発展会計#
1import japanize_matplotlib
2import matplotlib.pyplot as plt
3import numpy as np
4import pandas as pd
5import py4macro
6
7# numpy v1の表示を使用
8np.set_printoptions(legacy='1.21')
9# 警告メッセージを非表示
10import warnings
11warnings.filterwarnings("ignore")
はじめに#
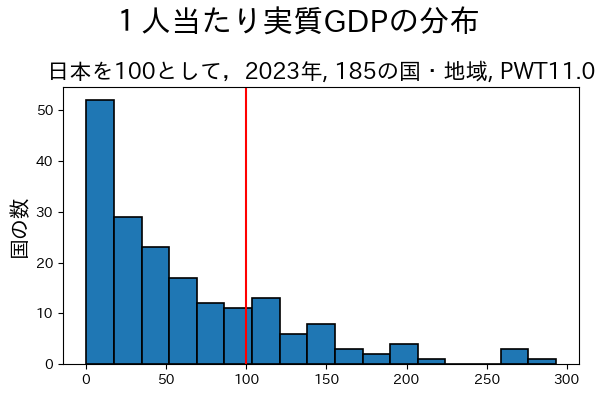
一人当たりGDP(国内総生産)は経済の豊かさを示す一つの尺度として使われるが,下の左の図は2019年の世界経済での一人当たりGDPの分布を示している。日本と他の国・地域との比較を容易にするために、日本の一人当たりGDPを100として相対的な所得分布を表している。日本は38位で、1位であるルクセンブルグの一人当たりGDPは日本のそれより2倍強あり(米国は159.9で10位)、最下位のベネズエラは日本の一人当たりGDPの0.63%である。また、一人当たりGDPが日本の10%に満たない国・地域が107ある。こういった数字が示すように、世界の所得分布は大きな偏りがあり、非常に不平等である。
(問1)なぜある国は豊かで他の国は貧しいのだろうか?
この問いはマクロ経済学の根本的な問いである。この重要な問題を考える上で、経済成長率に関する考察を無視できない。経済成長率とは、一人当たりGDP等の変数がある一定期間(例えば、一年間)にどれだけ変化したかをパーセントで表している。「現在の所得水準は過去に達成した成長率に依存し、またこれからの成長率が将来の所得水準を決定する」という質的な結果は直感的に理解できる。では、成長率と所得水準にはどういった量的な関係があるのだろうか。これを理解するために、Table 1を見てみよう。
成長率 |
2.0% |
2.5% |
3.0% |
|---|---|---|---|
1年後 |
102.0 |
102.5 |
103.0 |
10年後 |
121.9 |
128.0 |
134.4 |
50年後 |
269.2 |
343.7 |
438.4 |
100年後 |
724.5 |
1181.4 |
1921.9 |
現在の一人当たりGDPを100単位として,3つの異なる率で成長した場合、所得がどう変化するかを示している。2%と3%のケースを考えると、成長率が1%上昇するだけで、100年後の所得は約2.7倍に膨らんでいる。では、実際に各国の成長率はどれほど差があるのだろうか。それを示したのが次の図である。
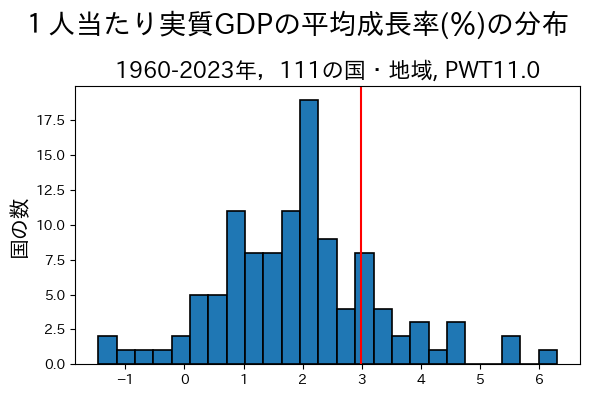
日本の平均成長率は2.99%であり、図では赤い直線で示している。最も高い成長率はChinaの6.31%であり,最も低い成長率はD.R. of the Congoの-1.46%である。実に、最高と最低成長率の差は7.77%ある。また、マイナスの成長率とは一人当たり所得の減少を意味するが、111の国・地域のうち6が約60年の間平均して所得が縮小しているのである。
(問2)なぜ国々の経済成長率は大きく異なるのか?
経済学者は、問1と2に対する完璧な答えを提示できておらず、今でも活発に研究がおこなわれている。この章ではまず問1についてデータと簡単な数式を使い議論する。特に,技術水準と蓄積生産要素(物的資本と人的資本)がどれだけ一人当たりGDPに貢献しているかを考え,その貢献度の違いを使い問1について考察する。
データ#
データはPenn World Talbe 11.0を使うが,ここではデータをインポートするためにpy4macroモジュールを使う。このモジュールにはデータ・セットなどが含まれており,ここではdata関数を使ってデータをインポートする。使い方は次のコードで確認できる。
help(py4macro.data)
Help on function data in module py4macro.py4macro:
data(dataset=None, description=0)
|
| 引数:
| datasets: (文字列)
| 'bigmac': Big Macインデックス
| 'debts':政府負債に関する長期時系列データ
| 'dates': 景気循環日付と拡張・後退期間
| 'ex': 円/ドル為替レートなど
| 'jpn-money': 日本の四半期データ(マネーストックなど)
| 'jpn-q': 日本の四半期データ(GDPなど)
| 'jpn-yr': 日本の年次データ(GDPなど)
| 'mad': country data of Maddison Project Database 2023
| 'mad-region': regional data of Maddison Project Database 2020
| 'pwt': Penn World Table 11.0
| 'weo': IMF World Economic Outlook 2025
| 'world-money': 177ヵ国のマネーストックなど
| 'data1': 書籍「経済学のためのPython入門」用
| 'data2': 書籍「経済学のためのPython入門」用
| 'data3': 書籍「経済学のためのPython入門」用
| 'data4': 書籍「経済学のためのPython入門」用
| 'data5': 書籍「経済学のためのPython入門」用
|
| description (デフォルト:0, 整数型):
| 0: データのDataFrameを返す
| * 全てのデータセット
| 1: 変数の定義を全て表示する
| * 全てのデータセット
| 2: 変数の定義のDataFrameを返す
| * `'pwt'`,`'weo'`のみ
|
| 返り値:
| DataFrame もしくは DataFrameの表示
|
| 例1:py4macro.data('weo')
| -> IMF World Economic OutlookのDataFrameを返す。
|
| 例2:py4macro.data('weo', description=1)
| -> IMF World Economic Outlookの変数定義の全てを表示する。
|
| 例3:py4macro.data('weo', description=2)
| -> IMF World Economic Outlookの変数定義のDataFrameを返す。
|
|
| ----- Penn World Tableについて -------------------------------------------
|
| PWTには以下の列が追加されている。
|
| * oecd:1990年代に始まった中央ヨーロッパへの拡大前にOECDメンバー国であれば1,そうでなければ0
|
| * income_group:世界銀行が所得水準に従って分けた4つのグループ
| High income
| Upper middle income
| Lower middle income
| Low income
|
| * region:世界銀行が国・地域に従って分けた7つのグループ化
| East Asia & Pacific
| Europe & Central Asia
| Latin America & Caribbean
| Middle East & North Africa
| North America
| South Asia
| Sub-Saharan Africa
|
| * continent:南極以外の6大陸
| Africa
| Asia
| Australia
| Europe
| North America
| South America
Note
py4macroを事前にインストールする必要があるが,次のコマンドでインストールすることができる。
pip install py4macro
まず含まれていいる変数の定義を表示してみよう。data()の引数に'pwt'(文字列)とdescription=1を指定する。
py4macro.data('pwt',description=1)
| Variable definition | |
|---|---|
| Identifier variables | NaN |
| countrycode | 3-letter ISO country code |
| country | Country name |
| currency_unit | Currency unit |
| year | Year |
| Real GDP, employment and population levels | NaN |
| rgdpe | Expenditure-side real GDP at chained PPPs (in mil. 2021US$) |
| rgdpo | Output-side real GDP at chained PPPs (in mil. 2021US$) |
| pop | Population (in millions) |
| emp | Number of persons engaged (in millions) |
| avh | Average annual hours worked by persons engaged |
| hc | Human capital index, based on years of schooling and returns to education; see Human capital in PWT9. |
| Current price GDP, capital and TFP | NaN |
| ccon | Real consumption of households and government, at current PPPs (in mil. 2021US$) |
| cda | Real domestic absorption, (real consumption plus investment), at current PPPs (in mil. 2021US$) |
| cgdpe | Expenditure-side real GDP at current PPPs (in mil. 2021US$) |
| cgdpo | Output-side real GDP at current PPPs (in mil. 2021US$) |
| cn | Capital stock at current PPPs (in mil. 2021US$) |
| ck | Capital services levels at current PPPs (USA=1) |
| ctfp | TFP level at current PPPs (USA=1) |
| cwtfp | Welfare-relevant TFP levels at current PPPs (USA=1) |
| National accounts-based variables | NaN |
| rgdpna | Real GDP at constant 2021 national prices (in mil. 2021US$) |
| rconna | Real consumption at constant 2021 national prices (in mil. 2021US$) |
| rdana | Real domestic absorption at constant 2021 national prices (in mil. 2021US$) |
| rnna | Capital stock at constant 2021 national prices (in mil. 2021US$) |
| rkna | Capital services at constant 2021 national prices (2021=1) |
| rtfpna | TFP at constant national prices (2021=1) |
| rwtfpna | Welfare-relevant TFP at constant national prices (2021=1) |
| labsh | Share of labour compensation in GDP at current national prices |
| irr | Real internal rate of return |
| delta | Average depreciation rate of the capital stock |
| Exchange rates and GDP price levels | NaN |
| xr | Exchange rate, national currency/USD (market+estimated) |
| pl_con | Price level of CCON (PPP/XR), price level of USA GDPo in 2021=1 |
| pl_da | Price level of CDA (PPP/XR), price level of USA GDPo in 2021=1 |
| pl_gdpo | Price level of CGDPo (PPP/XR), price level of USA GDPo in 2021=1 |
| Data information variables | NaN |
| i_cig | 0/1/2/3/4: relative price data for consumption, investment and government is extrapolated (0), benchmark (1), interpolated (2), ICP PPP timeseries: benchmark or interpolated (3) or ICP PPP timeseries: extrapolated (4) |
| i_xm | 0/1/2: relative price data for exports and imports is extrapolated (0), benchmark (1) or interpolated (2) |
| i_xr | 0/1: the exchange rate is market-based (0) or estimated (1) |
| i_outlier | 0/1: the observation on pl_gdpe or pl_gdpo is not an outlier (0) or an outlier (1) |
| i_irr | 0/1/2/3: the observation for irr is not an outlier (0), may be biased due to a low capital share (1), hit the lower bound of 1 percent (2), or is an outlier (3) |
| cor_exp | Correlation between expenditure shares of the country and the US (benchmark observations only) |
| Shares in CGDPo | NaN |
| csh_c | Share of household consumption at current PPPs |
| csh_i | Share of gross capital formation at current PPPs |
| csh_g | Share of government consumption at current PPPs |
| csh_x | Share of merchandise exports at current PPPs |
| csh_m | Share of merchandise imports at current PPPs |
| csh_r | Share of residual trade and GDP statistical discrepancy at current PPPs |
| Price levels, expenditure categories and capital | NaN |
| pl_c | Price level of household consumption, price level of USA GDPo in 2021=1 |
| pl_i | Price level of capital formation, price level of USA GDPo in 2021=1 |
| pl_g | Price level of government consumption, price level of USA GDPo in 2021=1 |
| pl_x | Price level of exports, price level of USA GDPo in 2021=1 |
| pl_m | Price level of imports, price level of USA GDPo in 2021=1 |
| pl_n | Price level of the capital stock, price level of USA in 2021=1 |
| pl_k | Price level of the capital services, price level of USA=1 |
countrycodeは3つのアルファベットで表した標準的な国名コードであり,日本はJPNとなる。よく使われるので,このサイトを参考に主な国の表記を覚えておくと良いだろう。
Tip
description=1は表示するだけなので,DataFrameとして扱いたい場合はdescription=2とする。
'pwt'だけを引数に使うとデータ自体を読み込むことになる。
df = py4macro.data('pwt')
次に.head()を使って最初の5行を表示してみよう。
df.head()
| countrycode | country | oecd | income_group | region | continent | year | rgdpe | rgdpo | pop | ... | csh_x | csh_m | csh_r | pl_c | pl_i | pl_g | pl_x | pl_m | pl_n | pl_k | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ABW | Aruba | 0 | High income | Latin America & Caribbean | North America | 1950 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | ABW | Aruba | 0 | High income | Latin America & Caribbean | North America | 1951 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | ABW | Aruba | 0 | High income | Latin America & Caribbean | North America | 1952 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | ABW | Aruba | 0 | High income | Latin America & Caribbean | North America | 1953 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | ABW | Aruba | 0 | High income | Latin America & Caribbean | North America | 1954 | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
5 rows × 54 columns
dfに含まれているのは年次データだが、最初と最後の年を調べてみる。
first_yr = df['year'].min() # 最初の年
latest_yr = df['year'].max() # 最後の年
print(f'データセットには{first_yr}から{latest_yr}年が含まれている')
データセットには1950から2023年が含まれている
また,次の変数は上の定義のリストには含まれていないので,ここで簡単に紹介する。
oecd:1990年代に始まった中央ヨーロッパへの拡大前にOECDメンバー国であれば1,そうでなければ0income_group:世界銀行は所得水準に従って国を次の4つに分けている。High income
Upper middle income
Lower middle income
Low income
region:世界銀行が国・地域に従って分けた7つのグループ化East Asia & Pacific
Europe & Central Asia
Latin America & Caribbean
Middle East & North Africa
North America
South Asia
Sub-Saharan Africa
continent:南極以外の6大陸Africa
Asia
Australia
Europe
North America
South America
2023年のデータを使い内訳を確認してみよう。その際に便利なのがDataFrameとSeriesのメソッド.value_counts()である。これを使うと簡単に要素の個数や頻度を表示できる。
まずoecdを考えるが,条件に従って行を抽出しその数を数えてみる。
cond = ( df['year']==latest_yr )
df.loc[cond,'oecd'].value_counts()
oecd
0 161
1 24
Name: count, dtype: int64
oecdには24カ国あることがわかる。
同様にincome_group,region,continentの内訳を確認してみよう。
df.loc[cond,'income_group'].value_counts()
income_group
High income 65
Upper middle income 48
Lower middle income 44
Low income 26
Name: count, dtype: int64
df.loc[cond,'region'].value_counts()
region
Europe & Central Asia 48
Sub-Saharan Africa 47
Latin America & Caribbean 40
Middle East & North Africa 20
East Asia & Pacific 20
South Asia 7
North America 3
Name: count, dtype: int64
df.loc[cond,'continent'].value_counts()
continent
Africa 51
Asia 48
Europe 39
North America 32
South America 12
Australia 3
Name: count, dtype: int64
.value_counts()に引数normalize=Trueを追加すると,頻度(パーセント)として表示できる。
属性.columnsを使い全ての列名を表示してみよう。
df.columns
Index(['countrycode', 'country', 'oecd', 'income_group', 'region', 'continent',
'year', 'rgdpe', 'rgdpo', 'pop', 'emp', 'avh', 'hc', 'ccon', 'cda',
'cgdpe', 'cgdpo', 'cn', 'ck', 'ctfp', 'cwtfp', 'rgdpna', 'rconna',
'rdana', 'rnna', 'rkna', 'rtfpna', 'rwtfpna', 'labsh', 'irr', 'delta',
'xr', 'pl_con', 'pl_da', 'pl_gdpo', 'i_cig', 'i_xm', 'i_xr',
'i_outlier', 'i_irr', 'cor_exp', 'csh_c', 'csh_i', 'csh_g', 'csh_x',
'csh_m', 'csh_r', 'pl_c', 'pl_i', 'pl_g', 'pl_x', 'pl_m', 'pl_n',
'pl_k'],
dtype='object')
また任意の列を選択するとメソッド.unique()が使えるようになる。これを使うことにより,選択した列に重複したデータがある場合,ユニークなものだけを抽出できる。このメソッドを使ってデータ・セットに含まれる国・地域名を確認してみよう。
country_list = df.loc[:,'country'].unique()
country_list
array(['Aruba', 'Angola', 'Anguilla', 'Albania', 'United Arab Emirates',
'Argentina', 'Armenia', 'Antigua and Barbuda', 'Australia',
'Austria', 'Azerbaijan', 'Burundi', 'Belgium', 'Benin',
'Burkina Faso', 'Bangladesh', 'Bulgaria', 'Bahrain', 'Bahamas',
'Bosnia and Herzegovina', 'Belarus', 'Belize', 'Bermuda',
'Bolivia (Plurinational State of)', 'Brazil', 'Barbados',
'Brunei Darussalam', 'Bhutan', 'Botswana',
'Central African Republic', 'Canada', 'Switzerland', 'Chile',
'China', "Côte d'Ivoire", 'Cameroon', 'D.R. of the Congo', 'Congo',
'Colombia', 'Comoros', 'Cabo Verde', 'Costa Rica', 'Curaçao',
'Cayman Islands', 'Cyprus', 'Czechia', 'Germany', 'Djibouti',
'Dominica', 'Denmark', 'Dominican Republic', 'Algeria', 'Ecuador',
'Egypt', 'Spain', 'Estonia', 'Ethiopia', 'Finland', 'Fiji',
'France', 'Gabon', 'United Kingdom', 'Georgia', 'Ghana', 'Guinea',
'Gambia', 'Guinea-Bissau', 'Equatorial Guinea', 'Greece',
'Grenada', 'Guatemala', 'Guyana', 'China, Hong Kong SAR',
'Honduras', 'Croatia', 'Haiti', 'Hungary', 'Indonesia', 'India',
'Ireland', 'Iran (Islamic Republic of)', 'Iraq', 'Iceland',
'Israel', 'Italy', 'Jamaica', 'Jordan', 'Japan', 'Kazakhstan',
'Kenya', 'Kyrgyzstan', 'Cambodia', 'Saint Kitts and Nevis',
'Republic of Korea', 'Kuwait', "Lao People's DR", 'Lebanon',
'Liberia', 'Saint Lucia', 'Sri Lanka', 'Lesotho', 'Lithuania',
'Luxembourg', 'Latvia', 'China, Macao SAR', 'Morocco',
'Republic of Moldova', 'Madagascar', 'Maldives', 'Mexico',
'North Macedonia', 'Mali', 'Malta', 'Myanmar', 'Montenegro',
'Mongolia', 'Mozambique', 'Mauritania', 'Montserrat', 'Mauritius',
'Malawi', 'Malaysia', 'Namibia', 'Niger', 'Nigeria', 'Nicaragua',
'Netherlands', 'Norway', 'Nepal', 'New Zealand', 'Oman',
'Pakistan', 'Panama', 'Peru', 'Philippines', 'Poland', 'Portugal',
'Paraguay', 'State of Palestine', 'Qatar', 'Romania',
'Russian Federation', 'Rwanda', 'Saudi Arabia', 'Sudan', 'Senegal',
'Singapore', 'Sierra Leone', 'El Salvador', 'Somalia', 'Serbia',
'South Sudan', 'Sao Tome and Principe', 'Suriname', 'Slovakia',
'Slovenia', 'Sweden', 'Eswatini', 'Sint Maarten (Dutch part)',
'Seychelles', 'Syrian Arab Republic', 'Turks and Caicos Islands',
'Chad', 'Togo', 'Thailand', 'Tajikistan', 'Turkmenistan',
'Trinidad and Tobago', 'Tunisia', 'Türkiye', 'Taiwan',
'U.R. of Tanzania: Mainland', 'Uganda', 'Ukraine', 'Uruguay',
'United States', 'Uzbekistan', 'St. Vincent and the Grenadines',
'Venezuela (Bolivarian Republic of)', 'British Virgin Islands',
'Viet Nam', 'Yemen', 'South Africa', 'Zambia', 'Zimbabwe'],
dtype=object)
類似するメソッドに.nunique()がある。これを使うと,ユニークなデータの数を確認できる。
df.loc[:,'country'].nunique()
185
185の国・地域が含まれるということである。unique()でデータの年を確認することもできる。
df['year'].unique()
array([1950, 1951, 1952, 1953, 1954, 1955, 1956, 1957, 1958, 1959, 1960,
1961, 1962, 1963, 1964, 1965, 1966, 1967, 1968, 1969, 1970, 1971,
1972, 1973, 1974, 1975, 1976, 1977, 1978, 1979, 1980, 1981, 1982,
1983, 1984, 1985, 1986, 1987, 1988, 1989, 1990, 1991, 1992, 1993,
1994, 1995, 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004,
2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015,
2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023])
最初の年は1950であり、最後の年は2023であることが分かる。
データを扱う際,必ずしもデータ・セットは完璧な形で提供されているわけではないことを念頭に置く必要がある。dfの場合,必ずしも全ての国で全ての年のデータが揃っているわけではない。それを確認する必要があるが,役に立つのがdfのメソッドinfo()である。
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 13690 entries, 0 to 13689
Data columns (total 54 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 countrycode 13690 non-null object
1 country 13690 non-null object
2 oecd 13690 non-null int64
3 income_group 13542 non-null object
4 region 13690 non-null object
5 continent 13690 non-null object
6 year 13690 non-null int64
7 rgdpe 11201 non-null float64
8 rgdpo 11201 non-null float64
9 pop 11201 non-null float64
10 emp 10307 non-null float64
11 avh 5015 non-null float64
12 hc 9217 non-null float64
13 ccon 11201 non-null float64
14 cda 11201 non-null float64
15 cgdpe 11201 non-null float64
16 cgdpo 11201 non-null float64
17 cn 11028 non-null float64
18 ck 7747 non-null float64
19 ctfp 6988 non-null float64
20 cwtfp 6988 non-null float64
21 rgdpna 11201 non-null float64
22 rconna 11201 non-null float64
23 rdana 11201 non-null float64
24 rnna 11028 non-null float64
25 rkna 7747 non-null float64
26 rtfpna 6988 non-null float64
27 rwtfpna 6988 non-null float64
28 labsh 8215 non-null float64
29 irr 8201 non-null float64
30 delta 11028 non-null float64
31 xr 11201 non-null float64
32 pl_con 11201 non-null float64
33 pl_da 11201 non-null float64
34 pl_gdpo 11201 non-null float64
35 i_cig 11201 non-null object
36 i_xm 11201 non-null object
37 i_xr 11201 non-null object
38 i_outlier 11201 non-null object
39 i_irr 8201 non-null object
40 cor_exp 2112 non-null float64
41 csh_c 11201 non-null float64
42 csh_i 11201 non-null float64
43 csh_g 11201 non-null float64
44 csh_x 11201 non-null float64
45 csh_m 11201 non-null float64
46 csh_r 11201 non-null float64
47 pl_c 11201 non-null float64
48 pl_i 11201 non-null float64
49 pl_g 11201 non-null float64
50 pl_x 11201 non-null float64
51 pl_m 11201 non-null float64
52 pl_n 11028 non-null float64
53 pl_k 7747 non-null float64
dtypes: float64(42), int64(2), object(10)
memory usage: 5.6+ MB
この出力の読み方についてはPandasの章で解説したので,ここでリピートする必要はないと思うが,次の点が重要となる。
行のインデックスは0から13689まであり,合計13690行ある。
countrycodeをみると13690non-nullとなっており,non-nullは「非欠損値(欠損値ではない)」となるため,その列の欠損値は0であることを意味する。一方,hcは9217non-nullとなっており,13690\(-\)9217non-null\(=\)4473の欠損値が存在する。float64は浮動小数点型データであり,objectは文字列のデータと考えて良いだろう。
また、objectに関しては少し注意が必要となる。列に文字列が1つ混じっていて,他はfloatであってもobjectとなるので注意が必要である。次の例がそれを示している。
pd.DataFrame({'a':[1,2,3,4,5,'1']}).info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6 entries, 0 to 5
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 a 6 non-null object
dtypes: object(1)
memory usage: 180.0+ bytes
そしてもう一つ。hcには欠損値があると分かったが,その定義を個別で確認したい場合,py4macroの引数description=2を使うとDataFrameが返されるので,それを使うと良いだろう。
teigi = py4macro.data('pwt', description=2)
teigi.loc[['hc'],:]
| Variable definition | |
|---|---|
| hc | Human capital index, based on years of schooli... |
ただ,これだと定義の説明が全て表示できない。その場合はpy4macro.show()関数を使うとフルに表示できる。
py4macro.show(teigi.loc[['hc'],:])
| Variable definition | |
|---|---|
| hc | Human capital index, based on years of schooling and returns to education; see Human capital in PWT9. |
Note
上のコードで.loc['hc',:]とするとSeriesが返されるので,表示が少し異なることになる。
実際にデータを使う前に,含まれているGDPの変数について簡単に説明する。世界中の経済のGDPを比較可能な形でデータを作成するのは非常に難しい。経済によって消費・生産・輸出・輸入する財の種類・量も違えば,価格も違う。それに購買力平価(PPPs; Purchasing Power Parities; PWTで使うPPPs)を使って経済間のGDPを共通の貨幣単位に変換したとしても,時系列的に実質化するには更なる調整が必要となる。またGDPの3面等価により,概念的には産出,支出,所得データを使いGDPを計算することができるが,どのデータを使うかという点も考慮する必要がある。このような問題に対処するために,PWTには5つのGDPの変数が用意されている。
使える過去のPPPsのデータに基づき経済間の価格の違いを考慮している。
cgdpo:産出データに基づいている。それぞれの年の物価水準は米国の物価水準に対しての相対価格として表されているため,そういう意味において経済間では実質と言える。しかし,時系列的には名目。ある年で経済間の生産能力水準の比較に適している。cgdpe:支出データに基づいている。cgdpoと同様に経済間では実質と言える。しかし,時系列的には名目。ある年で経済間の生活水準の比較に適している。rgdpo:産出データに基づいている。cgdpoと同様に経済間では実質と言える。また,時系列的には実質。ある期間で経済間の生産能力水準の比較に適している。rgdpe:支出データに基づいている。cgdpoと同様に経済間では実質と言える。また,時系列的には実質。ある期間で経済間の生活水準の比較に適している。上記4つの変数は,過去のPPPsのデータに基づいて計算されているため,成長率を計算するとPPPsに影響を受けることになる。従って,成長率の比較には使わない方が良いだろう。
ある基準年のPPPsだけに基づき経済間の価格の違いを考慮している。
rgdpna:それぞれの経済の国民経済計算を使っており,時系列的には実質。GDPの成長率の比較に適している。
発展会計の考え方#
経済間の所得格差の要因を探るために,次の生産関数を考えよう。
\(i\):経済
i\(Y_i\):GDP
\(K_i\):物的資本
\(A_i\):全要素生産性(TFP)
\(H_i\):労働者一人当たりの人的資本
\(h_i\):労働者一人当たりの平均労働時間
\(L_i\):労働者数
GDPは労働,物的人的資本とTFPによって決定されると考える,ということである。このアプローチは大雑把な印象を否めないが,データを使う事により,重要な知見を得ることが可能となる。次に,生産関数を一人当たりに書き換えよう。
\(y_i=\dfrac{Y_i}{L_i}\):一人当たりGDP
\(k_i=\dfrac{K_i}{L_i}\):一人当たり物的資本
この式を使い経済間の一人当たりGDPの違いを考察する事になる。即ち,\(A_i\),\(k_i\),\(h_i\),\(H_i\)の違いを使って\(y_i\)の違いを説明しようという事である。以下では,\(h_iH_i\)と\(k_i\),\(h_i\),\(H_i\)を合わせた項を次のように呼ぶ事にする。
使うデータ・セットには,\(y_i\),\(k_i\),\(h_i\)に対応する変数があり,蓄積生産要素がどれだけ一人当たりGDPに寄与するかを数値で表すことができる。一方,全要素生産性は次の式で求めることができる。
これらの式とデータを使って,一人当たりGDPに対する蓄積生産要素と全要素生産性の寄与度を数量化する事になる。
Note
生産関数(1)の仮定のもとで\(A_i\)が上昇したとしよう。物的人的資本の限界生産性が上昇するため,\(k_i\)と\(H_i\)は増加することになる。即ち,\(A_i\)の上昇により一人当たりGDPは上昇するが,間接的に\(k_i\)と\(H_i\)も増加させ\(y_i\)が増加する。これにより本来\(A_i\)による効果が\(k_i\)と\(H_i\)の寄与度に算入されることになり,全要素生産性の寄与度の過小評価につながる可能性がある。この問題は練習問題で取り上げることにする。
データ・セットに含まれるどの変数を使うかという問題があるが,ここでは次のデータを使うことにする。
rgdpo:生産面から計算したGDP(current PPPs; in mil. 2011US$)経済間では一定な価格を使い計算されているが、時系列的には実質
ある年に経済間の比較をするのに適している
emp:雇用者数(in millions)avh:年間平均労働時間ck:資本サービス水準(current PPPs (USA=1))資本ストックを生産に使うことにより得るサービス
USA=1と基準化されているが,米国との比率を考えるため,基準化による問題はなくなる。
データ・セットには次に2つが含まれている。
cn:資本ストック(current PPPs, in mil. 2011US$,タクシーを例にすると車体の価額)。ck:資本サービス(current PPPs, USA=1,タクシーを例にするとそのサービス(走行距離など))。
hc:一人当たり人的資本の指標教育年数と教育の収益から計算されている
式に当てはめると次のようになる。
一人当たりGDP:\(y_i\equiv\dfrac{Y_i}{L_i}=\)
cgdpo/emp一人当たり資本:\(k_i\equiv\dfrac{K_i}{L_i}=\)
ck/emp労働者一人当たり人的資本サービス:\(h_iH_i=\)
avhxhc資本の所得シャア:\(\alpha=1/3\)を仮定
これに従ってコードを書いていこう。
# 資本の所得シャア
a=1/3.0
# 労働者一人当たりGDP
df['y'] = df['cgdpo'] / df['emp']
# 一人当たり資本
df['kpc'] = df['ck'] / df['emp']
# 蓄積生産要素
df['factors'] = df['kpc']**a * ( df['hc']*df['avh'] )**(1-a)
# 全要素生産性
df['tfp'] = df['y'] / df['factors']
2023年#
2023年だけを抽出する。
cond = ( df['year']==latest_yr )
df = df.loc[cond,:]
一人当たりGDP#
わかりやすくするために,全ての国の一人当たりGDPを米国の一人当たりGDPで割り、米国を1(基準)として議論を進める事にする。先に,米国だけのデータを抽出する。
cond = ( df['country']=="United States" )
us = df.loc[cond,:]
次に,米国を基準とした相対的な一人当たりGDP作成し,dfに新たな列として代入によう。
df['y_relative'] = df['y'] / us['y'].iloc[0]
コードの説明
右辺のdf['y']とus['y']はSeriesだが,要素数が異なる。従って,分母のus['y']をそのまま使うとエラーが発生する。iloc[0]を使うことにより,us['y']に一つだけある要素を抽出し,エラーの発生を防いでいる。iloc[0]の代わりにNumPyのarrayに変換するメソッドである.to_numpy()を使うことも可能である。
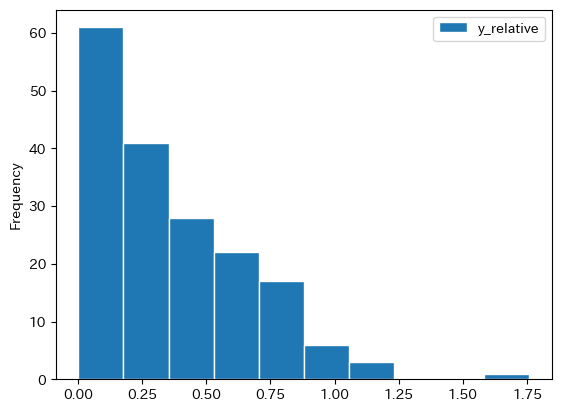
ヒストグラムをプロットしてみよう。
df.plot.hist(y='y_relative', edgecolor='white')
pass
Matplotlibを直接使う場合
plt.hist('y_relative', data=df, edgecolor='white')
pass
fig, ax = plt.subplots()
ax.hist('y_relative', data=df, edgecolor='white')
pass
fig = plt.figure()
ax = fig.add_subplot()
ax.hist('y_relative', data=df, edgecolor='white')
pass
最小値と最大値を計算してみよう。
df['y_relative'].min(), df['y_relative'].max()
(0.0019305570483580342, 1.7583029058702404)
最貧国は米国の一人当たりGDPの約0.193%である。一方、米国の約1.758倍の国もある。
物的資本#
物的資本についても同様に,全ての国のk_pcを米国のk_pcで割り基準化する。
df['kpc_relative'] = df['kpc'] / us['kpc'].iloc[0]
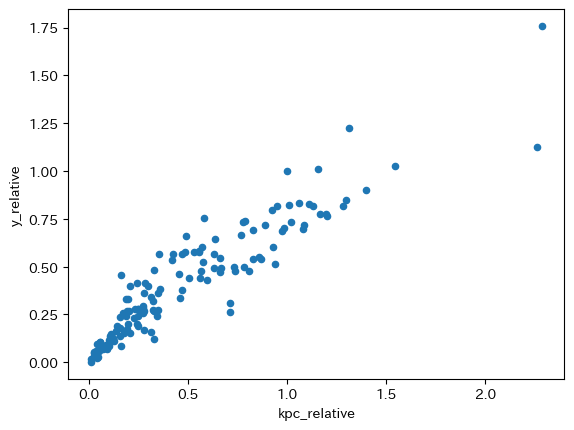
データを散布図で確認しよう。
df.plot.scatter(x='kpc_relative', y='y_relative')
pass
Matplotlibを直接使う場合
plt.scatter(x='kpc_relative', y='y_relative', data=df)
pass
fig, ax = plt.subplots()
ax.scatter(x='kpc_relative', y='y_relative', data=df)
pass
fig = plt.figure()
ax = fig.add_subplot()
ax.scatter(x='kpc_relative', y='y_relative', data=df)
pass
正の関係があることが確認できる。またデータの曲線トレンドは凹関数のようである。y_relativeに対するk_pc_relative増加の影響は,k_pc_relativeが低いと大きく,k_pc_relativeが高いと小さくなる。即ち,資本の限界生産性の逓減の反映と考えられる。ただ,この効果のみで上の図を解釈するには問題がある。第一に,異なる経済のクロスセクション・データ(横断面データ)であるため,経済間の様々な異質性が反映されている。即ち,全ての観測値は同じ生産関数から生成されている訳ではない。第二に,資本の限界生産性の逓減という概念は,労働や他の投入が一定のもとでの比較静学の結果である。しかし,他の投入は一定に固定されている訳ではない。これらを考慮しつつ図の解釈をするべきではあるが,データの裏には資本の限界生産性の逓減のメカニズムが働いていると考えるのは自然であろう。
人的資本サービス#
まず人的資本hcを考察する事にする。それにより労働時間avhの効果も理解できるだろう。
全ての国のhcを米国のhcで割り,米国を1とする人的資本インデックスを作成する。
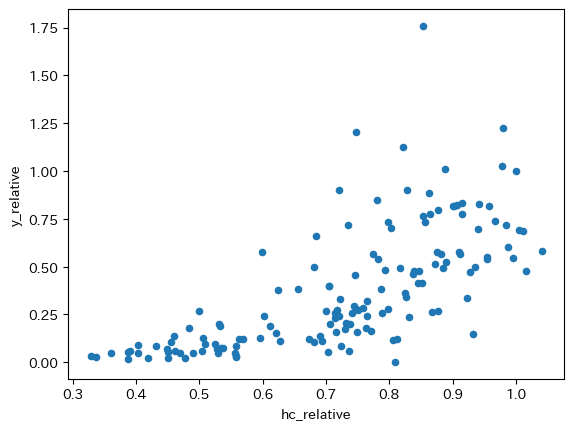
df['hc_relative'] = df['hc'] / us['hc'].iloc[0]
散布図で確認してみよう。
df.plot.scatter(x='hc_relative', y='y_relative')
pass
Matplotlibを直接使う場合
plt.scatter(x='hc_relative', y='y_relative', data=df)
pass
fig, ax = plt.subplots()
ax.scatter(x='hc_relative', y='y_relative', data=df)
pass
fig = plt.figure()
ax = fig.add_subplot()
ax.scatter(x='hc_relative', y='y_relative', data=df)
pass
正の関係があることがわかる。即ち,人的資本ストックが高ければ,一人当たり所得も増えるという事であり,非常に直感的でもある。一方,物的資本と比べると,曲線トレンドは凸関数になっている。裏にあるメカニズムとして様々なことが想定できる。
労働者のスキルが高いため,同じ時間でより多くの財を生産できる。
学習能力が高いため,生産活動をとおして更にスキル向上,生産性向上につながる(学習効果)。
人的資本には,人に教える能力も含まれる(例えば,教師)。それにより,さらなる人的資本ストックの増加につながる。
人から学ぶ能力も高いため,技術・知識の伝播の速度を速め,経済全体の生産性を向上させる。
新しい技術・知識の創出,即ち,イノベーションを起こす必要不可欠な要素である。
海外からの技術移転にも貢献する。
リスクに対する理解が深まり,リスクは高いがより生産性が高い活動への投資につながる。
などなど
ここで見えてくるのは人的資本の「外部性」の効果である。典型的な例が,学習効果である。人的資本が増えると,生産量が高くなり学習する機会が増え,更なる人的資本の増加につながる。それが更なる生産量の増加となり,相乗効果として凸関数トレンドとして現れていると解釈できる。また,能力が上がれば,それだけ新しい知識や技術をより簡単に吸収することが可能となるだろう。更には,周りに優れた人に囲まれて仕事や勉強をすれば,それに引っ張られて自分の能力も増してくる事になるのは多くの人が経験していることではないだろうか。労働者はこのような効果を意識して(例えば,他人への効果を考慮して)行動しているわけではない。即ち,外部性が一つの基本メカニズムとして働いているという解釈が成り立つ。
一方で,違う見方を可能である。閾値効果である。図を見ると,h_relativeが低いところから増加してもy_relativeは大きく増加しないが,0.7あたりから増加率が増している。0.7付近で接続される2つの直線からなる折れ線グラフのようなトレンドが想定できるのではないだろうか。変数hcは,教育年数が一つの決定要因となっており,hcが低い経済では初等教育はある程度整っているが,高等教育が十分ではないと考えられる。従って,初等教育よりも高等教育の方が生産により大きな効果をもたらすとも考えられる。
人的資本の効果がある程度わかったので,次に人的資本サービスについて考えよう。全ての国のhavxhcを米国のhavxhcで割り基準化する。
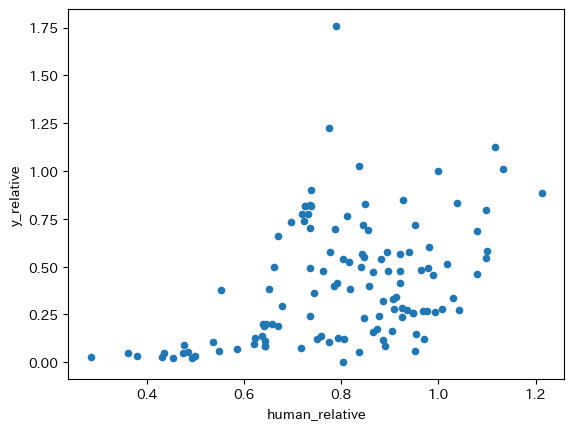
df['human_relative'] = ( df['avh']*df['hc'] ) / \
( us['avh']*us['hc'] ).iloc[0]
散布図で確認してみよう。
df.plot.scatter(x='human_relative', y='y_relative')
pass
Matplotlibを直接使う場合
plt.scatter(x='human_relative', y='y_relative', data=df)
pass
fig, ax = plt.subplots()
ax.scatter(x='human_relative', y='y_relative', data=df)
pass
fig = plt.figure()
ax = fig.add_subplot()
ax.scatter(x='human_relative', y='y_relative', data=df)
pass
正の関係であることは変わらないが,相関度は減少している。これは労働時間の影響であるり,一人当たりGDPとの散布図をプロットして確認してみよう。
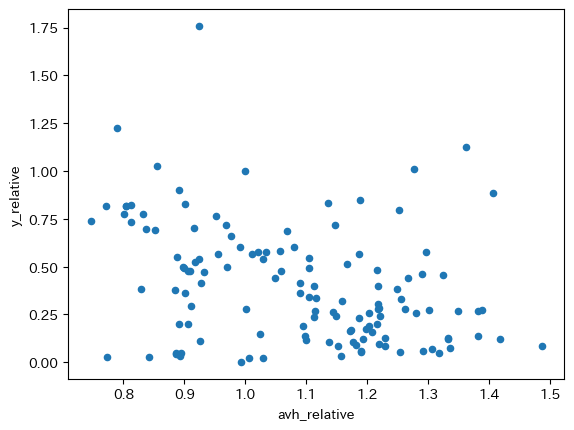
df['avh_relative'] = df['avh'] / us['avh'].iloc[0]
df.plot.scatter(x='avh_relative', y='y_relative')
pass
Matplotlibを直接使う場合
plt.scatter(x='avh_relative', y='y_relative', data=df)
pass
fig, ax = plt.subplots()
ax.scatter(x='avh_relative', y='y_relative', data=df)
pass
fig = plt.figure()
ax = fig.add_subplot()
ax.scatter(x='avh_relative', y='y_relative', data=df)
pass
負の相関関係にあると言えるだろう。即ち,豊かな経済では労働時間が短くなる傾向にある。この傾向は,ミクロ経済学の授業で習った消費者の労働供給モデルを考えて解釈することができる。所得が上昇すると,所得効果により労働供給は減少するが,代替効果により労働時間は上昇する。上の図は,所得効果が代替効果を上回っている結果の反映と考えることが可能である。一方で,経済間では所得だけではなく他の要因も異なることも念頭においておこう。いずれにしろ,労働時間の負の関係により,人的資本サービスと一人当たりGDPの相関は弱くなっている。
全要素生産性#
米国を1に基準化して一人当たりGDPと全要素生産性との関係を図示する。
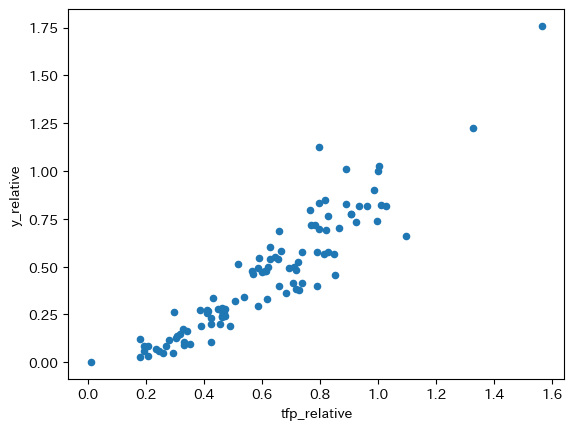
df['tfp_relative'] = df['tfp'] / us['tfp'].iloc[0]
df.plot.scatter(x='tfp_relative', y='y_relative')
pass
Matplotlibを直接使う場合
plt.scatter(x='tfp_relative', y='y_relative', data=df)
pass
fig, ax = plt.subplots()
ax.scatter(x='tfp_relative', y='y_relative', data=df)
pass
fig = plt.figure()
ax = fig.add_subplot()
ax.scatter(x='tfp_relative', y='y_relative', data=df)
pass
正の相関関係にあることは明らかであり,直線のトレンドであることがわかる。物的資本の場合は凹関数トレンドで,限界生産性の逓減の反映とも解釈できた。人的資本の場合は凸関数トレンドで,外部性の効果が示唆された。全要素生産性の直線トレンドの解釈はどうなるのだろう。まず,物的資本のように,限界生産性の逓減があれば凹型トレンドになるはずだが,それを抑えるメカニズムが働いていると考えられる。それが正の外部性の存在である。
全要素生産性は,蓄積生産要素で説明できない一人当たりGDPとして定義されているが,広く使われる解釈が技術水準である。技術水準はイノベーションなどにより決定され,外部性の役割が大きいと理解されている。それを説明するために,アイザック・ニュートンが言ったとされる次の引用を考えてみよう。
If I have seen further, it is by standing on the shoulders of Giants.
ここでのhave seen furtherとはニュートンの天才的な能力・発見を指し,the shoulders of Giantsは先人が築き上げた知識・知見を意味する。ここで重要な点は,ニュートンは殆ど無料(書籍代や読書の機会費用はあるだろうが)で当時までに蓄積された知識を使うことができたということである。また多くの「先人」はニュートンがアイデアを参考にするとは想定していない,もしくはアイデアを使う対価を受け取っていないと思われれ,まさしく正の外部性が存在している(研究開発には負の外部性もある)。このようなことは,今でも発生している。新薬や新しいくゲーム・ソフトを作る場合,まず市場にある財を参考にする。知的財産権で守られているためコピー商品は違法だが,特許で開示されている技術やデザインなどを参考に新たな財を作り出すことは日常茶飯事である。この考えを使って上のデータを解釈してみよう。全世界的に技術水準が低ければ,他から学ぶ土壌が乏しく,TFPの一人当たりGDPに対する影響は限定的になる。一方,経済間の技術水準に大きな差がある場合,遅れている経済は進んでいる経済から学ぶことができる。更には,技術水準が高い経済同士も異なる考え方などをお互いから多くを学ぶ環境が存在することになる。これにより,TFPの効果はより大きなものとなって現れていると考えられ,技術水準の限界生産性の逓減が中和されることにより直線トレンドとしてあらわれていると解釈できる。
関連する問題として,生産関数の仮定と全要素生産性の関係について次の点を付け加えておく。TFPを計算する上でコブ・ダグラス生産関数を使ったが,規模に対して収穫一定を仮定している。もしこの仮定が間違っていて,規模に関して収穫逓増が正しい場合どのようなバイアスが発生するのだろうか。この点を明らかにするために,真の生産関数が次式で与えられるとしよう。
\(\mu=1\)を仮定したわけだが,\(\mu>1\)の場合は規模に関して収穫逓増となる。\(\tilde{A}_i\)は真のTFPを指しており,\(\mu=1\)と\(\mu>1\)の場合のTFPの比率は次の式で表される。
\(K_i^\alpha H_i^{1-\alpha}>1\)と考えると,収穫一定のTFPは真のTFPを過大評価する事がわかる。何が起こっているのだろうか。\(\mu>1\)の場合に収穫一定を仮定すると,
となり,蓄積生産要素の効果が過小評価されることになる。これにより物的人的資本の効果の一部をTFPの貢献だと間違って判断しTFPの過大評価になっている。では,なぜ規模に関して収穫逓増になり得るのだろうか。それが技術水準や蓄積生産要素の外部性である。技術水準と人的資本の外部性について簡単に説明したが,物的資本ストックも外部性を発生させると考えられる。物的資本ストックが増えると一人当たりGDPを増加させる。それにより,人的資本の学習効果を強める事になる。また研究開発のヒントを与えるようなきっかけにもなるかもしれない。そのような相乗効果により規模に関して収穫逓増になる生産関数を想定することも可能である。しかし多くの研究では規模に関して収穫一定の下で議論が進められており,以下ではそれを踏襲して\(\mu=1\)とする。
相関係数#
一人当たりGDPと全要素生産性の散布図から,両変数の相関度は非常に高いと思われる。相関係数を計算してみよう。
df.loc[:,['y_relative','tfp_relative']].corr()
| y_relative | tfp_relative | |
|---|---|---|
| y_relative | 1.000000 | 0.928328 |
| tfp_relative | 0.928328 | 1.000000 |
コードの説明
.corr()は相関係数を計算するメソッド
y_relativeとtfp_relativeの相関係数は約0.928であり、非常に高いことがわかる。
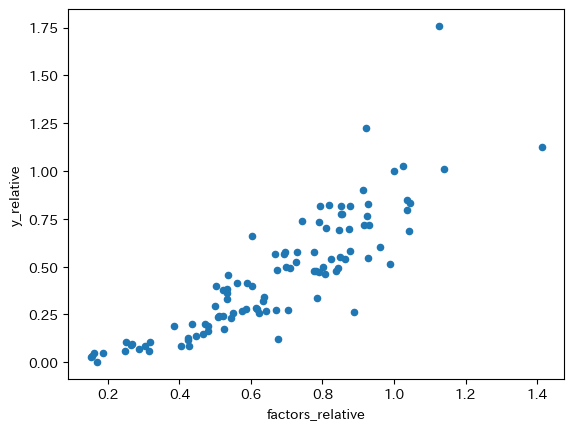
次に,蓄積生産要素と一人当たりGDPの散布図を作成し,相関係数を計算してみよう図示する。
df['factors_relative'] = df['factors'] / us['factors'].iloc[0]
df.plot.scatter(x='factors_relative', y='y_relative')
pass
Matplotlibを直接使う場合
plt.scatter(x='factors_relative', y='y_relative', data=df)
pass
fig, ax = plt.subplots()
ax.scatter(x='factors_relative', y='y_relative', data=df)
pass
fig = plt.figure()
ax = fig.add_subplot()
ax.scatter(x='factors_relative', y='y_relative', data=df)
pass
視覚的には,TFPと比べて相関度は若干低いようである。コードで確認しよう。
df.loc[:,['y_relative','factors_relative']].dropna().corr()
| y_relative | factors_relative | |
|---|---|---|
| y_relative | 1.000000 | 0.862849 |
| factors_relative | 0.862849 | 1.000000 |
TFPより相関係数は低いことが確認できた。
全要素生産性と蓄積生産要素の寄与度#
全要素生産性と蓄積生産要素はそれぞれ一人当たりGDPにどれだけ寄与しているかを考えるために,次の方法を考える。まず生産関数を使い以下を定義する。
ここで
\(R_i^y\):米国を基準とした相対所得
\(R_i^{\text{tfp}}\):米国を基準とした相対全要素生産性
\(R_i^{\text{factors}}\):米国を基準とした相対蓄積生産要素
これらの変数とdfの列は次のように対応している。
\(R_i^y\):
y_relative\(R_i^{\text{tfp}}\):
tfp_relative\(R_i^{\text{factors}}\):
factors_relative
次に(4)の両辺に対数を取ると次式となる。
ここで,
実際に変数を作成しよう。
df['y_relative_log'] = np.log( df['y_relative'] )
df['tfp_relative_log'] = np.log( df['tfp_relative'] )
df['factors_relative_log'] = np.log( df['factors_relative'] )
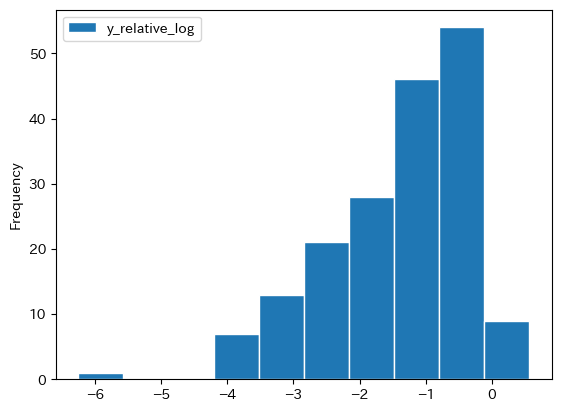
視覚的にy_relative_logの分布を確認するためにヒストグラムをプロットしてみる。
df.plot.hist(y='y_relative_log', edgecolor='white')
pass
Matplotlibを直接使う場合
plt.hist('y_relative_log', data=df, edgecolor='white')
pass
fig, ax = plt.subplots()
ax.hist('y_relative_log', data=df, edgecolor='white')
pass
fig = plt.figure()
ax = fig.add_subplot()
ax.hist('y_relative_log', data=df, edgecolor='white')
pass
0.0が米国となる。対数を使うと,貧しい国の分布がより明確になるのではないだろうか。
対数を使っても使わなくても,相対的一人当たりGDPの分布の広がりは大きいことは既に確認したことだが,その広がり幅は分散で測ることができる。
問題は,その分散が何に依存しているか,ということである。
この問いに答えるために,\(X\)をランダム変数をすると分散と共分散には次の関係があることを思い出そう。
(分散と共分散のルールについてはここを参照しよう)。
\(X\)の分散は\(X\)と\(X\)の共分散と等しい。
この関係を使い,式(5)の分散を書き換えていこう。
<計算の説明>
1行目:式(6)を利用する。2行目:式(5)を代入する。3行目:\(r_i^{\text{tfp}}+r_i^{\text{factors}}\)は線形となっているため,それぞれの共分散として展開することができる。
この式は\(r_i^y\)の分散は2つの共分散に分解する事ができることを示している。
\(\text{Var}\left(r_i^{\text{y}}\right)\):相対所得(対数; 米国=1)の変動
\(\text{Cov}\left(r_i^{\text{y}},r_i^{\text{tfp}}\right)\):相対所得と相対全要素生産性の共分散(それぞれ対数; 米国=1)
\(\text{Cov}\left(r_i^{\text{y}},r_i^{\text{factors}}\right)\):相対所得と相対蓄積生産要素の共分散(それぞれ対数; 米国=1)
更に,(7)の両辺を\(\text{Var}(r_i^y)\)で割ると,次のように書くことができる。
ここで
と定義する。
(考え方)
式(8)と(9)の分母は\(\log(R_i^y)\)の分散であり,それに対して分子はどれだけ変動しているかで寄与度を計算しようということである。分母に対して分子の変動が大きければ大きい程,説明力が高いと判断する。極端な例として、全ての経済の全要素生産性が同じで蓄積生産要素だけが異なる場合を考えてみよう。即ち,
この場合、蓄積生産要素だけで一人当たりGDPの違いを説明できることになるため、全要素生産性の寄与度は0であり蓄積生産要素は1である。即ち、全要素生産性は変化しないため一人当たりGDP(対数)の分散を説明できないが,一方,蓄積生産要素の変動のみで一人当たりGDPの変動を説明している事になる。
以下では分散・共分散を計算するが,その前に欠損値であるNaNがある行を削除しdfに再割り当てする。
cols = ['y_relative_log', 'tfp_relative_log', 'factors_relative_log']
df = df.dropna(subset=cols)
コードの説明
1行目で使った.dropna()は,引数なしでそのまま使うと1つでもNaNがある行は削除される。引数のsubset=[]に列を指定すると,その列にNaNがある行だけが削除される。
これで
\(\text{Var}\left(r_i^{y}\right)\),
\(\text{Cov}\left(r_i^{\text{y}},r_i^{\text{tfp}}\right)\),
\(\text{Cov}\left(r_i^{\text{y}},r_i^{\text{factors}}\right)\)を計算する準備が整ったので,DataFrameのメソッド.cov()を使って分散共分散を計算しよう。
vcov = df[cols].cov()
vcov
| y_relative_log | tfp_relative_log | factors_relative_log | |
|---|---|---|---|
| y_relative_log | 1.006052 | 0.580623 | 0.42543 |
| tfp_relative_log | 0.580623 | 0.373833 | 0.20679 |
| factors_relative_log | 0.425430 | 0.206790 | 0.21864 |
対角線にある値は各変数の分散となり,その他が各変数間の共分散となる。
# yの分散
y_relative_log_var = vcov.iloc[0,0]
# yとtfp共分散
y_tfp_relative_log_cov = vcov.iloc[0,1]
# yとfactors共分散
y_factors_relative_log_cov = vcov.iloc[0,2]
全要素生産性の寄与度
式(8)に従って,全要素生産性の寄与度を計算しよう。
y_tfp_relative_log_cov / y_relative_log_var
0.5771296812280919
蓄積生産要素の寄与度
次に式(9)を使い,蓄積生産要素の寄与度を計算しよう。
y_factors_relative_log_cov / y_relative_log_var
0.4228703187719081
結果
2019年の相対的一人当たりGDPの約57%は全要素生産性によって説明され,残りの42%は蓄積生産要素によって説明される。即ち,一人当たりGDPの決定要因としての全要素生産性の重要性は,蓄積生産要素と同等もしくはそれ以上である。
表の作成#
最後に,全要素生産性と蓄積生産要素の主要な国のデータを表にまとめてみる。
# 1
country_table = ['Japan', 'United Kingdom','United States', 'Norway',
'Mexico','Peru','India','China','Zimbabwe','Niger']
# 2
cond = df['country'].isin(country_table)
# 3
col = ['country','y_relative','tfp_relative','factors_relative']
# 4
table2019 = df.loc[cond,col].set_index('country') \
.sort_values('y_relative', ascending=False) \
.round(2) \
.rename(columns={'y_relative':'一人当たりGDP',
'tfp_relative':'全要素生産性',
'factors_relative':'蓄積生産要素'})
print('米国を1として')
table2019
米国を1として
| 一人当たりGDP | 全要素生産性 | 蓄積生産要素 | |
|---|---|---|---|
| country | |||
| Norway | 1.22 | 1.33 | 0.92 |
| United States | 1.00 | 1.00 | 1.00 |
| United Kingdom | 0.69 | 0.82 | 0.85 |
| Japan | 0.54 | 0.63 | 0.86 |
| Mexico | 0.29 | 0.59 | 0.50 |
| China | 0.28 | 0.41 | 0.67 |
| Peru | 0.17 | 0.33 | 0.52 |
| India | 0.13 | 0.30 | 0.42 |
| Zimbabwe | 0.06 | 0.19 | 0.32 |
| Niger | 0.03 | 0.21 | 0.16 |
コードの説明
表示する国のリスト
列
countryにcountry_listにある国名と同じであればTrue、異なる場合はFalseを返す条件を作成している。.isin()はそのためのメソッド
表の列ラベルに使う変数リスト
DataFrameを作成する。.loc[cond,col]を使い、condの条件に合った行、そしてcolの列を抽出する。.set_index('country')はcountryの列を行ラベルに設定するメソッド。.sort_values()はDataFrameを列y_relativeに従って並び替えるメソッドであり、ascending=Falseは降順を指定している。.round(2)は表示する小数点を第二桁までで四捨五入することを指定するメソッド。.rename()は列ラベルを変更するメソッド。
<コメント> print()関数を使うとテキストとして表示される。
この表から日本の全要素生産性は米国の63%であり,蓄積生産要素は米国の86%であることが分かる。