ソロー・モデル#
import japanize_matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import py4macro
import statsmodels.formula.api as smf
# numpy v1の表示を使用
np.set_printoptions(legacy='1.21')
# 警告メッセージを非表示
import warnings
warnings.filterwarnings("ignore")
はじめに#
前章では差分方程式について説明し,簡単な経済モデルを使いコードの書き方を説明した。本章では,差分方程式の応用となるソロー・モデルを考える。ソロー・モデルは1987年にノーベル経済学賞を受賞したRobert M. Solowによって考案された経済成長モデルであり,マクロ経済学の代表的な理論モデルの一つである。今でも盛んに研究が続く経済成長のバックボーン的な存在である。モデルの説明の後,Pythonを使い動学的な特徴を明らかにし,線形近似を使った安定性の確認もおこなう。また理論的な予測がデータと整合性があるかについてもPenn World Tableを使って検討する。本章の内容は次章で議論する所得収斂の分析の基礎となる。
モデルの説明#
ここではモデルの具体的な説明については教科書に譲るとして,簡単にモデルを紹介し,重要な式をまとめることにする。
<記号>
産出量:\(Y_t\)
消費量:\(C_t\)
投資量:\(I_t\)
資本ストック:\(K_t\)
労働:\(L_t\)
貯蓄率(一定な外生変数):\(0<s<1\)
労働人口増加率(一定な外生変数):\(n\equiv\dfrac{L_{t+1}}{L_t}-1\geq 0\)
資本減耗率(一定な外生変数):\(0<d<1\)
生産性(一定な外生変数):\(A>0\)
<一人当たりの変数>
一人当たり産出量:\(y_t\equiv\dfrac{Y_t}{L_t}\)
一人当たり消費量:\(c_t\equiv\dfrac{C_t}{L_t}\)
一人当たり投資量:\(i_t\equiv\dfrac{I_t}{L_t}\)
一人当たり資本ストック:\(k_t\equiv\dfrac{K_t}{L_t}\)
全ての市場は完全競争である閉鎖経済を考えよう。この経済には一種類の財(ニューメレール財)しかなく,消費・貯蓄・投資に使われる。財は次の生産関数に従って生産される。
両辺を\(L_t\)で割ると一人当たりの変数で表した生産関数となる。
消費者は所得の割合\(s\)を貯蓄するが,このモデルの中で消費者の役割はこれだけであり,残り全ては生産側で決定される。貯蓄は\(sY_t\)であり投資\(I_t\)と等しくなる。
\(t\)期の投資により\(t+1\)期の資本ストックは増加するが,毎期ごと資本は\(d\)の率で減耗する。即ち,投資と資本ストックには次の関係が成立する。
ここで左辺は資本ストックの変化であり,右辺は純投資である。\(I_t\)は粗投資,\(dK_t\)は減耗した資本である。式(29),(30),(28)を使うと資本の蓄積方程式が導出できる。
両辺を\(L_t\)で割ることで一人当たりの変数で表すことができる。右辺は単純に一人当たりの変数に直し,左辺は次のように書き換えることに注意しよう。
従って,\(t+1\)期の一人当たりの資本ストックを決定する式は次式で与えられる。
この式は非線形の差分方程式だが,前章でも述べたように,考え方は線形差分方程式と同じであり,数値計算のためのPythonコードに関しては大きな違いはない。また式(32)を資本ストックの成長率を示す式に書き換えることもできる。
この式から資本が蓄積され\(k_t\)が増加すると,その成長率は減少していくことが分かる。
産出量の動学は生産関数(28)を使うことによって\(y_t\)の動きを確認できる。例えば,産出量の成長率を考えてみよう。式(28)を使うと
となり,一人当たり資本ストックの成長率と同じような動きをすることが分かると思う。
次に定常状態を考えよう。定常状態では資本ストックは一定なり,資本の成長率である式(33)の右辺はゼロになる。 定常値は次のように確認することができる。
この値を生産関数(28)に代入することにより一人当たりGDPの定常値を求めることができる。
Fig. 7は資本ストックの動学的均衡を示している。
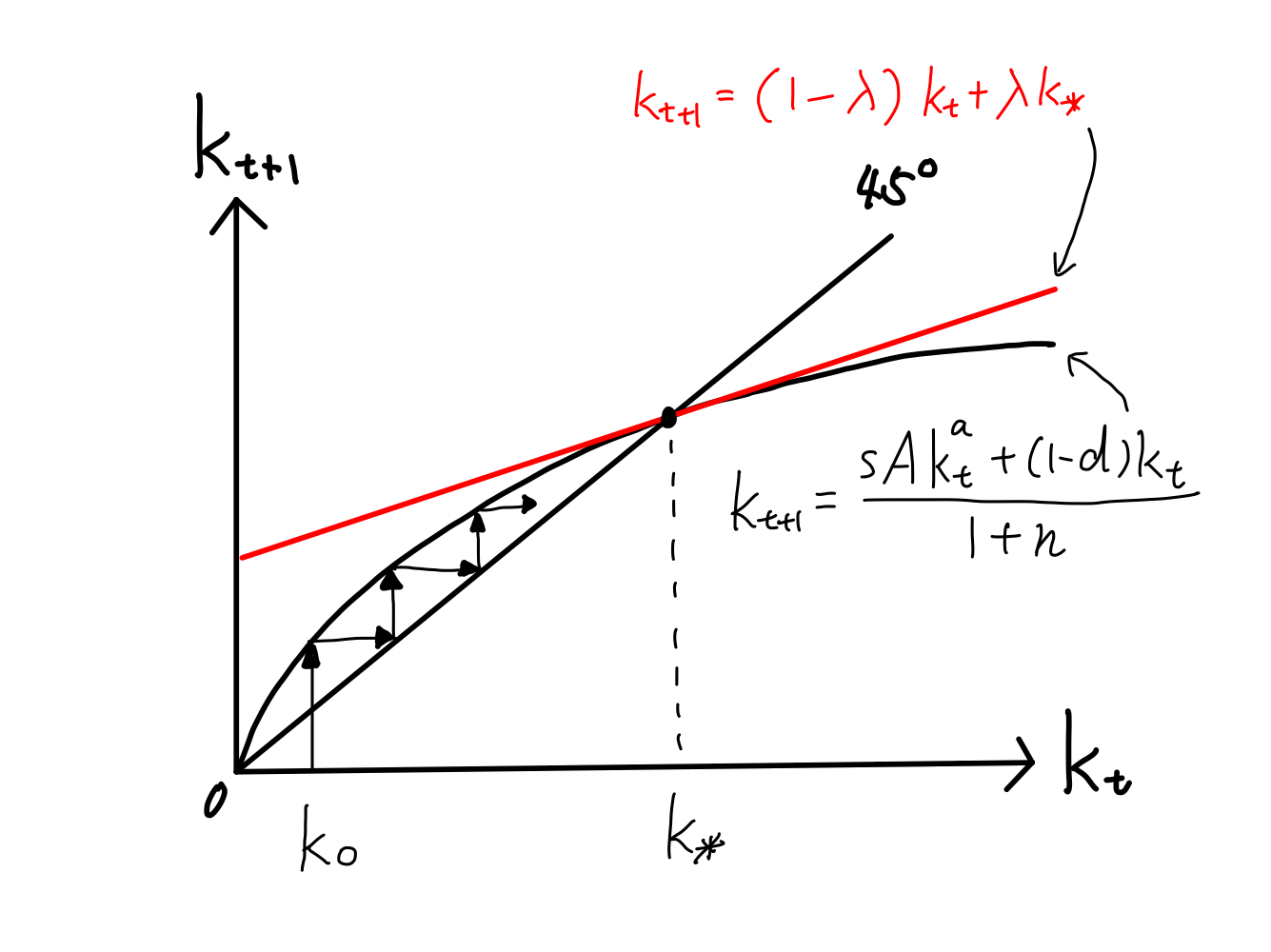
Fig. 7 一人当たり資本ストックの動学#
動学#
差分方程式(32)を使って資本ストックの変化をプロットするが,以前と同じようにDataFrameを生成する関数を定義しよう。
def solow_model(k0, A=10, a=0.3, s=0.3, n=0.02, d=0.05, T=100):
"""引数
k0: 資本の初期値
A: 生産性
a: 資本の所得比率 (a<1)
s: 貯蓄率 (s<1)
n: 労働人口成長率(%)
d: 資本減耗率 (d<1)
T: ループによる計算回数
戻り値
資本と産出量からなるDataFrame"""
k = k0
y = A * k0**a
k_lst = [k]
y_lst = [y]
for t in range(T):
k = ( s * A * k**a + (1-d) * k )/( 1+n )
y = A * k**a
k_lst.append(k)
y_lst.append(y)
# DataFrameの作成
dic = {'capital':k_lst, 'output':y_lst}
df = pd.DataFrame(dic)
return df
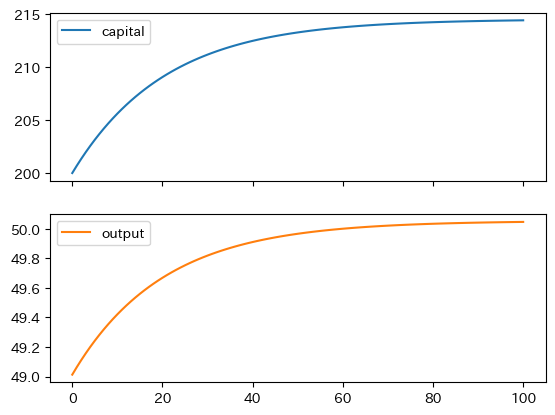
引数に使うパラーメータには次の値を使ってプロットしてみよう。
df = solow_model(k0=200)
df.plot(subplots=True)
pass
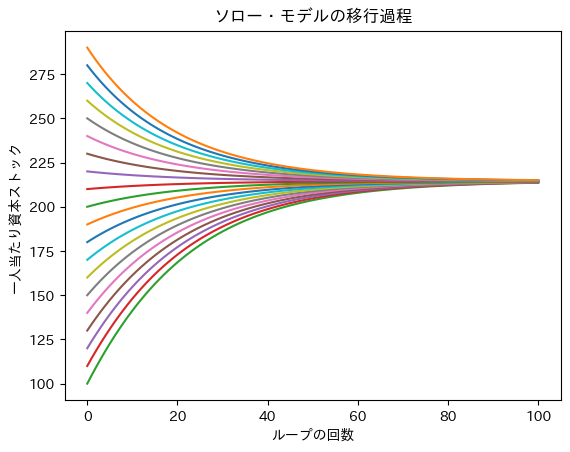
異なる初期値を使って資本の変化をプロットしてみる。
initial_lst = range(100,300,10) # 1
ax = pd.DataFrame({'capital':[],
'output':[]}).plot(legend=False) # 2
for i in initial_lst: # 3
solow_model(k0=i).plot(y='capital', legend=False, ax=ax)
ax.set(title='ソロー・モデルの移行過程', # 4
xlabel='ループの回数',
ylabel='一人当たり資本ストック')
pass
コードの説明
#1:range(100,300,10)は100から300-1=299までの間の数を10間隔で生成する。100,110,120,\(cdots\),290となる。#2:空のDataFrameを使って空の軸を作成し,axに割り当てる。#3:initial_listに対してforループを設定する。一回のループごとに以下をおこなう。iはk0の引数に使う値になる。.plot()を使いaxに図をプロットする。これにより図が重ねて描かれる。
#4:axのメソッドset()を使い,引数を使い以下を追加する。title:図のタイトルxlabel:横軸のラベルylabel:縦軸のラベルこの3行を次のように書いても同じ結果となる。
ax.set_title('ソロー・モデルの移行過程') ax.set_xlabel('ループの回数') ax.set_ylabel('一人当たり資本ストック')
この3つを
.set()でまとめて書いたのが上のコードである。3つに分けて書く利点はフォントの大きさを指定できることだろう。
図から初期値に関わらず定常値に収束していることが分かる。即ち,定常状態である長期均衡は安定的である。
定常状態での変数の値#
次に定常状態での変数の値を計算してみよう。
def calculate_steady_state(A=10, a=0.3, s=0.3, n=0.02, d=0.05):
k_ss = ( s * A / (n+d) )**( 1/(1-a) )
y_ss = A * k_ss**( a/(1-a) )
return k_ss, y_ss
ss = calculate_steady_state()
print(f'定常状態での資本ストック:{ss[0]:.1f}'
f'\n定常状態での産出量: {ss[1]:.1f}')
定常状態での資本ストック:214.5
定常状態での産出量: 99.8
線形近似#
説明#
Fig. 7は,定常状態は安定的であることを示している。またシミュレーションの結果からも定常状態の安定性が確認できる。次に,線形近似を使って解析的に安定性を確認してみることにする。また線形近似は真の値からの乖離が発生するが,その乖離がどの程度のものかをコードを使って計算することにする。
<テイラー展開による1次線形近似>
関数\(z=f(x)\)を\(x_*\)でテイラー展開すると次式となる。
\[ z=f(x^*)+\left.\frac{df}{dx}\right|_{x=x_*}(x-x_*) \]
ソロー・モデルの式に当てはめると次のような対応関係にある。
\(z\;\Rightarrow\;k_{t+1}\)
\(f(x)\;\Rightarrow\;\dfrac{Ask_{t}^{\alpha}+(1-d)k_t}{1+n}\)
\(x^*\;\Rightarrow\;k^*\)
公式に従って計算してみよう。
ここで
3行目は定常状態の式(32)と式(35)を使っている。式(37)は\(k_{t+1}\)と\(k_t\)の線形差分方程式になっており,\(k_t\)の係数は
が成立する。Fig. 7の赤い直線が式(37)である。従って,初期値\(k_0>0\)からスタートする経済は必ず長期的均衡に収束することがわかる。
式(38)は\(k_t\)の係数だが,その裏にあるメカニズムを考えてみよう。特に,\(a\)の役割を考える。\(a\)は資本の所得比率であり,目安の値は1/3である。そしてソロー・モデルにおける重要な役割が資本の限界生産性の逓減を決定することである。この効果により資本ストックが増加する毎に産出量も増加するがその増加自体が減少する。この効果により,Fig. 7の曲線は凹関数になっており,生産関数(28)の場合は必ず45度線と交差することになる。即ち,資本の限界生産性の逓減こそが\(k_t\)が一定になる定常状態に経済が収束す理由なのである。この点がソロー・モデルの一番重要なメカニズムとなる。
ここで\(a\)が上昇したとしよう。そうなると資本の限界生産性の逓減の効果は弱くなり,資本ストックが増加しても産出量の増加自体の減少は小さくなる。また式(35)が示すように定常状態での資本ストックはより大きくなる。これはFig. 7で曲線が上方シフトしている考えると良いだろう。
内生的成長
更に\(a\)を上昇させて\(a=1\)になるとどうなるのだろう。この場合,資本の限界生産性は逓減せず一定となる。そして\(k_t\)の係数である式(39)は1になってしまい,\(k_t\)が一定になる定常状態が存在しなくなる。\(a=1\)となる極限の状態を内生的成長と呼ぶ。ここでは立ち入った議論はしないが,内生的成長の典型的な生産関数は次式となり,
この生産関数に基づくモデルは\(AK\)モデルと呼ばれる。資本の限界生産性は\(A\)で一定になることが分かると思う。
\(\lambda\)の解釈#
上の議論から\(\lambda\)が定常状態の安定性を決定することが分かったが,\(\lambda\)の値はどのように解釈できるだろうか。例えば,\(\lambda\)が大きい場合と小さい場合では何が違うのだろうか。次式は式(37)の最後の等号を少し書き換えたものである。
左辺は\(t+1\)期において定常状態までの残りの「距離」であり,右辺の\(k_*-k_t\)は\(t\)においての定常状態までの残りの「距離」である。後者を次の様に定義し
式(40)を整理すると次式となる。
左辺は\(t\)期と\(t+1\)期において定常状態までの「距離」が何%減少したかを示す資本ストックの収束速度である。このモデルの中での収束速度の決定要因は資本の所得比率\(\alpha\),労働人口増加率\(n\)と資本の減耗率\(d\)ということである。
ここでは\(a\)の役割に着目し,なぜ\(a\)の上昇は収束速度の減少をもたらすのかを直感的に考えてみよう。この点を理解するために,まず\(a\)は資本の限界生産性の逓減を決定するパラーメータであることを思い出そう。\(a\)が上昇するとその効果は弱まる。即ち,資本ストックが1単位増加すると産出量は増え,その増加分が減少するのが「逓減」であるが,その減少が小さくなるのである。これにより(上で説明したように)\(k_t\)が一定となる定常状態は増加することになる。重要な点は,定常状態の増加の意味である。定常状態はマラソンのゴールの様なものである。トップランナーはゴールすると走るのを止め,後続ランナーはトップランナーとの「距離」を縮めることができる。定常状態の増加は,ゴールが遠くなることと同じである。ゴールが遠のくとトップランナーは走り続けるわけだから,それだけ距離を縮めることが難しくなり収束速度が減少することになる。極端なケースとして\(a=1\)の場合,\(k_t\)が一定になる定常状態は存在せず,ゴールがない状態が永遠に続いており,永遠に収束しないということである。言い換えると,資本の限界生産性の逓減(\(a<1\))こそが「距離」を縮めキャッチアップを可能にするメカニズムなのだ。
労働人口増加率\(n\)と資本の減耗率\(d\)の上昇は収束速度を速くする。式(35)から分かる様に,\(n\)もしくは\(d\)の上昇は定常状態を減少させる。即ち,ゴールはより近くになるということだ。
これである程度キャッチアップのメカニズムが分かったと思うが,今までの議論で足りないものが2点あるので,それらについて簡単に言及する。第一に,ここで考えたソロー・モデルには技術進歩が抜けている(一定な\(A\)を仮定した)。この点を導入してこそソロー・モデルのフルバージョンであり,その場合の労働効率1単位当たり資本ストック(\(K_t/(A_tL_t)\))の収束速度は次の式で与えられる。
ここで\(g\)は技術進歩率である。ソロー・モデルでは4つの変数が収束速度の決定要因になるる。\(g=0\)の場合,式(38)と同じになることが確認できる。第二に,式(38)は資本ストックの収束速度であり一人当たりGDPの収束速度と異なるのではないかという疑問である。実は同じである。これはコブ・ダグラス生産関数(28)を仮定しているからであり,対数の近似を使えば簡単に示すことができる。式(40)を次のように書き直そう。
ここで\(\log(1+x-1)\approx x-1\)の近似を使い左辺を次のように書き換える。
同様に\(\dfrac{k_{t}}{k_*}-1\)もこの形に書き換えることができる。後はこの関係を使うことにより,式(43)を整理すると次式となる。
線形近似による誤差#
次に関数solow_model()を修正して線形近似の誤差を確かめてみよう。
def solow_model_approx(k0, A=10, a=0.3, s=0.3, n=0.02, d=0.05, T=20):
"""引数
k0: 資本の初期値
A: 生産性
a: 資本の所得比率 (a<1)
s: 貯蓄率 (s<1)
n: 労働人口成長率(n>=0)
d: 資本減耗率 (d<1)
T: ループによる計算回数
戻り値
線形近似モデルを使い計算した資本と産出量からなるDataFrame"""
k = k0
y = A * k0**a
k_lst = [k]
y_lst = [y]
# 定常状態
k_ss = ( s*A / (n+d) )**( 1 / (1-a) )
for t in range(T):
lamb = 1 - (1-a) * (n+d) / (1+n) # lambda
k = lamb*k + (1-lamb) * k_ss # 線形近似
y = A * k**a
k_lst.append(k)
y_lst.append(y)
# DataFrameの作成
dic = {'capital':k_lst, 'output':y_lst}
df = pd.DataFrame(dic)
return df
近似誤差を計算するために,上と同じ数値でシミュレーションをおこなう。
df_approx = solow_model_approx(k0=200, T=150)
非線形のモデル(32)と線形近似のモデル(37)で計算された資本ストックを重ねて図示してみよう。
ax = df_approx.plot(y='capital', label='線形近似モデル')
df.plot(y='capital', label='ソロー・モデル', ax=ax)
pass
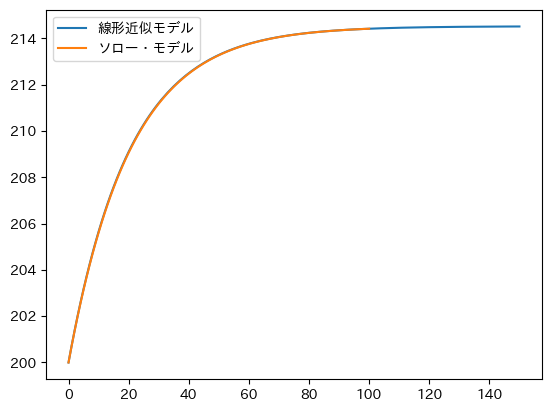
df_approxが図示され、その上にdfが重ねて表示されるが、殆ど同じのように見える。誤差を%で計算し図示してみよう。
( 100*( 1-df_approx['capital']/df['capital'] ) ).plot(marker='.')
pass
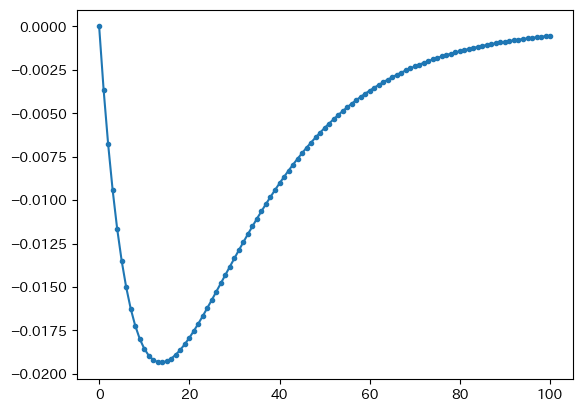
初期の資本ストック\(k_0\)は同じなので誤差はゼロであり,\(t=1\)から線形近似の誤差が現れることになる。誤差は単調ではない。Fig. 7の図が示しているように,階段のような形で増加していくためであり,その階段お大きさや進み具合が異なるためである。線形近似の値は大き過ぎるため負の値になっているが、誤差は大きくても約0.02%であり、定常状態に近づくにつれて誤差はゼロに近づいている。もちろん,誤差の値は初期値が定常値から離れればそれだけ大きくなっていく。
長期均衡の予測#
説明#
この節では長期均衡(定常状態)に焦点を当て,理論的な予測のデータとの整合性をチェックする。まず定常状態の特徴をまとめよう。式(35)と(36)を使いうと定常状態での一人当たり資本ストックとGDPは次式で与えれる。
この2つをそれぞれ試すこともできるが,同時に捉えるために2つの式の比率を考える。
この値は資本ストック対GDP比と等しいく,次のことが分かる。
貯蓄率\(s\)の上昇は資本ストック対GDP比を増加させる。。
労働人口成長率\(n\)の上昇は資本ストック対GDP比を減少させる。
資本減耗率\(d\)の上昇は資本ストック対GDP比を減少させる。
この3つの予測が成立するか確かめるためにpy4macroモジュールに含まれるPenn World Tableの次の変数を使う。
cgdpo:GDP(2023年;生産側)cn:物的資本ストック(2023年)csh_i:対GDP比資本形成の比率投資の対GDP比である。
貯蓄率\(s\)の代わりに使う。
1960年〜2023年の平均を使う。
emp:雇用者数労働人口の代わりに使う。
1960年〜2023年の平均成長率\(n\)の計算に使う。
delta:資本ストックの年平均減耗率1960年〜2023年の平均を使う。
データ#
1960年以降のデータをpwtに割り当てる。
pwt = py4macro.data('pwt').query('year >= 1960')
また、後で使うために、2023年を変数latest_yearに割り当てよう。
latest_yr = pwt['year'].max()
latest_yr
2023
貯蓄率#
1960年から2023年までの国別の貯蓄率の平均を計算するが必要がある。ここで説明しているDataFrameのメソッド.groupby()を使うのが最も簡単な計算方法だろう。ここでは異なる方法としてDataFrameのメソッド.pivot()を紹介する。.pivot()はデータを整形する上で非常に便利なメソッドなので知って損はないだろう。
.pivot()は,元のDataFrameから列を選び,その列から新たなDataFrameを作成する便利なメソッドである。実際にコードを実行して説明しよう。
saving = pwt.pivot(index='year', columns='country', values='csh_i')
saving.head()
| country | Albania | Algeria | Angola | Anguilla | Antigua and Barbuda | Argentina | Armenia | Aruba | Australia | Austria | ... | United Arab Emirates | United Kingdom | United States | Uruguay | Uzbekistan | Venezuela (Bolivarian Republic of) | Viet Nam | Yemen | Zambia | Zimbabwe |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| year | |||||||||||||||||||||
| 1960 | NaN | 0.292292 | NaN | NaN | NaN | 0.140910 | NaN | NaN | 0.336618 | 0.207003 | ... | NaN | 0.239277 | 0.230340 | 0.144855 | NaN | 0.358695 | NaN | NaN | 0.050083 | 0.189235 |
| 1961 | NaN | 0.334405 | NaN | NaN | NaN | 0.149655 | NaN | NaN | 0.296569 | 0.205342 | ... | NaN | 0.241543 | 0.231433 | 0.154907 | NaN | 0.338576 | NaN | NaN | 0.046848 | 0.181016 |
| 1962 | NaN | 0.372550 | NaN | NaN | NaN | 0.132196 | NaN | NaN | 0.317393 | 0.187515 | ... | NaN | 0.225732 | 0.236722 | 0.133602 | NaN | 0.349284 | NaN | NaN | 0.042926 | 0.128391 |
| 1963 | NaN | 0.355781 | NaN | NaN | NaN | 0.112345 | NaN | NaN | 0.309578 | 0.184681 | ... | NaN | 0.225506 | 0.239582 | 0.122253 | NaN | 0.320073 | NaN | NaN | 0.031393 | 0.111248 |
| 1964 | NaN | 0.267336 | NaN | NaN | NaN | 0.137489 | NaN | NaN | 0.332907 | 0.207555 | ... | NaN | 0.268017 | 0.240732 | 0.100760 | NaN | 0.389544 | NaN | NaN | 0.020332 | 0.114591 |
5 rows × 185 columns
コードの説明
pwtの3つの列year,country,csh_iを使って新たなDataFrameを作成しsavingに割り当てている。引数は次の役割をする。
index:新たなDataFrameの行ラベルを指定する。コードでは
yearが指定され行ラベルになっている。
columns:新たなDataFrameの列ラベルを指定する。コードでは
countryが指定され列ラベルになっている。
values:新たなDataFrameの値を指定する。コードでは
csh_iが指定され,その値でDataFrameが埋め尽くされている。
1960年以降欠損値がない国だけを使うことにしよう。NaNがある列を削除する必要があるので.dropna()を使う。
saving = saving.dropna(axis='columns')
saving.head()
| country | Algeria | Argentina | Australia | Austria | Bangladesh | Barbados | Belgium | Benin | Bolivia (Plurinational State of) | Botswana | ... | Tunisia | Türkiye | U.R. of Tanzania: Mainland | Uganda | United Kingdom | United States | Uruguay | Venezuela (Bolivarian Republic of) | Zambia | Zimbabwe |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| year | |||||||||||||||||||||
| 1960 | 0.292292 | 0.140910 | 0.336618 | 0.207003 | 0.014559 | 0.090716 | 0.274124 | 0.039017 | 0.206834 | 0.102649 | ... | 0.112642 | 0.196667 | 0.104302 | 0.098392 | 0.239277 | 0.230340 | 0.144855 | 0.358695 | 0.050083 | 0.189235 |
| 1961 | 0.334405 | 0.149655 | 0.296569 | 0.205342 | 0.017380 | 0.079419 | 0.294998 | 0.037919 | 0.163327 | 0.124339 | ... | 0.146735 | 0.199453 | 0.117391 | 0.113316 | 0.241543 | 0.231433 | 0.154907 | 0.338576 | 0.046848 | 0.181016 |
| 1962 | 0.372550 | 0.132196 | 0.317393 | 0.187515 | 0.026159 | 0.073334 | 0.280298 | 0.037577 | 0.267985 | 0.143526 | ... | 0.187319 | 0.197619 | 0.099309 | 0.115779 | 0.225732 | 0.236722 | 0.133602 | 0.349284 | 0.042926 | 0.128391 |
| 1963 | 0.355781 | 0.112345 | 0.309578 | 0.184681 | 0.018701 | 0.078361 | 0.269299 | 0.038658 | 0.227549 | 0.158613 | ... | 0.192624 | 0.200368 | 0.088076 | 0.143015 | 0.225506 | 0.239582 | 0.122253 | 0.320073 | 0.031393 | 0.111248 |
| 1964 | 0.267336 | 0.137489 | 0.332907 | 0.207555 | 0.023628 | 0.076604 | 0.303141 | 0.032848 | 0.231306 | 0.195691 | ... | 0.206365 | 0.197618 | 0.116514 | 0.182406 | 0.268017 | 0.240732 | 0.100760 | 0.389544 | 0.020332 | 0.114591 |
5 rows × 111 columns
コードの説明
.dropna()はNaNがある行か列を削除する。行と列のどちらを削除するかは引数axisで指定するが,デフォルトは'rows'である。即ち,引数なしで.dropna()を実行するとNaNがある行が削除される。ここでは列を削除したいので,引数に'columns'を指定している。
AlbaniaやAngolaなどが削除されていることが確認できる。何ヵ国残っているか確認してみよう。
saving.shape
(64, 111)
コードの説明
属性.shapeはDataFrameの行の数(左の数字)と列(右の数字)の数を返す。
111ヵ国含まれていることが確認できた。次に,それぞれの列の平均を計算する。
saving = saving.mean().to_frame('saving_rate') # 1
saving.head()
| saving_rate | |
|---|---|
| country | |
| Algeria | 0.340081 |
| Argentina | 0.146066 |
| Australia | 0.277670 |
| Austria | 0.272072 |
| Bangladesh | 0.143379 |
コードの説明
.mean()はそれぞれの列の平均を計算し,Seriesを返す。後でDataFrameを結合するメソッド.merge()を使うために.to_frame()を使ってSeriesをDataFrameに変換しており,引数saving_rateは列ラベルを指定している。もちろん引数を使わずに2行に分けることも可能である。
saving = saving.mean().to_frame()
saving.columns = ['saving_rate']
Tip
上の計算では1960年以降に欠損値が一つでもあればその国は排除されたが,全ての年でデータが揃っている経済だけを扱いたい場合に便利に使える方法である。一方で,.groupby()を使うと欠損値があっても平均は計算されるので,単純に.groupby()を使うと1960年以降に欠損値がある経済も含まれることになる。それを避けるためには一捻り必要だが,それについては貯蓄率・資本減耗率・労働人口増加率の平均が参考になるだろう。
資本減耗率#
savingと同じ方法で資本減耗率の平均からなるDataFrameを作成する。
depreciation = pwt.pivot(index='year', columns='country', values='delta')
depreciation = depreciation.dropna(axis='columns')
depreciation.shape
(64, 110)
110ヵ国含まれている。
depreciation = depreciation.mean().to_frame('depreciation')
労働人口成長率#
平均成長率を計算するには1960年と2023年の労働人口だけで計算できるが,上と同じ方法で計算してみる。
emp = pwt.pivot(index='year', columns='country', values='emp')
emp = emp.dropna(axis='columns')
emp.shape
(64, 91)
91ヵ国しか含まれていない。
emp_growth = ( ( emp.loc[latest_yr,:]/emp.loc[1960,:] )**(1/(len(emp)-1))-1
).to_frame('employment_growth')
emp_growth.head()
| employment_growth | |
|---|---|
| country | |
| Algeria | 0.029506 |
| Argentina | 0.017632 |
| Australia | 0.019195 |
| Austria | 0.005053 |
| Bangladesh | 0.021290 |
資本ストック対GDP比#
2023年のcgdpoとcnを使って資本ストック対GDP比を含むDataFrameを作成する。
ky_ratio = pwt.query('year == @latest_yr') \
.loc[:,['country','cgdpo','cn']] \
.set_index('country') \
.dropna()
ky_ratio.head()
| cgdpo | cn | |
|---|---|---|
| country | ||
| Aruba | 4823.155273 | 2.274172e+04 |
| Angola | 225950.187500 | 7.037451e+05 |
| Anguilla | 327.047302 | 4.200483e+03 |
| Albania | 44771.500000 | 2.628630e+05 |
| United Arab Emirates | 816201.875000 | 5.953914e+06 |
コードの説明
@を使うことにより,.query()の外で定義された変数latest_yrを.query()の引数の文字列の中でそのまま使えるようなる。.set_index(''country')を使ってcountryを行ラベルに指定し,.dropna()によって欠損値がある行は削除する。
資本ストック対GDP比の列の作成しよう。
ky_ratio['ky_ratio'] = np.log( ky_ratio['cn'] / ky_ratio['cgdpo'] )
含まれる国数を確認する。
ky_ratio.shape
(180, 3)
180ヵ国含まれており,savingやdepreciationの国数よりも多くの国が含まれている。
データの結合#
上で作成したDataFrameを結合する必要があり,そのためのPandasの関数.merge()の使い方を説明する。df_leftとdf_rightの2つのDataFrameがあるとしよう。df_leftを左のDataFrame,df_rightを右のDataFrameと呼ぶことにする。2つを結合する場合,次のコードとなる。
pd.merge(df_left, df_right)
しかし注意が必要な点が2つある。
行数が同じでも
df_leftとdf_rightでは行の並びが異なる可能性がある。行数が異なる可能性がある。
これらの問題に対応するためのに引数が用意されている。
まず1つ目の問題は,行ラベルを基準に,もしくはある列に合わせて行を並び替えることにより対応できる。例えば,上で作成したDataFrameであれば,行ラベルがcountryになっているので,それに合わせて結合すれば良い。その場合の引数を含めたコードは次の様になる。
pd.merge(df_left, df_right, left_index=True, right_index=True)
ここでのleft_index=Trueとright_index=Trueは行ラベルを基準に結合することを指定しており,デフォルトは両方ともFalseである。行ラベルではなく,ある列を基準に結合したい場合もあるだろう。その場合は次の引数を使う。
pd.merge(df_left, df_right,
left_on=<`df_left`の基準列のラベル(文字列)>,
right_on=<`df_right`の基準列のラベル(文字列)>)
left_onは基準列に使うdf_leftにある列ラベルを文字列で指定する。同様にright_onは基準列に使うdf_rightにある列ラベルを文字列で指定する。デフォルトは両方ともNoneとなっている。
2つ目の問題はhowという引数を使うことにより対処できる。使える値は次の4つであり,いずれも文字列で指定する。
'inner':df_leftとdf_rightの両方の基準列にある共通の行だけを残す(デフォルト)。'left':df_leftの行は全て残し,df_rightからはマッチする行だけが残り,対応する行がない場合はNaNが入る。'right':df_rightの行は全て残し,df_leftからはマッチする行だけが残り,対応する行がない場合はNaNが入る。'outer':df_leftとdf_rightの両方の行を全て残し,マッチする行がない場合はNaNを入れる。
では実際に上で作成したDataFrameを結合しよう。
for df_right in [saving, depreciation, emp_growth]: # 1
ky_ratio = pd.merge(ky_ratio, df_right, # 2
left_index=True, # 3
right_index=True, # 4
how='outer') # 5
コードの説明
df_rightが上の説明のdf_rightに対応している。[saving, depreciation, emp_growth]は上で作成したDataFrameのリスト。ky_ratioが上の説明のdf_leftに対応している。右辺で結合したDataFrameを左辺にあるky_ratioに割り当てている(際割り当て)。ky_ratioの行ラベルを基準とすることを指定する。df_rightの行ラベルを基準とすることを指定する。ここでの
'outer'は左右のDataFrameのそれぞれの行ラベルを残し,値がない箇所にはNaNを入れることを指定する。
結合の結果を表示してみよう。
ky_ratio.head()
| cgdpo | cn | ky_ratio | saving_rate | depreciation | employment_growth | |
|---|---|---|---|---|---|---|
| country | ||||||
| Albania | 44771.500000 | 2.628630e+05 | 1.770061 | NaN | NaN | NaN |
| Algeria | 669309.500000 | 2.916442e+06 | 1.471873 | 0.340081 | 0.041635 | 0.029506 |
| Angola | 225950.187500 | 7.037451e+05 | 1.136102 | NaN | NaN | NaN |
| Anguilla | 327.047302 | 4.200483e+03 | 2.552850 | NaN | NaN | NaN |
| Antigua and Barbuda | 2526.366943 | 2.060428e+04 | 2.098716 | NaN | NaN | NaN |
列AlbaniaやAngolaはsaving,depreciation,emp_growthのDataFramには無いためNaNが入っている。
結合後のky_ratioの情報を表示してみよう。
ky_ratio.info()
<class 'pandas.core.frame.DataFrame'>
Index: 180 entries, Albania to Zimbabwe
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 cgdpo 180 non-null float64
1 cn 180 non-null float64
2 ky_ratio 180 non-null float64
3 saving_rate 111 non-null float64
4 depreciation 110 non-null float64
5 employment_growth 91 non-null float64
dtypes: float64(6)
memory usage: 9.8+ KB
180ヵ国が含まれるがNaNがある国も多いことが分かる。
トレンド線と散布図#
ここでは次の3つをおこなう。
資本ストック対GDP比と次の3つの変数の散布図の表示
貯蓄率
資本減耗率
労働人口増加率
回帰分析に基づいて計算したトレンド線の表示
トレンド線の傾きの統計的優位性の表示
forループを使ってこれらを同時に計算・表示する。まずky_ratioの列ラベルをみると,回帰分析の説明変数に使う変数が最後の3つに並んでいる。
ky_ratio.columns[-3:]
Index(['saving_rate', 'depreciation', 'employment_growth'], dtype='object')
これを使いforループを組んでみよう。
for var in ky_ratio.columns[-3:]: #1
df_tmp = ky_ratio.copy() #2
res = smf.ols(f'ky_ratio ~ {var}', #3
data=df_tmp).fit() #4
bhat = res.params.iloc[1] #5
pval = res.pvalues.iloc[1] #6
df_tmp['Trend'] = res.fittedvalues #7
ax = df_tmp.plot.scatter(x=var, y='ky_ratio') #8
df_tmp.sort_values('Trend').plot(x=var, #9
y='Trend',
color='red',
ax=ax)
ax.set_title(f'トレンドの傾き:{bhat:.2f}\n' #10
f'p値:{pval:.3f}', size=20) #11
ax.set_ylabel('資本ストック対GDP比(対数)', #12
size=15) #13
ax.set_xlabel(f'{var}', size=20) #14
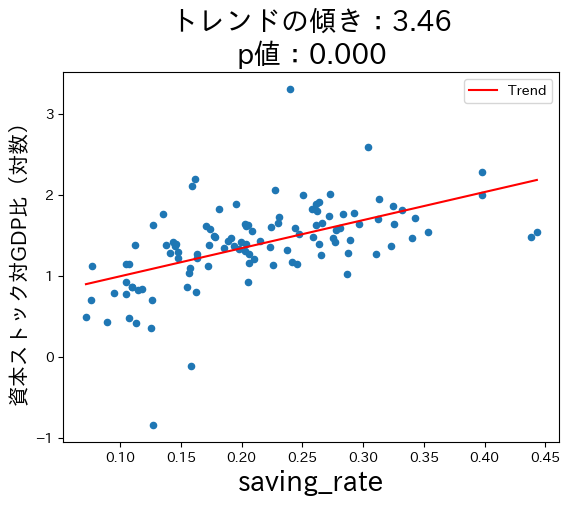
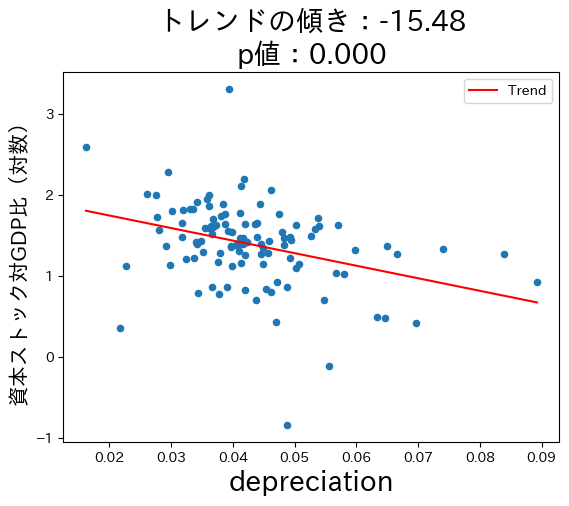
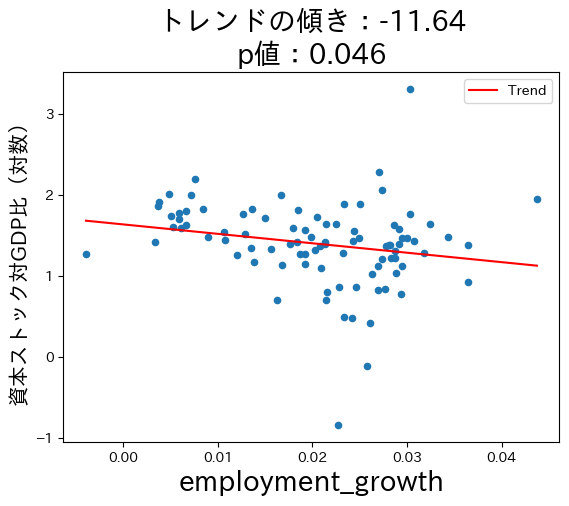
コードの説明
#1:ky_ratioの最後の3列のラベルに対してforループを組んで,varはその列ラベルを指す。#2:ky_ratioのコピーを作りdf_tmpに割り当てる。.copy()は実態としては別物のコピーを作成する。詳細は割愛するが.copy()がないと実態は同じで参照記号のみが異なることになり,予期しない結果につながることを防ぐために.copy()を使っている。#3:回帰分析をおこなっているが,f-stringを使い回帰式の説明変数を指定している。また回帰分析の結果をresに割り当てている。#4:dataで回帰分析のデータの指定をおこない,.fit()で自動計算!#5:resの属性.paramsは推定値を2つ返すが,1番目に傾きの推定値が格納されているため.iloc[1]で抽出し,bhatに割り当てている。#6:resの属性.pvaluesは\(p\)値を2つ返すが,1番目に傾きの\(p\)値が格納されているため.iloc[1]で抽出し,pvalに割り当てている。#7:resの属性fittedvaluesは予測値を返すが,それを新たな列(ラベルはTrend)としてdf_tmpに追加している。#8:df_tmpを使い横軸はvar,縦軸はky_ratioの散布図を表示し、その軸をaxに割り当てる。#9:df_tmpを使い横軸はvar,縦軸はky_ratioの回帰直線を表示。その際、メソッド.sort_values('Trend')で列Trendに従って昇順に並び替える。これはトレンド線が正確に表示されるために必要。#10:図のタイトルを設定する。f-stringを使いbhatの値を代入する。:.2fは小数点第2位までの表示を指定。\nは改行の意味。行を変えるので
\nの後に'が必要となる。
#11:f-stringを使いpvalの値を代入する。:.3fは小数点第3位までの表示を指定し,size=20はフォントの大きさの指定。#12:縦軸のラベルの設定。#13:フォントの大きさの指定。#14:横軸のラベルの設定であり,f-stringを使いvarの値を代入している。size=20はフォントの大きさの指定。
3つの図からソロー・モデルの理論的予測はデータと整合性があることが確認できる。ここで注意する点が一つある。式(45)は因果関係を予測している。例えば,貯蓄率が高くなることにより長期的な一人 当たりGDPは増加する。一方,トレンド線は因果関係を示しているのではなく単なる相関関係を表している。ソロー・モデルの因果関係を計量経済学的に検討するにはさまざまな要因の検討が必要になり,本章の域を超える事になる。