linearsolve#
import linearsolve as ls
import numpy as np
import pandas as pd
# numpy v1の表示を使用
np.set_printoptions(legacy='1.21')
# 警告メッセージを非表示
import warnings
warnings.filterwarnings("ignore")
説明#
後に続く章では,実物的景気循環(RBC)モデルとNew Keynsianモデル(Dynamic Stochastic General Equilibrium Model,略してDSGEモデルとも呼ばれる)を考える。それらのモデルでは,消費者は効用を最大化し,企業は利潤を最大化する。そのような最適化問題を解き,一般均衡での動学方程式を導出する作業は高度な数学的な知識を要求するため,このサイトの範囲を超えることになる。従って,それぞれのモデルの考えを説明した後,シミュレーションを使いデータとの整合性などを検討する。この章では,そのために使用するlinearsoveというパッケージの使い方を説明する。
実物的景気循環モデルやNew Keynsianモデルの均衡式は複雑な非線形となっており,また将来の変数に対する期待が重要な役割を果たす。従って,次の2つのステップを踏んでシミュレーションをおこなうことになる。
非確率的な定常状態の近傍で線形近似をおこない,それぞれの変数を定常状態からのパーセント乖離で表した均衡式に書き直してシミュレーションをおこなう。その際の定常状態からのパーセント乖離で表すことを対数線形近似と呼ぶ。(ちなみに,このサイトで扱うNew Keynsianモデルの内生変数は最初から%乖離で表されている。)
様々な均衡を計算する手法が提案されており,その1つに従ってモデルを「解く」。
このプロセスを自動化してくれるのがlinearsolve(リンク)である。2の均衡の計算方法はについては,
linearsolveはKlein (2000)を採用している。その詳細については割愛するが,1の対数線形近似について簡単に説明する。
Note
linearsolveを使用するためには,事前にインストールする必要がある。MacのターミナルやWindowsのAnaconda Promptでは,次のコマンドでインストールすることができる。
pip install linearsolve
対数線形近似#
\(t=0,1,2,..\)の離散時間を考えよう。\(t\)時点での変数\(X\)を\(X_t\)とする。産出量や資本ストックなどをイメージすれば良いだろう。さらに次の変数を定義する。
\(X\):\(X_t\)の定常状態の値
\(x_t\equiv\log\left(\dfrac{X_t}{X}\right)\):\(X_t\)の定常状態からのパーセント乖離
定常状態(\(X_t=X\))では\(x_t=0\)になることを覚えておこう。
以前,マクロ変数をトレンドと変動(トレンドからの%乖離)に分離する分析をおこなった。その際,\(\bar{X}_t\)をトレンドとすると,変動は次式で近似できることも説明した。
実は,これが正しく対数線形近似の考え方なのである。\(X=\bar{X}_t\)として,この式を変形すると次のようになる。
この式が\(X_t\)の対数線形近似となる。更に,\(Z_t^a\)の線形近似を考えてみよう。\(Z^a\)を定常状態と置いて上の計算の2行目に\(X_t=Z_t^a\)と\(X=Z^a\)を代入してみる。
ここで\(z_t=\log\left(\dfrac{Z_t}{Z}\right)\)は\(Z_t\)の%乖離を表している。式(164)が\(Z_t^a\)の対数線形近似であり,\(a=1\)の場合を包含する形となっている。
例:ソロー・モデル#
例として,人口成長も技術進歩もないソロー・モデルの資本蓄積方程式を考えよう(\(L=1\)を仮定する)。
式が示すように,\(K_{t+1}\)と\(K_{t}\)は非線形の関係にある。次の変数を定義して,対数線形近似をおこなう。
\(K=\left(\dfrac{s}{\delta}\right)^{\frac{1}{1-a}}\):定常状態
\(\dfrac{s}{K^{1-a}}=\delta\)と書くこともできるが,この関係を下の計算で使う。
\(k_t\):定常状態からのパーセント乖離(「労働者一人当たり資本」ではない。ここでは\(K_t\)が労働者一人当たり資本と等しい)。
それぞれの項にパーセント乖離の線形近似を適用する。
これでパーセント乖離の変数である\(k_{t+1}\)と\(k_{t}\)の線形式が導出できた。\(k_t\)の係数は正の値であり\(1\)より小さいので,定常状態\(0\)は安定的だとわかる。
例:ショック項があるコブ・ダグラス生産関数#
次のコブ・ダグラス生産関数を考えよう。
ここで\(A_t\)はTFPショックと考えることができる。また定常状態は次式で与えられるとしよう。
\(t\)期の生産関数を定常状態の生産関数で除した結果を対数化することで簡単に%乖離を計算できる。
この場合,線形近似ではなく正確な関係を表している。同じ結果を上の(164)式を使って導出してみよう。
最後の行では\(\alpha a_tk_t=0\)としている。%乖離の積は非常に小さな値であるためであり,(164)式を導出する上で発生した誤差を表している(誤差は無視できるほど非常に小さい)。
linearsolveの使い方#
対数線形近似を理解できたと思うので,linersolveを使って次のステップでシミュレーションを進める。
モデルのパラメータを
Seriesとして保存する。内生変数名とショックの変数名を別々のリストとして保存する。
非確率的な定常状態での均衡条件を返す関数を定義する。
linearsolve.modelを使いシミュレーションのための最終準備(シミュレーションの情報が詰まったオブジェクトを作成)をする。定常状態の計算。
モデルを対数線形近似する。
シミュレーション結果の表示。
シミュレーションをおこなう上で2つの変数を区別することも重要となるので次の点を抑えておこう。
「ストック変数」,「状態変数」,「先決変数」
資本ストックのように前期までの経済行動で決定され当該期では所与として扱われる変数
「フロー変数」,「操作変数」,「コントロール変数」
消費や産出量のように当該期に決定される変数
またシミュレーションのの中で決定される変数は全て「内生変数」と呼ぶ。
以下では2つの例を使い具体的にシミュレーションのコードの書き方を説明をする。
全要素生産性(TFP)#
\(A\)は全要素生産性(TFP)を表しており,次式に従って変化すると考えよう。
ここで,底の\(e\)はネイピア数であり,指数の\(u_{t+1}\)はショック変数のホワイト・ノイズであり,正規分布に従うと仮定する。
ストック変数:\(A_t\)
フロー変数:なし
このモデルで決定される変数(内生変数):\(A_t\)
ショック変数(外生変数):\(u_t\)
ステップ1:パラメータの値#
パラメータは\(\rho\)と\(\sigma\)の2つだけである。パラメータの値を入れたSeriesを変数parameterに割り当てる。
parameters = pd.Series({'rho':0.9,
'sigma':0.0078**2})
parameters
rho 0.900000
sigma 0.000061
dtype: float64
ここでは辞書を使ってSeriesを作成している。sigmaの値は日本のTFPに関して計算した数値を設定している。
ステップ2:変数リスト#
内生変数名のリスをを作成する。その際,次の順番で並べる。
ショック項があるストック変数(内生変数)の変数名
ショック項がないストック変数(内生変数)の変数名
フロー変数(他の内生変数)の変数名
この例では,ショック項があるストック変数Aのみとなる。また,リストの要素として含める変数名をAとしても良いが,計算結果ではAの対数線形近似の変数が返される。それを見越して,ここではaを使うことにする。このように指定するする方が,後で分かりやすいだろう。
var_names = ['a']
次に,外生的ショックを表す変数名のリストを作成するが,var_namesと同じ順番に並べる。
shock_names = ['u']
ステップ3:定常状態での均衡条件の関数#
定常状態とは,ショック項が0であり,Aが一定となる状態を指す。このステップでは,定常状態での値を返す関数を作成する。関数名をequilibrium_equationsとする。この例での定常状態では次の条件を満たしている。
次に,非確率的な定常状態での均衡条件を返す関数を定義する。
引数:
variables_forward: \(t+1\)期(来期)の変数variables_current: \(t\)期(当該期)の変数parameters:ステップ1で設定したパラメータの値を含む変数parameters
戻り値:
定常状態での内生変数の値を格納する
Numpyのarray
def equilibrium_equations(variables_forward, variables_current, parameters):
fwd = variables_forward #1
cur = variables_current #2
p = parameters #3
tfp = cur['a']**p['rho']/fwd['a']-1 #4
return np.array([tfp]) #5
<コードの説明>
#1: t+1期の変数をfwdに割り当てる。#2: t期の変数をcurに割り当てる。#3: ステップ1のparametersをpに割り当てる。#4: 定常状態でのTFPの式を使い,左辺が0になるように整理し,その右辺をtfpに割り当てる。\[ A_{t+1}=A_t^{\rho} \quad\Rightarrow\quad 0=\frac{A_t^{\rho}}{A_{t+1}}-1 \]他にも均衡式がある場合は,同じ方法で指定することになる。
ステップ4で
equilbirium_equations関数を単に指定するだけだが,linearmodelsはcurとfwdをSeriesとして扱うことになるため,変数を['a']の形で指定する必要がある。
#5:#4の変数をarrayとして返す。#4以外にも均衡式がある場合は,np.arrayの一次元配列として#5に含めることになる。
ステップ4:モデルの最終準備(初期化)#
lsのmodelという関数を使いシミュレーションの最終準備をおこない(初期化し),tfp_modelに割り当てる。
引数:
equations:ステップ2で定義した関数を指定する。variables:ステップ2で設定した内生変数のリストを指定する。exo_states:ショック項があるストック変数名を指定する。複数の場合はリストとして指定する。この例ではストック変数は
Aのみなのでaを指定する。
endo_state:ショック項がないストック変数名を指定する。複数の場合はリストとして指定する。この例ではないので書く必要はない。
costates:コントロール変数名を指定する。複数の場合はリストとして指定する。この例ではないので書く必要はない。
shock_names:ステップ2で設定したショック変数のリストを指定する。この引数は必須ではなく,指定しなければ自動的に変数名(例えば,
e_a)が使われる。
parameters:ステップ1で設定したパラメータの値を含むSeriesを指定する。
戻り値:
linearsolveのmodelオブジェクトが返される。その中に様々な情報が含まれており,それを使いシミュレーションをおこなう。
tfp_model = ls.model(equations = equilibrium_equations,
variables = var_names,
exo_states = 'a',
# endo_states = None,
# costates = None,
shock_names = shock_names,
parameters = parameters)
ステップ5:定常状態の計算#
最初に定常状態の値を確認しよう。tfp_modelのメソッドcompute_ss()(ssは定常状態を指すsteady stateの略)を使うと自動で計算してくれる。その際,引数に計算の初期値をリストとして与える。linearsolveが定常値を「計算する」という意味は,定常値を「探す」ということと等しい。その際,探す出発点となる値が「計算の初期値」である。この例では変数が1つなので[1.1]のようにする。複数ある場合は,ステップ2で設定したvar_namesの順番に合わせて初期値を並べる必要がある。
tfp_model.compute_ss([1.1])
上のコードを評価すると,tfp_modelには.ssという属性が追加され,計算結果は属性.ssでアクセスすることが可能である。
tfp_model.ss
a 1.0
dtype: float64
ここで示しているのは,linearmodelsは1.1を出発点として定常値を探し始め,最終的に1.0を探し出したということだ。
ステップ6:モデルを対数線形近似#
次にシミュレーションのための対数線形近似をおこなう。tfp_modelには.approximate_and_solve(log_linear=True)というメソッドが用意されており,それを使うとtfp_modelの対数線形近似を計算し,tfp_modelに組み込むことになる。
tfp_model.approximate_and_solve(log_linear=True)
結果はtfp_modelのメソッド.solved()を使うと表示できる。
print(tfp_model.solved())
Solution to the log-linear system:
a[t+1] = 0.9·a[t]+u[t+1]
ここで表示された式を考えてみよう。\(A_t\)の定常状態での値は1であり,式(165)を次のように書ける。
\(a_{t}\equiv\log\left(\dfrac{A_{t}}{1}\right)\approx\dfrac{A_t-1}{1}\)(定常値からの乖離の割合)を使い,この式の両辺を対数化すると
となり(\(\log(1)=0\)を思い出そう),上の式と同じになる。この結果から,上の式は近似ではなく同じ式である事が分かる。
Note
print(tfp_model.solved())のコードが表示しているのは2行は文字列であり,改行が2回(\n\n)入っている。これを利用して次のコードで2行目の式だけを取り出す事ができる。
print(tfp_model.solved().split('\n\n')[1])
split()は文字列を引数'\n\n'で分割し,結果をリストとして返すメソッドである。[1]はリストの1番目の要素を取り出している(0番目はSolution to the...となる)。
ステップ7:シミュレーション結果の表示#
インパルス反応#
t=0期は定常状態でa[0]=0としよう。更に,t=1期にショック項が1%上昇したとしよう(u[1]=1%)。この場合,a[1]=1%となる事が分かる。これがインパクト効果である。インパクト後,ショック項は0に張り付いたままとなり,aの値は次のように変化することになる。
a[0]=0
a[1]=1%
a[2]=0.95a[1]=0.95x1%=0.95%
a[3]=0.95a[2]=0.95x0.95x1%=0.9025%
a[4]=0.95a[3]=0.95x0.95x0.95x1%=0.857375%
......
時間が経つに連れて徐々に減少することになり,一般的には次の式で表すことができる。
この一連の「出力」がインパルス反応と呼ばれる。
インパルス反応の計算と図示#
では,実際にインパルス反応を計算し図示してみよう。ホワイト・ノイズのショック\(u_t\)のインパルス反応を計算するには,tfp_modelのメソッドimpulse()を使う。
引数:
T:シミュレーションのの期間t0:何期目にショックを発生させるかを指定shocks:ショックの大きさ(定常状態からの乖離,デフォルトは0.01)複数ある場合は辞書として指定する。例えば,
shocks={'u':0.05}。
戻り値:
なし
計算結果は
tfp_modelに辞書として追加される。キー:ショックの変数名の
u値:ショック変数と内生変数の
DataFrame
追加された辞書は属性
.irs(Impulse ReSponseの略)でアクセスできるので,キーuを使ってDataFrameを表示することが可能となる。
まずメソッド.impulse()で計算しよう。
tfp_model.impulse(T=50, t0=5, shocks={'u':0.05})
次に,属性.irsを使って辞書を抽出し,キーuを使ってDataFrameを表示する。
tfp_model.irs['u'].head(9)
| u | a | |
|---|---|---|
| 0 | 0.00 | 0.00000 |
| 1 | 0.00 | 0.00000 |
| 2 | 0.00 | 0.00000 |
| 3 | 0.00 | 0.00000 |
| 4 | 0.00 | 0.00000 |
| 5 | 0.05 | 0.05000 |
| 6 | 0.00 | 0.04500 |
| 7 | 0.00 | 0.04050 |
| 8 | 0.00 | 0.03645 |
5番目の行のみでuが0.05になっているのが確認できる。同様に,aも0.05に跳ね上がっているが,インパクト後は徐々に減少しているのがわかる。
縦軸を%表示にして,このDataFrameをプロットしてみよう。
( 100*tfp_model.irs['u'] ).plot(lw=3, alpha=0.5, grid=True)
pass
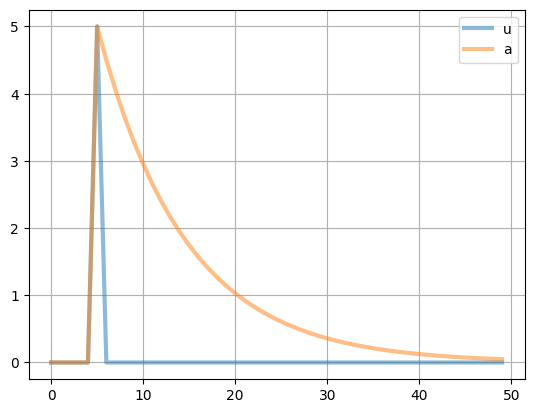
この図のaはA_tの定常状態からの%乖離を表していることを思い出そう。t=0からt=4の5期間はショックがない定常状態である。t=5に5%の正のショックが発生し,t=6以降のショックは0に戻っている。一方,Aの%乖離であるaはゆっくりと減少し,分かりにくいが50期間過ぎても0%になっていない。例えば,一期間を1四半期と考えた場合,ショック項の影響は(50-5)/4=11.25年経った後でも残っていることになる。persistenceと呼ばれるこのような性質が景気循環を理解する上で重要な鍵となる。
コードを1つのセルにまとめる#
今までの説明では,それぞれのステップ毎にセル内でコードを書き実行した。しかし,一旦コードにエラーがないと確認できた後は,1つのセルにコードをまとめることを勧める。例えば,パラメーターの値を変えて様々なパターンの結果を確認したいとしよう。1つのセルにコードをまとめると1回のコードの実行で結果を表示できる便利さがある。
# パラメーターの値
parameters = pd.Series({'rho':0.9,
'sigma':0.0078**2})
# 変数のリスト
var_names = ['a']
shock_names = ['u']
# 定常状態での均衡の関数
def equilibrium_equations(variables_forward, variables_current, parameters):
fwd = variables_forward
cur = variables_current
p = parameters
tfp = cur['a']**p['rho']/fwd['a']-1
return np.array([tfp])
# モデルの初期化
tfp_model = ls.model(equations = equilibrium_equations,
variables = var_names,
exo_states = 'a',
# endo_states = None, # 内生変数(stock)
# costates = None, # 内生変数(control)
shock_names=shock_names,
parameters = parameters)
# 定常状態の計算
tfp_model.compute_ss([1.1])
ss = tfp_model.ss
print(f'定常値\n{ss.index[0]}: {ss.iloc[0]:.3f}\n')
# 対数線形近似
tfp_model.approximate_and_solve(log_linear=True)
print('対数線形近似\n', tfp_model.solved().split('\n\n')[1], sep='')
# インパルス反応の計算
tfp_model.impulse(T=50, t0=5, shocks={'u':0.05})
# プロット
( 100*tfp_model.irs['u'] ).plot(lw=3, alpha=0.5, grid=True)
pass
定常値
a: 1.000
対数線形近似
a[t+1] = 0.9·a[t]+u[t+1]
確率的シミュレーション#
インパルス反応は,ある一期間のみにショック項が変化する場合の分析となる。一つのショックの時系列的な効果を検討する上では有用な手法である。一方で,実際経済ではショックが断続的もしくは連続的に発生していると考えることができる。そのような状況を捉えた確率的シミュレーションをおこなおうというのが,ここでの目的である。
linearmodelsには,そのためのメソッド.stoch_sim()が実装されている。
主な引数:
seed(オプション):Numpy.randomを使いランダム変数を発生させるが,seedとはランダム変数の「種」という意味である。seedに同じ数字を設定すると同じランダム変数が生成されることになる。同じ「種」からは同じランダム変数を発生させることができる,ということである。T:シミュレーションの期間(デフォルトは51)covariance_matrix:ショック変数の分散共分散行列ショック変数が1つの場合は分散を
[[0.5]]のようにリストのリストで設定する。(デフォルトは[[1]])ショック変数が複数の場合は
[[0.5,0.1],[0.1,2]]のようなパターンで設定する。(デフォルトは[[1,0],[0,1]])この例で,0.5と2が2つのショック項の分散であり,0.1が共分散となる。 * 戻り値:
なし
結果は
tfp_modelにDataFrameとして追加され,属性simulatedで抽出できる。
tfp_model.stoch_sim(seed=12345, T=200,
covariance_matrix=[[parameters['sigma']]])
結果の一部を表示してみる。
tfp_model.simulated.head()
| u | a | |
|---|---|---|
| 0 | 0.001512 | -0.026814 |
| 1 | -0.001008 | -0.025141 |
| 2 | 0.002765 | -0.019862 |
| 3 | -0.008446 | -0.026322 |
| 4 | 0.001911 | -0.021779 |
図示してみよう。
tfp_model.simulated.plot()
pass
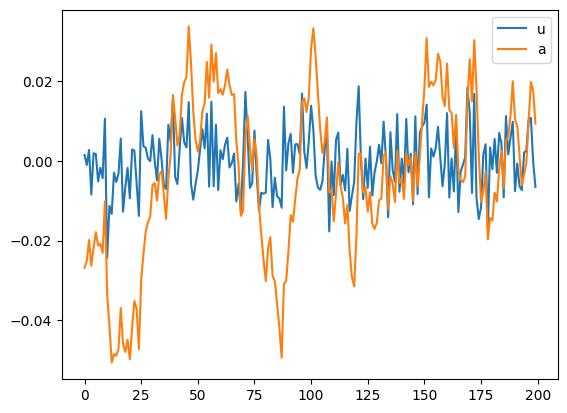
ショック項uは細かく上下している一方,aは持続的に上昇もしくは減少し定常値0から乖離することがわかる。景気循環におけるマクロ変数の動きと似ていいる様に見えないだろうか。
確率的ソロー・モデル#
次の例としてTFPが確率的に変動するソロー・モデルを考えよう。均衡は次の3つの式で表される。
(168)式は全要素生産性の変動を表しており,(165)式と同じである。また\(u_{t}\sim\mathcal{N}(0,\sigma^2)\)とする。
ストック変数:\(K_t\), \(A_t\)
フロー変数:\(Y_t\)
内生変数:\(K_t\), \(A_t\), \(Y_t\)
ショック変数:\(u_t\)
ステップ1:パラメータの値#
4つパラメータの値を入れたSeriesを変数parameterに割り当てる。
parameters = pd.Series({'alpha':0.36,
's':0.1,
'd':0.07,
'rho':0.551,
'sigma':0.0078**2})
parameters
alpha 0.360000
s 0.100000
d 0.070000
rho 0.551000
sigma 0.000061
dtype: float64
ここでは辞書を使ってSeriesを作成している。rhoとsigmaの値は日本のTFPに関して計算した数値を設定している。
ステップ2:変数リスト#
内生変数名のリスをを作成する。その際,次の順番で並べる。
ショック項があるストック変数(内生変数)の変数名
ショック項がないストック変数(内生変数)の変数名
フロー変数(他の内生変数)の変数名
また対数線形近似されることを念頭に小文字で変数名を設定することにする。
var_names = ['a','k','y']
次に,外生的ショックを表す変数名のリストを作成する。複数ある場合は,var_namesと同じ順番に並べる。この例では,aのみにショック項があるので次のようにする。
shock_names = ['u']
ステップ3:定常状態での均衡条件の関数#
非確率的定常状態での値を返す関数を作成する。関数名はequilibrium_equationsとする。この例での非確率的定常状態では次の条件を満たしている。
引数:
variables_forward: \(t+1\)期(来期)の変数variables_current: \(t\)期(当該期)の変数ステップ1で設定したパラメータの値を含む
parameters
返り値:
(非確率的)定常状態での内生変数の値を格納する
Numpyのarray
def equilibrium_equations(variables_forward, variables_current, parameters):
fwd = variables_forward #1
cur = variables_current #2
p = parameters #3
tfp = p['rho']*np.log(cur['a'])-np.log(fwd['a']) #4
production_function = cur['a']*cur['k']**p['alpha'] - cur['y'] #5
capital_change = p['s']*cur['a']*cur['k']**p['alpha'] + \
(1-p['d'])*cur['k'] - fwd['k'] #6
return np.array([tfp, production_function, capital_change]) #7
<コードの説明>
#1: t+1期の変数をfwdに割り当てる。#2: t期の変数をcurに割り当てる。#3: ステップ1のparametersをpに割り当てる。#4: (非確率的)定常状態でのTFPの式を使い,左辺が0になるように整理し,その右辺をtfpに割り当てる。\[\begin{split} \begin{align*} \log(A_{t+1}) &=\rho\log(A_t) \\ &\Downarrow \\ 0 &=\rho\log(A_{t})-\log(A_{t+1}) \end{align*} \end{split}\]ステップ4で
equilbirium_equations関数を単に指定するだけだが,linearmodelsはcurとfwdをSeriesとして扱うことになるため,変数を['a']の形で指定する必要がある。
#5: 生産関数の式を使い,左辺が0になるように整理し,その右辺をproduction_functionに割り当てる。\[\begin{split} \begin{align*} Y_{t}&=A_tK_t^{a} \\ &\Downarrow \\ 0&=A_tK_t^{a}-Y_t \end{align*} \end{split}\]#6: 資本の蓄積方程式を使い,左辺が0になるように整理し,その右辺をcapital_changeに割り当てる。\[\begin{split} \begin{align*} K_{t+1}&=sA_tK_t^{a}+(1-d)K_t \\ &\Downarrow \\ 0&=sA_tK_t^{a}+(1-d)K_t-K_{t+1} \end{align*} \end{split}\]#7:#4〜#6の値をarrayとして返す。
ステップ4:モデルの最終準備(初期化)#
lsのmodelという関数を使いシミュレーションの最終準備をおこない(初期化し),solow_modelに割り当てる。
引数:
equations:ステップ2で定義した関数を指定する。variables:ステップ2で設定した内生変数のリストを指定する。exo_states:ショック項があるストック変数名を指定する。複数の場合はリストとして指定する。この例ではストック変数は
Aのみなのでaを指定する。
endo_state:ショック項がないストック変数名を指定する。複数の場合はリストとして指定する。この例ではないので書く必要はない。
costates:コントロール変数名を指定する。複数の場合はリストとして指定する。この例ではないので書く必要はない。
shock_names:ステップ2で設定したショック変数のリストを指定する。この引数は必須ではなく,指定しなければ自動的に変数名(例えば,
e_a)が使われる。
parameters:ステップ1で設定したパラメータの値を含むSeriesを指定する。
戻り値:
linearsolveのmodelオブジェクトが返される。その中に様々な情報が含まれており,それを使いシミュレーションをおこなう。
solow_model = ls.model(equations = equilibrium_equations,
variables = var_names,
exo_states = 'a',
endo_states = 'k',
costates = 'y',
shock_names=shock_names,
parameters = parameters)
ステップ5:定常状態の計算#
最初に定常状態の値を確認しよう。solow_modelのメソッドcompute_ss()を使うと自動で計算してくれる。その際,引数に計算の初期値をリストとして与える。ステップ2で設定したvar_namesの順番に合わせて初期値を並べる。
solow_model.compute_ss([1, 5, 2])
上のコードを評価すると,solow_modelには.ssという属性が追加され,それを使い計算結果を表示できる。
solow_model.ss
a 1.000000
k 1.745960
y 1.222172
dtype: float64
ステップ6:モデルを対数線形近似#
次にシミュレーションのための対数線形近似をおこなう。solow_modelには.approximate_and_solve(log_linear=True)というメソッドが用意されており,それを使うとsolow_modelの対数線形近似を計算し,solow_modelに組み込むことになる。
solow_model.approximate_and_solve(log_linear=True)
結果はsolow_modelのメソッド.solved()を使うと表示できる。
print(solow_model.solved())
Solution to the log-linear system:
a[t+1] = 0.551·a[t]+u[t+1]
k[t+1] = 0.07·a[t]+0.9552·k[t]
y[t] = a[t]+0.36·k[t]
ここでa,k,yは定常状態からの%乖離を表している。これらの式が「モデルを解いた結果」を示しており,次の特徴がある。
2つのストック変数(
aとk)のt+1期の値は,t期の値とt+1期のショックに依存している。フロー変数の値はストック変数の値のみに依存しており,Policy Functionと呼ばれる。
t期のストック変数とt+1期のショック変数の値が分かれば,t+1期の全ての変数の値が明らかになる体系になっている。例えば,t=0期が定常状態(a[0]=k[0]=y[0])としてt=1期にショック項u[1]が1%上昇したとしよう。上の式からu[1]=a[1]=y[1]=1%となることが分かる。
ステップ7:シミュレーション結果の表示#
インパルス反応#
t=0期は定常状態でa[0]=k[0]=y[0]=0としよう。そしてt=1期にショック項が1%上昇し(u[1]=1%),その後0に戻ると仮定しよう。この場合,
a[1]=y[1]=1%であり,k[1]=0となる事が分かる。これがインパクト効果である。インパクト後,
a[2]=0.551・a[1],k[2]=0.07・a[2],y[2]=a[2]+0.35・k[2]となり時間が経つに連れて変化することになる。
このインパルス反応を計算して図示してみよう。
インパルス反応の計算と図示#
ホワイト・ノイズのショック\(u_t\)のインパルス反応を計算するには,solow_modelのメソッドimpulse()を使う。引数は次の3つとなる。
T:シミュレーションのの期間t0:何期目にショックが発生するかを指定shocks:ショックの大きさ(%)(デフォルトは0.01)
solow_model.impulse(T=50, t0=5)
計算結果はsolow_modelに辞書として追加される。
キー:ショックの変数名
u値:ショック変数と内生変数の
DataFrame
辞書は属性.irsでアクセスできるので,キーuを使いDataFrameを表示してみよう。
solow_model.irs['u'].head(9)
| u | a | k | y | |
|---|---|---|---|---|
| 0 | 0.00 | 0.000000 | 0.000000 | 0.000000 |
| 1 | 0.00 | 0.000000 | 0.000000 | 0.000000 |
| 2 | 0.00 | 0.000000 | 0.000000 | 0.000000 |
| 3 | 0.00 | 0.000000 | 0.000000 | 0.000000 |
| 4 | 0.00 | 0.000000 | 0.000000 | 0.000000 |
| 5 | 0.01 | 0.010000 | 0.000000 | 0.010000 |
| 6 | 0.00 | 0.005510 | 0.000700 | 0.005762 |
| 7 | 0.00 | 0.003036 | 0.001054 | 0.003416 |
| 8 | 0.00 | 0.001673 | 0.001220 | 0.002112 |
5番目の行でuは1.0になっている。同様に,aとyも1.0にジャンプしているが,資本ストックの%乖離であるkは,5番目の行で0のままである。これは式(167)が示すように,t期の産出Yの変化はt+1期の資本ストックに影響を与えており,時間的なラグが発生しているためである。また6行目からkは徐々に増加していることがわかる。この結果は,資本ストックの変化には時間がかかるという特徴を反映したものといえる。
プロットしてみよう。
( 100*solow_model.irs['u'] ).plot(subplots=True, figsize=(6,8), grid=True)
pass
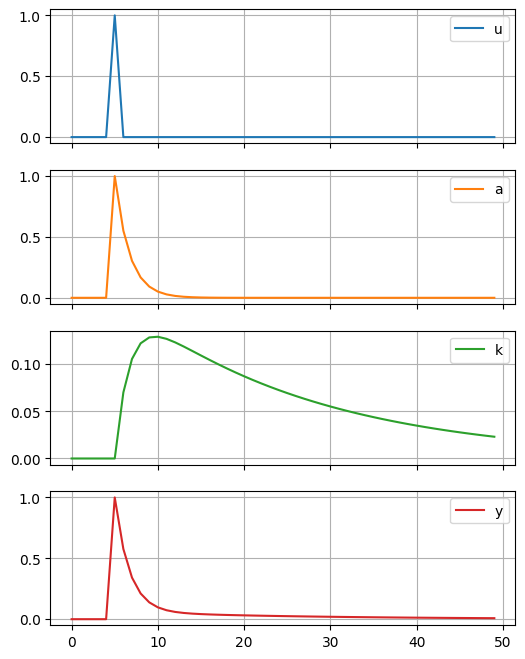
産出と資本ストックの%乖離の変化は大きく異なる。動物で例えると,産出はカモシカのように動きが素早いが,資本ストックは象のように動きがスローである。前者はフロー変数であり,後者はストック変数であるためであり,それぞれの変数の特徴が反映されたプロットとなっている。
コードを1つのセルにまとめる#
ここでは上のコードを一つのセルにまとめて,全てを同時に実行し結果を表示してみよう。
# パラメーターの値
parameters = pd.Series({'alpha':0.36,
's':0.1,
'd':0.07,
'rho':0.551,
'sigma':0.0078**2})
# 変数名
var_names = ['a','k','y']
shock_names = ['u']
# 定常状態での均衡の関数
def equilibrium_equations(variables_forward, variables_current, parameters):
fwd = variables_forward
cur = variables_current
p = parameters
tfp = p['rho']*np.log(cur['a'])-np.log(fwd['a'])
production_function = cur['a']*cur['k']**p['alpha'] - cur['y']
capital_change = p['s']*cur['a']*cur['k']**p['alpha'] + \
(1-p['d'])*cur['k'] - fwd['k']
return np.array([tfp, production_function, capital_change])
# モデルの初期化
solow_model = ls.model(equations = equilibrium_equations,
exo_states = ['a'],
endo_states = ['k'],
costates = ['y'],
shock_names=['u'],
parameters = parameters)
# 定常状態の計算
solow_model.compute_ss([1,5,2])
print('定常値')
for i in range(len(solow_model.ss)):
print(f'{solow_model.ss.index[i]}: {solow_model.ss.iloc[i]:.3f}')
print('')
# 対数線形近似
solow_model.approximate_and_solve(log_linear=True)
print('対数線形近似')
for s in solow_model.solved().split('\n\n')[1:]:
print(s, sep='')
# インパルス反応の計算
solow_model.impulse(T=50, t0=5)
# プロット
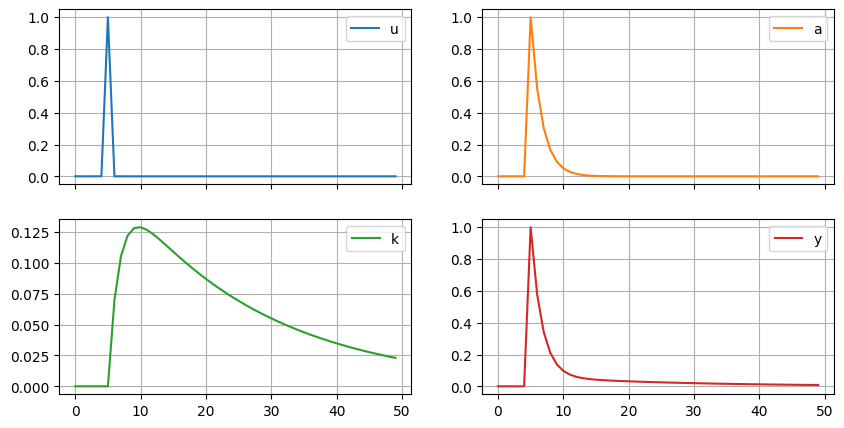
(100*solow_model.irs['u']).plot(subplots=True, layout=[2,2],
figsize=(10,5), grid=True)
pass
定常値
a: 1.000
k: 1.746
y: 1.222
対数線形近似
a[t+1] = 0.551·a[t]+u[t+1]
k[t+1] = 0.07·a[t]+0.9552·k[t]
y[t] = a[t]+0.36·k[t]
確率的シミュレーション#
次にメソッド.stoch_sim()を使って確率的シミュレーションをおこなってみよう。
主な引数:
seed(オプション):Numpy.randomを使いランダム変数を発生させるが,seedとはランダム変数の「種」という意味。seedに同じ数字を設定すると同じランダム変数が生成されることになる。T:シミュレーションの期間(デフォルトは51)cov_mat:ショック変数の分散共分散行列ショック変数が1つの場合は分散を
[[0.5]]のようにリストのリストで設定する。(デフォルトは[[1]]) * 返り値:
なし
結果は
solow_modelにDataFrameとして追加され,属性simulatedで抽出できる。
ショック項uの分散の値は0.0078であり,これは日本のTFPを推定した際の残差の分散である。この値を使ってシミュレーションをおこなおう。
solow_model.stoch_sim(seed=12345, T=200,
covariance_matrix=[parameters['sigma']])
結果の一部を表示してみる。
solow_model.simulated.head()
| u | a | k | y | |
|---|---|---|---|---|
| 0 | 0.001512 | -0.006122 | -0.004141 | -0.007613 |
| 1 | -0.001008 | -0.004382 | -0.004384 | -0.005960 |
| 2 | 0.002765 | 0.000351 | -0.004494 | -0.001267 |
| 3 | -0.008446 | -0.008253 | -0.004268 | -0.009790 |
| 4 | 0.001911 | -0.002637 | -0.004655 | -0.004313 |
Warning
このDataFrameの値はランダム変数を発生させて計算した結果である。従って,引数seedを設定しない場合は,シミュレーションを実行する度に異なる結果が発生する。しかし,以下で示す表や値はシミュレーションを行うごとに異なる結果となるが,方向性としては概ね変わらない。
DataFrameを図示してみよう。
ax_ = ( 100* solow_model.simulated[['a','u']] ).plot(subplots=True,
layout=(1,2),
grid=True,
figsize=(12,4),
color='k')
( 100*solow_model.simulated[['k','y']] ).plot(grid=True, ax=ax_[0,0])
pass
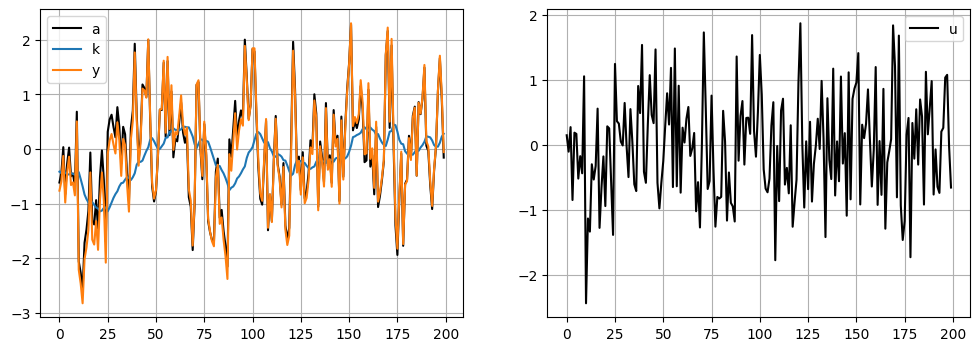
この図の特徴:
aとyの動きは殆ど同じである。また上下の動きはが激しく,定常値0を跨いだ動きが多い。kの動きは緩やか。定常値0からの乖離の方向が比較的に長く持続する傾向にある。即ち,persistenceの特徴が強い。
変動の大きさを確認するために標準偏差を計算してみよう。
solow_model.simulated[['y','k','a']].std()
y 0.010099
k 0.003960
a 0.009736
dtype: float64
aとyの値はは殆ど同じである。一方,kの標準偏差は小さく,aとyの半分以下である。この特徴は相関係数からも確認できる。
solow_model.simulated[['y','k','a']].corr()
| y | k | a | |
|---|---|---|---|
| y | 1.000000 | 0.320501 | 0.990336 |
| k | 0.320501 | 1.000000 | 0.186028 |
| a | 0.990336 | 0.186028 | 1.000000 |
yとaの相関は非常に高く,kとの相関は低い。また,3つの変数は正の相関があることがわかる。
次にpersistenceを考えてみよう。kの変動幅は小さいががpersistenceが大きいことが図から確認できる。実際に自己相関係数で確認してみよう。
var_list = ['y','k','a']
for v in var_list:
ac = solow_model.simulated[v].autocorr()
print(v,f': {ac:.3f}')
y : 0.610
k : 0.986
a : 0.570
yとaに比べてkの自己相関係数が非常に高いことがわかる。