労働時間 0.820
やはり非常に強い正の相関があり,平均労働時間の影響が強いようである。
TFPの特徴#
TFPの水準,トレンド,変動(サイクル)を計算するが,資本の所得分配率を次のように仮定する。
a = 0.36
# 全要素生産性(対数)の計算
df['tfp_log'] = np.log( df['gdp']/( df['capital']**a * df['total_hours']**(1-a) ) )
# 全要素生産性のトレンド(対数)の計算
df['tfp_log_trend'] = py4macro.trend( df['tfp_log'] )
# 全要素生産性のトレンドからの乖離率の計算
df['tfp_cycle'] = 100 * ( df['tfp_log'] - df['tfp_log_trend'] )
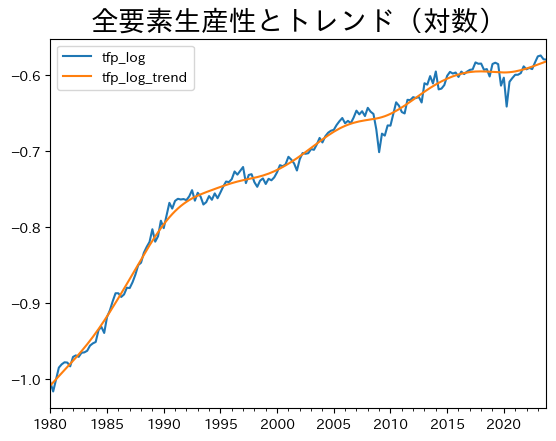
# 全要素生産性とトレンドのプロット
ax = df.plot(y=['tfp_log','tfp_log_trend'])
ax.set_title('全要素生産性とトレンド(対数)', size=20)
pass
全要素生産性の変動をプロットしよう。
ax = df.plot(y='tfp_cycle')
ax.axhline(0, c='red')
ax.set_title('全要素生産性の変動(%)', size=20)
pass
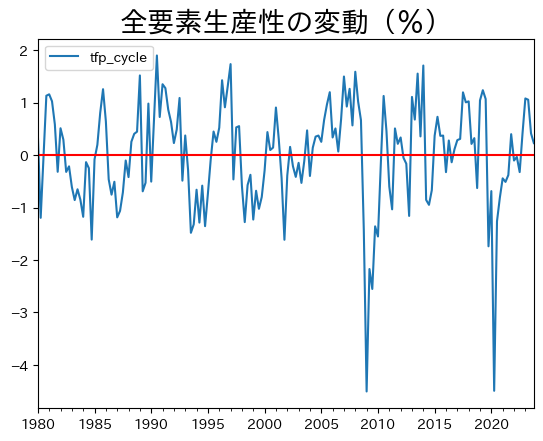
この図から全要素生産性の変動は大きいことが分かる。変動の最小値と最大値を確認してみよう。
df['tfp_cycle'].min(), df['tfp_cycle'].max()
(-4.5070305134806805, 1.899720236490987)
正の乖離は2%近くあり,負の乖離は4%以上となる。リーマンショック時を除くと正も負も絶対値で概ね2%以内に収まっている。
GDPと一緒にプロットしてみよう。
df[['gdp_cycle','tfp_cycle']].max()
gdp_cycle 2.934479
tfp_cycle 1.899720
dtype: float64
ax_ = df.plot(y=['gdp_cycle','tfp_cycle'])
ax_.set_title('GDPとTFPの変動(%)',size=20)
pass
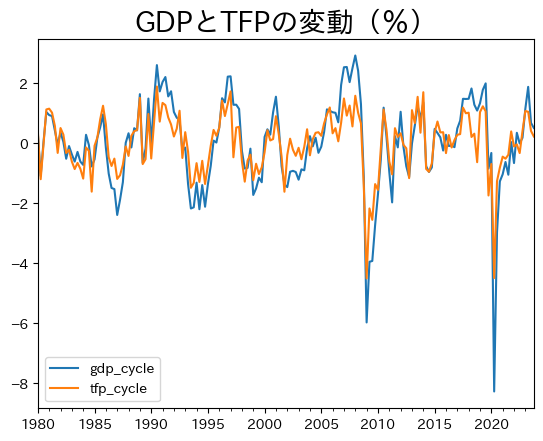
同じ方向に動いているのが確認できる。GDPの変動との相関係数を計算してみると,非常に高いことがわかる。
df[['gdp_cycle','tfp_cycle']].corr().iloc[0,1]
0.9011737000767202
以前の計算結果を使うと,この数字はGDPのどの構成要素よりも高いことが確認できる。次に,自己相関係数を計算してみよう。
df['tfp_cycle'].autocorr()
0.5381766486068552
gdp_cycle程ではないが、強い持続性があることが確認できる。
df['gdp_cycle'].autocorr()
0.6974503788755598
<これらの結果の含意>
全要素生産性の変動は大きく持続性も高い。またGDPとの相関性も大きい。これらから全要素生産性が景気循環を引き起こす要因ではないかということが示唆される。全要素生産性は資本や労働時間で説明できないGDPの要素であり,そのような「その他」の部分に景気循環を引き起こすランダムな要素が隠されているかも知れない,という考え方である。
労働時間とTFPの関係#
GDPと労働時間には正の相関があり、GDPとTFPにも正の相関がある。 では、労働時間とTFPにはどのような関係があるのだろうか。 散布図で確認してみよう。
df.plot.scatter(x='tfp_cycle', y='total_hours_cycle')
pass
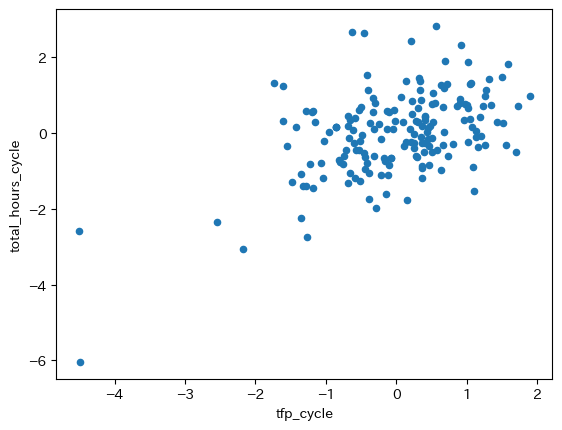
正のトレンドがある。相関係数を計算してみよう。
rho_tfp_total_hours = df[['total_hours_cycle', 'tfp_cycle']].corr().iloc[0,1]
rho_tfp_total_hours
0.5022784971422515
約0.5の値となっており、両変数ともGDPと正の相関があるため、驚くべき結果ではないかも知れない。
経済学的なメカニズムはどうだろうか?
この問は、通常の消費はの労働供給モデルを使うと簡単に理解できる。
TFPの上昇は実質賃金の上昇につながるが、次の2つの効果により消費者の労働供給は変化することになる。
代替効果:賃金の上昇は余暇の機械費用の上昇となるため、余暇を減らし労働供給を増やす。
所得効果:賃金の上昇は所得の増大であり、余暇を増やし労働供給を減らす。
労働時間とTFPの正の相関は、代替効果が所得効果を上回っていることを意味する。 この点は、TFPを景気循環の要素と考える場合に重要なポイントとなり、内生的労働供給の導入で詳細に議論することになる。
AR(1)としてのTFPと労働時間#
TFP#
全要素生産性を景気循環の要因として捉えるために,全要素生産性をAR(1)としてモデル化してみようというのがこの節の目的である。そのためにstatsmodelsを使い回帰分析をしてみよう。まず1期ずらした変数を作成する。
df['tfp_cycle_lag'] = df['tfp_cycle'].shift()
コードの説明
shift()はSeriesを1期ずらすメソッドである。
df[['tfp_cycle','tfp_cycle_lag']].head()
| tfp_cycle | tfp_cycle_lag | |
|---|---|---|
| 1980-01-01 | 0.403866 | NaN |
| 1980-04-01 | -1.195918 | 0.403866 |
| 1980-07-01 | -0.010875 | -1.195918 |
| 1980-10-01 | 1.132255 | -0.010875 |
| 1981-01-01 | 1.159067 | 1.132255 |
列tfp_cycle_lagは列tfp_cycleを1期ずらしていることが確認できる。次に回帰分析をおこなう。
res_tfp = smf.ols('tfp_cycle ~ -1 + tfp_cycle_lag', data=df).fit()
rho_tfp = res_tfp.params.iloc[0]
rho_tfp
0.5380002430150884
コードの説明
回帰式の中に-1とあるが、定数項を省く場合に指定する。
自己相関係数と殆ど変わらない値である。2つの変数の散布図を表示してみよう。
df.plot.scatter(x='tfp_cycle_lag', y='tfp_cycle')
pass
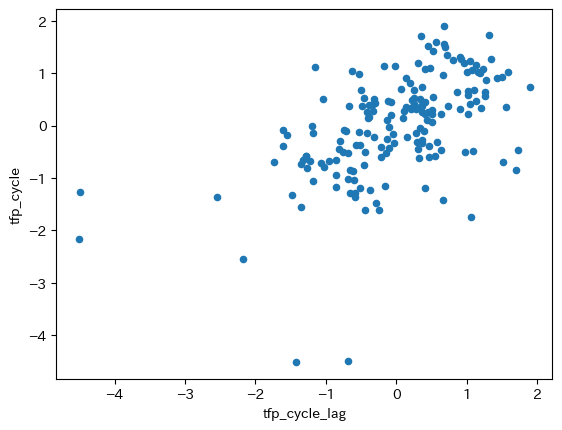
正の相関が図でも確認できる。次に\(\epsilon_t\)について考える。この変数はホワイト・ノイズであり、TFPショックの「源泉」である。平均0の正規分布としてモデル化するが,上の回帰式の残差の標準偏差をTFPの標準偏差の推定値として考えよう。
sigma_tfp = res_tfp.resid.std()
sigma_tfp
0.8270723620212582
コードの説明
res_tfpの属性.residは残差を返している。.residはSeriesであり,その属性std()を使い標本標準偏差を計算している(デフォルトではddof=1)。
初期値は0としてrho_tfpとsigma_tfpを使ってAR(1)の値を計算してプロットしてみよう。
T = 120 # 標本の大きさ
A = 0 # 初期値
A_lst = [A] # 値を格納するリスト
for i in range(T):
e = np.random.normal(loc=0, scale=sigma_tfp)
A = rho_tfp * A + e
A_lst.append(A)
df_A = pd.Series(A_lst) # Seriesの作成
ax_ = df_A.plot() # 図示
ax_.axhline(0, c='red') # 0の平行線
ac_tfp = df_A.autocorr() # 自己相関係数の計算
print(f'TFPの自己相関係数:{ac_tfp:.3f}')
TFPの自己相関係数:0.604
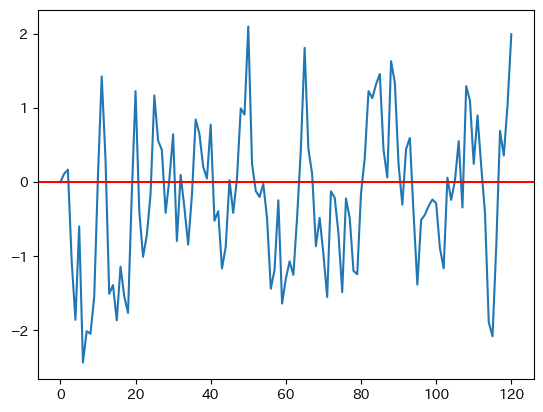
シミュレーションを行う度に図と自己相関係数は異なることになる。
労働時間#
労働時間にも同様の分析を行ってみよう。
# `1`期シフトした`total_hours_cycle`を作成
df['total_hours_cycle_lag'] = df['total_hours_cycle'].shift()
# AR(1)として単回帰分析
res_total_hours = smf.ols('total_hours_cycle ~ -1 + total_hours_cycle_lag', data=df).fit()
rho_total_hours = res_total_hours.params.iloc[0]
スロープ係数の推定値を表示し、散布図をプロットしよう。
rho_total_hours
0.5805663827241658
df.plot.scatter(x='total_hours_cycle_lag', y='total_hours_cycle')
pass
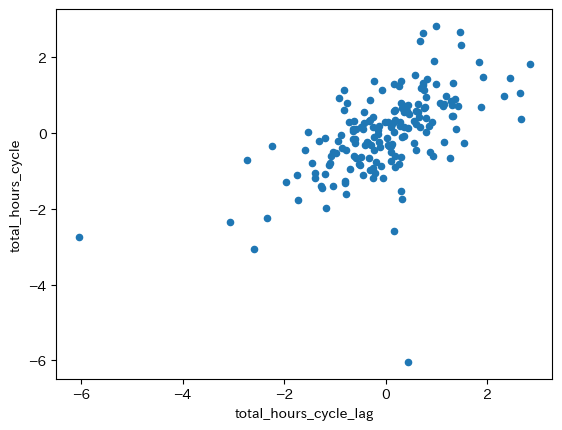
正の相関が確認できる。
確率的ソロー・モデル#
説明#
上で日本のデータを使い全要素生産性のrhoとsigmaを計算しシミュレーションを行なったが,そのような全要素生産性の変動が景気循環の主な要因と考えるのがRBCモデルと呼ばれるものである。RBCモデルの詳細については後の章で検討するが,ここではその導入として次の点を考察する
AR(1)としてのTFPを組み込んだソロー・モデルを景気循環モデルとして考えシミュレーションをおこない,計算結果をデータと比べてどの程度整合性があるかを検討する。
モデルの均衡式として以下を使う。
生産関数:\(Y_t=A_tB_tK_t^aH^{1-a}\)
\(A_tB_t\)が全要素生産性
\(A_t\)は変動を捉える項
\[\begin{split} \begin{align*} \log(A_{t})&=\rho\log(A_{t-1})+\varepsilon_t \\ \varepsilon_t&\sim \textit{WH}(0,\sigma^2) \end{align*} \end{split}\]\(B_t\)はトレンドを捉える項
\[ B_t=B_0(1+g)^t \]\(H\)は一定と仮定する(この仮定によりTFPの効果のみを考察可能となる。)
資本の蓄積方程式:\(K_{t+1}=sY_t+(1-d)K_t\)
消費:\(C_t=(1-s)Y_t\)
投資(貯蓄):\(I_t=sY_t\)
これらの式から次の2式で\(K_t\)と\(A_t\)の値が計算できる。
変数の初期値を次のように仮定する。
\(A_0=1\)
\(K_0=\) 1980年の資本ストックの平均
\(H\)は次の値として一定とする。
\(H=\) 1980年の総労働時間の平均
パラメータの値を次を仮定する。
\(\rho\)と\(\sigma\)は上で計算した
rho_tfpとsigma_tfpの値\(g=\) 1980年から最後の年までの平均四半期成長率
\(s=\) 1980年から最後の年までのGDPに占める投資の割合の平均
\(d=0.025\):年率約10%を想定
\(a=0.36\):資本の所得割合
シミュレーションの結果を次の変数を含むDataFrameにまとめる。
\(Y\),\(C\),\(I\),\(K\),\(A\)の水準の系列
\(Y\),\(C\),\(I\),\(K\),\(A\)のトレンドの系列
\(Y\),\(C\),\(I\),\(K\),\(A\)の変動(サイクル)の系列
初期値の計算#
まずGDP,資本,総労働時間の1980年と2019年の平均を計算する。
var_lst = ['gdp', 'capital', 'total_hours'] #1
year_lst = [df.index[0].year, df.index[-1].year] #2
gdp_dic = {} #3
K_dic = {} #4
H_dic = {} #5
for yr in year_lst: #6
cond = ( df.index.year == yr) #7
mean = df.loc[cond, var_lst].mean() #8
gdp_dic[yr] = mean.iloc[0] #9
K_dic[yr] = mean.iloc[1] #10
H_dic[yr] = mean.iloc[2] #11
コードの説明
#1:3つの変数のリスト#2:平均を計算する年のリストであり,df.index[0].yearとdf.index[-1].yearはインデックスから最初と最後の年を抽出する#3:それぞれの年のGDPの平均を格納する辞書#4:それぞれの年の資本ストックの平均を格納する辞書#5:それぞれの年の総労働時間の平均を格納する辞書#6:year_lstに対してのforループ#7:df.indexの年がyrと同じ場合はTrueを返し,そうでない場合はFalseを返すSeriesをcondに割り当てる。#8:それぞれの年の行,var_lstにある列を抽出し平均を計算する。.mean()は列の平均を計算する。計算した平均は
Seriesとして返されるので,それを左辺にある変数meanに割り当てる。
#9:meanの0番目の要素をgdp_dicのキーyr(年)に対応する値をして設定する。#10:meanの1番目の要素をK_dicのキーyr(年)に対応する値をして設定する。#11:meanの2番目の要素をH_dicのキーyr(年)に対応する値をして設定する。
このコードの結果を確認してみよう。例えば,
gdp_dic
{1980: 273013.55, 2023: 560278.625}
キー・値の2つのペアがある。キー1980の値には1980年のGDPの平均が設定されており,同様に,もう一つのキー2023の値には2023年のGDPの平均が設定されている。従って,次のコードで1980年の値にアクセスできる。
gdp_dic[1980]
他の辞書も同様である。
なぜforループを使うのか。
上のコードでforループを使っているが,もし使わなければ次のようなコードになる。
var_lst = ['gdp', 'capital', 'total_hours']
mean1980 = df.loc['1980-01-01':'1980-10-01', var_lst].mean()
mean2019 = df.loc['2019-01-01':'2019-10-01', var_lst].mean()
gdp1980 = mean1980.iloc[0]
K1980 = mean1980.iloc[1]
H1980 = mean1980.iloc[2]
gdp2019 = mean2019.iloc[0]
K2019 = mean2019.iloc[1]
H2019 = mean2019.iloc[2]
同じようなコードが並んでいる。py4macroのデータがアップデートされて2020年までのデータが含まれることになったとしよう。forループを使うコードであれば2019を2020に一ヵ所だけ変更すれば良い(変更する必要もないコードを書くことも可能)。forループを使わないコードで何ヵ所修正する必要があるか数えてみよう。面倒と感じないだろうか。それに修正箇所が増えればbugが紛れ込む可能性が増えていく。
次に全要素生産性の平均四半期成長率を計算するためにdfの列名を確認しよう。
df.columns
Index(['gdp', 'consumption', 'investment', 'government', 'exports', 'imports',
'capital', 'employed', 'unemployed', 'unemployment_rate', 'hours',
'total_hours', 'inflation', 'price', 'deflator', 'gdp_cycle',
'hours_trend', 'hours_cycle', 'employed_trend_log', 'employed_cycle',
'total_hours_trend_log', 'total_hours_cycle', 'tfp_log',
'tfp_log_trend', 'tfp_cycle', 'tfp_cycle_lag', 'total_hours_cycle_lag'],
dtype='object')
gdpは0番目,capitalは6番目,total_hoursは11番目の列にある。この情報をもとに次のように計算しよう。
var_idx = [0,6,11] # 1
df0 = df.iloc[0,var_idx] # 2
df1 = df.iloc[-1,var_idx] # 3
# 4
B0 = df0['gdp'] / ( df0['capital']**a * df0['total_hours']**(1-a) )
# 5
B1 = df1['gdp'] / ( df1['capital']**a * df1['total_hours']**(1-a) )
no_quarters = len(df) # 6
g = ( B1/B0 )**( 1/no_quarters )-1 # 7
g
0.0024154776754650165
コードの説明
3つの変数の列インデックのリスト
最初の行で3つの変数だけを抽出し
df0に割り当てる。最後の行で3つの変数だけを抽出し
df1に割り当てる。最初の四半期の全要素生産性の計算
最後の四半期の全要素生産性の計算
四半期の数
平均四半期成長率の計算
次にGDPに対する投資の割合の平均を計算する。
s = ( df['investment'] / df['gdp'] ).mean()
s
0.21716704443145593
約22%が投資に回されている。
シミュレーション#
関数#
シミュレーションのコードを関数としてまとめよう。
def stochastic_solow(T=160, # 160=40*4 40年間の四半期の数
rho=rho_tfp,
sigma=sigma_tfp,
g=g,
s=s,
d=0.025,
a=a,
H=H_dic[1980], # 1980年平均に固定
K0=K_dic[1980],
B0=B0):
"""引数:
T: シミュレーションの回数
rho: AR(1)のパラメータ
sigma: ホワイト・ノイズ分散
g: TFPの平均四半期成長率
s: 貯蓄率
d: 資本減耗率
a: 生産関数のパラメータ(資本の所得割合)
H: 総労働時間
返り値
次の変数を含むDataFrame
GDP,消費,投資,資本ストック,全要素生産性の水準,トレンド,変動"""
# ========== A,B,Kの計算 ==========
# アップデート用変数、最初は初期値を設定
A = 1 #1
B = B0 #2
K = K0 #3
# 計算結果を格納するリスト
A_lst = [A] #4
B_lst = [B] #5
K_lst = [K] #6
# A,B,Kの時系列の計算
for t in range(1,T):
K = s * A*B * K**a *H**(1-a) + (1-d)*K #7
e = np.random.normal(0, scale=sigma) #8
A = A**rho * np.exp(e) #9
B = B0 * (1+g)**t #10
A_lst.append(A) #11
B_lst.append(B)
K_lst.append(K)
# ========== DataFrameの作成 ==========
df_sim = pd.DataFrame({'K':K_lst, #12
'A':A_lst,
'B':B_lst})
# ========== Y,C,Iの計算 ========== #13
df_sim['Y'] = df_sim['A'] * df_sim['B'] * df_sim['K']**a * H**(1-a)
df_sim['C'] = (1-s) * df_sim['Y']
df_sim['I'] = s * df_sim['Y']
# ========== トレンドとサイクルの計算 ==========
for v in ['K','A','Y','C','I']:
# ---------- レンドの計算 ---------- #14
df_sim[f'{v}_log_trend'] = py4macro.trend( np.log(df_sim[v]) )
# ---------- サイクルの計算 ---------- #15
df_sim[f'{v}の変動'] = 100 * ( np.log( df_sim[v] ) - df_sim[f'{v}_log_trend'] )
return df_sim
コードの説明
#1:forループでアップデートされるAの値を一次的に格納する。最初は初期値が入っている。#2:forループでアップデートされるBの値を一次的に格納する。最初は初期値が入っている。#3:forループでアップデートされるKの値を一次的に格納する。最初は初期値が入っている。#4:Aの値を格納する空のリスト。初期値が入っている。#5:Bの値を格納する空のリスト。初期値が入っている。#6:Kの値を格納する空のリスト。初期値が入っている。#7:右辺では(4)~(6)の値(A,B,K)を使い来期のKを計算し,その値を左辺のKに割り当てる。この瞬間に(6)のKがアップデートされる。#8:来期のホワイト・ノイズの値を生成しeに割り当てる。#9:右辺では(4)の値(A)を使い来期のAの値を計算し,その値を左辺のAに割り当てる。この瞬間に(4)のAがアップデートされる。#10:右辺では来期のBの値を計算し,その値を左辺のBに割り当てる。この瞬間に(5)のBがアップデートされる。#11:リスト(1)~(3)に来期値を追加する。#12:リスト(1)~(3)を使いDataFrameの作成#13:Y,C,Iを計算し新たな列としてDataFrameに追加#14:トレンドを計算し新たな列としてDataFrameに追加f-stringを使って新しく作る列名をK_trendのように_trendを追加する。
#15:トレンドからの乖離を計算し新たな列としてDataFrameに追加f-stringを使って新しく作る列名をK_cycleのように_cycleを追加する。
実行#
デフォルトの値でシミュレーションを行い、最初の5行を表示する。
df_sim = stochastic_solow()
df_sim.head()
| K | A | B | Y | C | I | K_log_trend | Kの変動 | A_log_trend | Aの変動 | Y_log_trend | Yの変動 | C_log_trend | Cの変動 | I_log_trend | Iの変動 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 850057.673739 | 1.000000 | 0.366461 | 272210.617761 | 213095.442439 | 59115.175322 | 13.585172 | 6.788774 | -0.145123 | 14.512346 | 12.344768 | 16.956305 | 12.099932 | 16.956305 | 10.817680 | 16.956305 |
| 1 | 887921.407217 | 0.711826 | 0.367346 | 197305.887068 | 154457.550725 | 42848.336344 | 13.656441 | 4.019769 | -0.092582 | -24.733977 | 12.425379 | -23.286860 | 12.180543 | -23.286860 | 10.898291 | -23.286860 |
| 2 | 908571.708381 | 0.687994 | 0.368233 | 192749.367636 | 150890.557150 | 41858.810486 | 13.727752 | -0.812324 | -0.039950 | -33.402553 | 12.506096 | -33.694990 | 12.261260 | -33.694990 | 10.979007 | -33.694990 |
| 3 | 927716.226157 | 0.256242 | 0.369123 | 72504.670589 | 56759.045570 | 15745.625019 | 13.799174 | -5.869266 | 0.012709 | -137.434348 | 12.586879 | -139.547284 | 12.342043 | -139.547284 | 11.059791 | -139.547284 |
| 4 | 920268.945522 | 2.979026 | 0.370015 | 842516.179515 | 659549.430924 | 182966.748591 | 13.870768 | -13.834656 | 0.065122 | 102.647437 | 12.667479 | 97.666961 | 12.422643 | 97.666961 | 11.140390 | 97.666961 |
\(Y\)の水準とトレンドの図示(対数)。
np.log( df_sim['Y'] ).plot(title='シミュレーション:Yとトレンド(対数)')
df_sim['Y_log_trend'].plot()
pass
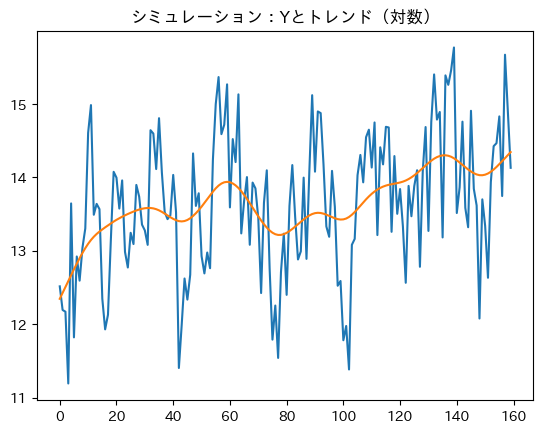
トレンドの傾きは成長率を表しているが,徐々に減少していることが分かる。最初は成長率に対する資本蓄積の効果が大きいが,定常状態に近づくにつれて資本蓄積の効果が減少しているためである。
\(Y\)の変動(サイクル)の図示。
ax_ = df_sim.plot(y='Yの変動', title='シミュレーション:Yの変動(%)')
ax_.axhline(0, c='red')
pass
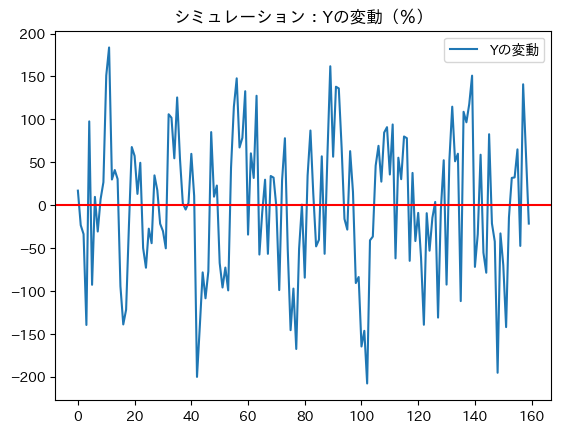
絶対値で概ね2%内に収まった変動となっている。データでは,リーマンショック時はマイナス約4%程乖離したが,それ以外は絶対値で2%以内に収まっており,シミュレーションは概ねデータと同じような特徴を持っていると言える。
結果1:自己相関#
それぞれの変数の自己相関係数を計算してみる。
var_lst = ['Y', 'C', 'I', 'K', 'A']
print('\n--- シミュレーション:変動の自己相関係数 ---\n')
for v in var_lst:
ac = df_sim[f'{v}の変動'].autocorr()
print(f'{v}の変動: {ac:.3f}')
--- シミュレーション:変動の自己相関係数 ---
Yの変動: 0.395
Cの変動: 0.395
Iの変動: 0.395
Kの変動: 0.879
Aの変動: 0.392
まずシミュレーションを行う度にこれらの値は変化することに留意し結果を考えよう。ある程度の自己相関が発生しており,\(A\)の影響が反映されている。\(Y\),\(C\),\(I\)の値は同じなのは,\(C\),\(I\)は\(Y\)の線形関数であるためであり,これらの3つの変数は\(A\)の変動と似た動きになっている。また\(K\)の値が大きいのは、ストック変数であるため変化に時間が掛かることが反映されているためである。
シミュレーション結果を評価するためにデータと比べる必要がある。
dfに含まれる日本のデータを使って自己相関係数を計算してみよう。まず消費,投資,資本の変動を計算する。
data_var_lst = ['consumption','investment','capital']
for v in data_var_lst:
df[f'{v}_cycle'] = np.log( df[v]/py4macro.trend(df[v]) )
結果を示すために,data_var_lstの最初と最後にgdpとtfpを追加する。
data_var_lst = ['gdp']+data_var_lst+['tfp']
print('\n--- データ:変動の自己相関係数 ---\n')
for v in data_var_lst:
ac = df[f'{v}_cycle'].autocorr()
print(f'{v:>11}の変動: {ac:>5.3f}') # 1
--- データ:変動の自己相関係数 ---
gdpの変動: 0.697
consumptionの変動: 0.493
investmentの変動: 0.838
capitalの変動: 0.953
tfpの変動: 0.538
コードの説明
f-stringを使って変数vとacを代入している。:>11はvを表示する幅を11に設定し右寄せ(>)にしている。:>5はacを表示する幅を5に設定して右寄せ(>)にしている。.3fはacを小数点第三位までを表示するように指定している。
実際の資本ストックは非常に大きな持続性があり、シミュレーションの結果はそれを捉えている。しかし他の変数、特に投資に関しては持続性が足りないようである。
しかしシミュレーションの結果はランダム変数の実現値に依存しているので,シミュレーションを行う度に異なる結果が出てくる。また,このシミュレーションではT=160として40年間を考えたが,Tの値によっても結果は大きく左右される。Tを大きくするとより安定的な結果になっていくだろう。例えば,T=10_000を試してみよう。
結果2:GDPとの相関#
次に、\(Y\)との相関係数を計算する。
print('\n--- シミュレーション:GDPとの相関係数 ---\n')
for v in var_lst[1:]:
cov = df_sim[['Yの変動',f'{v}の変動']].corr().iloc[0,1]
print(f'{v}の変動: {cov:.3f}')
--- シミュレーション:GDPとの相関係数 ---
Cの変動: 1.000
Iの変動: 1.000
Kの変動: -0.101
Aの変動: 0.999
\(C\)と\(I\)の値は1.0となっている理由は\(Y\)と線形になっているためであり,全く同じように変動するためである。
\(Y\)と\(A\)は非常に強く相関している。生産関数を見ると,両変数も線形の関係があり,\(K\)の変化によって変化のズレが生じるメカニズムとなっているためである。
シミュレーション結果ををデータと比べてみよう。
print('\n--- データ:GDPとの相関係数 ---\n')
for v in data_var_lst[1:]:
cor = df[['gdp_cycle',f'{v}_cycle']].corr().iloc[0,1]
print(f'{v:>11}の変動:{cor:>5.3f}')
--- データ:GDPとの相関係数 ---
consumptionの変動:0.767
investmentの変動:0.783
capitalの変動:0.131
tfpの変動:0.901
\(C\)と\(I\)に関してはシミュレーションの相関係数は大きすぎる結果となっている。
総評#
確率的ソロー・モデルによるシミュレーション結果は,マクロ変数の特徴を捉えている部分もあるが景気循環モデルとして考えるには難しいだろう。消費者の効用最大化問題が欠落しているため,\(Y\),\(C\),\(I\)が全く同じように動くのがネックになり,消費や投資の特徴を捉えることができていない。後の章で議論するが,消費者の最適化問題や将来の予測などを導入したRBCモデルは,よりデータに近い結果となる。しかし,いくつか問題が残るのも事実である。
TFPショックとは何なのか?
生産関数を見る限りTFPは生産性を表している。技術水準,政府の規制,政治システムや経済制度の変化を捉えると考えられ,例えば,ビジネスに対する規制の強化によって負のショックが発生する。しかし,それだけで実際に観測されるGDPの大きな変動(例えば、リーマン・ショックやコロナ・ショック)を説明するのには疑問である。
ソロー・モデルも含めて価格調整が瞬時に行われるが,次の問題が残る。
古典派の二分法が成立すると仮定するが、短期的には無理がある仮定(例えば、賃金)。
景気循環に対して金融政策は無力なのか?
このような問題意識を持って,RBCモデルとニューケインジアン・モデルを議論していくことにする。