ランダム変数と統計的特徴#
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
import japanize_matplotlib
import py4macro
# numpy v1の表示を使用
np.set_printoptions(legacy='1.21')
# 警告メッセージを非表示
import warnings
warnings.filterwarnings("ignore")
はじめに#
この章以降では短期的なマクロ経済分析について議論し、特に、景気循環の発生メカニズムの理解が大きな目的である。 本章は、その最初の章であり、分析の大前提となるランダム変数について説明し、マクロ経済分析において重要となる統計的な特徴について復習する。
GDPや消費などのマクロ変数は右上がりの長期的なトレンドがある。 また、失業率やインフレ率に関しても長期的なトレンドを考えることもできる。 トレンドの詳細については後に議論するとして、トレンドの周りをマクロ変数が変動し、それが景気循環だと解釈できる。 下の図では、日本のGDPの長期的トレンドからの乖離をパーセントで表している。 波打つように上下に、時には小刻みに、また時には大きく乱高下しているように見える。
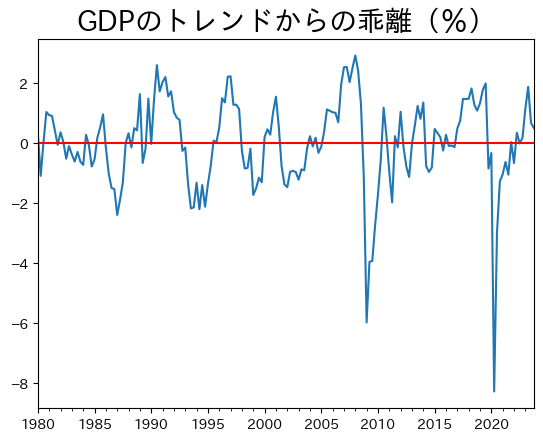
このようなGDPの変動を説明する方法として2つある。
決定的(deterministic)な過程で生成された時系列として捉える。
ランダム(stochastic)な過程で生成された時系列として捉える。
1の考えによると,差分方程式\(x_{t+1}=f(x_t)\)のように来期のGDPは今期のGDPに依存している。マクロ変数の持続性を捉えるには必要不可欠な特徴と言えるだろう。しかし,今期のGDP(\(x_t\))が与えられると来期のGDP(\(x_{t+1}\))は自ずと決定さることになり,来期のGDPの予測は簡単なものとなる。もしそうであれば政策運営は非常に簡単であろうが,現実はそうではない。そういう意味では,1は現実を十分に捉えることができていない。
一方,2の考えはランダム変数の実現値の連続としてGDPが観測され,今期のGDPが与えられても来期のGDPにはランダムな要素があるため,予測が難しいという特徴がある。この特徴こそが,マクロ変数の性質を捉えるには必要な要素であり,上のプロットに現れていると考えられる。主流のマクロ経済学では,消費者や企業の行動はフォーワード・ルッキングであり(将来を見据えた最適化行動であり),且つ経済全体ではランダムな(不確実な)要素が重要な役割を果たしているという考え基づいている。そのような分析枠組みの中で,景気循環のメカニズムを解明することが目的となっている。
以下では,まず,ランダム変数について復習し、マクロ変数を捉えるにはどのようなランダム変数生成過程が妥当かを検討する。 また、シミュレーションを通して、その統計的特徴を視覚的に確認する。
ランダム変数の統計的特徴:復習#
2つのランダム変数#
説明#
2つのランダム変数\(X_i\)と\(Y_i\), \(i=1,2,3,\cdots,n\)を考えよう。
例えば,\(X_i\)と\(Y_i\)は\(n\)個の2セットのサイコロ(合計2\(n\)個)を同時に投げた場合の目と考えることができる。
また、\(X_i\)の単位は円であり、\(Y_i\)はドル表示だとしよう(例えば,\(X_i\)のサイコロの目が5であれば5万円,\(Y_i\)のサイコロの目が3であれば300ドル)。
2変数の不偏分散は次のように定義される。
ここで\(\overline{X}\)と\(\overline{Y}\)は平均を表している。 (不偏)分散は、各ランダム変数の「散らばりの度合い」を数値化したものであり、\(X_i\)のの単位は\(\text{円}^2\)、\(Y_i\)の単位は\(\text{ドル}^2\)となる。 標準偏差は不偏分散の平方根である
となり、\(\sigma_{X}\)の単位は円となり、\(\sigma_{Y}\)の単位はドルである。
次に、2変数の相関を考えたい訳だが、その尺度として共分散が使われ、次のように定義される。
符号の解釈:
\(\sigma_{XY}=0\):無相関
\(\sigma_{XY}>0\):正の相関
\(\sigma_{XY}<0\):負の相関
共分散の絶対値が大きければ大きい(小さい)程,相関度が高い(低い)ことを意味するが、その値は単位に依存することになる。 \(\sigma_{XY}\)の単位は円xドルである。
また上の定義から次が成立することが簡単に理解できる。
共分散の特徴は\(X_i\)と\(Y_i\)の単位に依存することである。
例えば、2つのランダム変数\(K_i\)と\(Z_i\)の単位がユーロと人民元としよう。
\(\sigma_{XY}\)と\(\sigma_{KZ}\)を計算できるが、単位が異なるため比較には向いていない。
その点を克服するのが相関係数であり、次のように定義される。
次の特徴がある。
分母は必ず正となるので,分子の共分散が符号を決定する。
\(\rho_{XY}\)の値は
-1から1の間の値を取り、単位に依存しない。この特徴は、分母に\(X\)と\(Y\)の標準偏差の積を積を置く事により分母の単位をキャンセルしているためである。
更に、\(\rho_{XX}\)を考えてみよう。
同じ変数は完全に相関するため相関係数は1となる。
一般的には,\(\rho_{XY}\)の絶対値は1よりも小さな値となる。
相関係数の重要な特徴は単位には依存しないため,単位が異なる変数の相関度を比較するには有用な指標となる。
即ち、\(\sigma_{XY}\)と\(\sigma_{KZ}\)を比較して、どちらが相関度が高いかを容易に確認できることになる。
.covと.corr()#
共分散と相関係数の違いを説明したが,DataFrameを使ってどのように計算するかを説明する。dfex1は次のようなDataFrameになっている。
dfex1
| X | Y | |
|---|---|---|
| 0 | 7.980979 | 30.982958 |
| 1 | 9.141469 | 45.919966 |
| 2 | 10.413316 | 13.602186 |
| 3 | 11.733051 | 60.068769 |
| 4 | 8.817145 | 37.297402 |
| 5 | 8.186278 | 17.038228 |
| 6 | 10.054578 | 44.250888 |
| 7 | 11.497520 | 73.037232 |
| 8 | 9.744414 | 51.827517 |
| 9 | 8.325150 | 70.241284 |
DataFrameには分散と共分散を計算するメソッド.cov()が用意されている。
結果をvcovに割り当てよう。
vcov1 = dfex1.cov()
vcov1
| X | Y | |
|---|---|---|
| X | 1.789615 | 10.671705 |
| Y | 10.671705 | 413.166959 |
vcovは分散共分散行列と呼ばれる。
左上と右下の対角線上にあるのは、XとYの不偏分散(\(\sigma_{X}^2\)と\(\sigma_{Y}^2\))である。
一方、右上と左下の値(同じ値となる)が共分散(\(\sigma_{XY}\))である。
相関係数はメソッド.corr()を使って求めることができる。
dfex1.corr()
| X | Y | |
|---|---|---|
| X | 1.000000 | 0.392456 |
| Y | 0.392456 | 1.000000 |
右上と左下の値(同じ値となる)が相関係数(\(\rho_{XY}\))である。
一方、左上の値はXとXの相関係数(\(\rho_{XX}=1\))であり,右下の対角線上にあるのは、YとYの相関係数(\(\rho_{XX}=1\))である。
vcov1を使い相関係数を計算することもできる。
vcov1.loc['X','Y'] / ( vcov1.loc['X','X']**0.5 * vcov1.loc['Y','Y']**0.5 )
0.3924562161216259
時系列のランダム変数#
説明#
マクロ経済学では,時系列データを頻繁に扱うことになる。難しく思う必要はなく,基本的には上で説明した概念を「時系列的」に再解釈するだけで良い。既出のランダム変数\(X_i\)と\(Y_i\),\(i=1,2,3,\cdots,n\)を時系列データとして次のように置き換えてみよう。
\(X_i\;\Rightarrow\;\varepsilon_t,\quad t=0,1,2,3,\cdots\)
\(Y_i\;\Rightarrow\;\varepsilon_{t-1},\quad t=1,2,3,\cdots\)
\(X_i\)の例として,同時に投げた\(n\)個のサイコロの目と考えることができると説明したが,同じ例を使うとすれば,次のようになるだろう。
\(\varepsilon_0\)は第
0期に投げたサイコロの目\(\varepsilon_1\)は第
1期に投げたサイコロの目\(\varepsilon_2\)は第
2期に投げたサイコロの目\(\cdots\cdots\)
同様に\(Y_i\)を考えることができる。違いは,\(\varepsilon_{t-1}\)は1期前の値を表していることだけである。
従って,
第
1期では\(\varepsilon_t\)は第
1期に投げたサイコロの目\(\varepsilon_{t-1}\)は第
0期に投げたサイコロの目
第
2期では\(\varepsilon_t\)は第
2期に投げたサイコロの目\(\varepsilon_{t-1}\)は第
1期に投げたサイコロの目
第
3期では\(\varepsilon_t\)は第
3期に投げたサイコロの目\(\varepsilon_{t-1}\)は第
2期に投げたサイコロの目
\(\cdots\cdots\)
ここで第0期の\(\varepsilon_{t-1}\)の値は存在しないことに注意しよう。
更に,\(\varepsilon_{t-1}\)を次のように一般化しよう。
\(\varepsilon_{t-s},\quad t=s,\;s+1,\;s+2,\;s+3,\;\cdots,\quad s\geq 1\)
一見すると複雑に見えるが,\(s=1\)と置けば\(\varepsilon_{t-1}\)になることが分かる。 \(\varepsilon_{t-s}\)は単純に\(s\)期前の値を表しているに過ぎない。 従って,
第
s期では\(\varepsilon_t\)は第
s期に投げたサイコロの目\(\varepsilon_{t-s}\)は第
0期に投げたサイコロの目
第
s+1期では\(\varepsilon_t\)は第
s+1期に投げたサイコロの目\(\varepsilon_{t-s}\)は第
1期に投げたサイコロの目
第
s+2期では\(\varepsilon_t\)は第
s+2期に投げたサイコロの目\(\varepsilon_{t-s}\)は第
2期に投げたサイコロの目
\(\cdots\cdots\)
ここで第s-1期以前の\(\varepsilon_{t-s}\)の値は存在しないことに注意しよう。
以下では,次のように置き換えて説明するが,分かりづらければs=1として読み進めれば良いだろう。
\(X_i\;\Rightarrow\;\varepsilon_t,\quad t=0,1,2,3,\cdots\)
\(Y_i\;\Rightarrow\;\varepsilon_{t-s},\quad t=s,\;s+1,\;s+2,\;s+3,\;\cdots,\quad s\geq 1\)
まず\(\varepsilon_{t}\)と\(\varepsilon_{t-s}\)の分散を考えてみると,次のように置き換えることができる。
\(X_i\)と\(Y_i\)の分散は,s期ずれているだけの同じランダム変数\(\varepsilon\)の分散に置き換わっている。
解釈
\(\sigma_{\varepsilon_t}^2\):\(\varepsilon\)の
0期からt期までの値に基づく分散\(\sigma_{\varepsilon_{t-s}}^2\):\(\varepsilon\)の
0期からt-s期までの値に基づく分散
\(\varepsilon\)の単位が円であれば,分散である\(\sigma_{\varepsilon_t}^2\)と\(\sigma_{\varepsilon_{t-s}}^2\)の単位は\(\text{円}^2\)となる。
標準偏差は分散の平方根である\(\sigma_{\varepsilon_t}\)と\(\sigma_{\varepsilon_{t-s}}\)になり,単位はそれぞれ円となる。
更に,共分散は次のように置き換える事ができる。
ここで\(\sigma_{\varepsilon_t\varepsilon_{t-s}}\)を自己共分散と呼んでいる。 「過去の自分との共分散」という意味で「自己」が追加されている。
解釈
自己共分散はランダム変数とその
s期前の値との相関の度合を示す指標。\(\varepsilon\)の単位が円であれば,自己共分散\(\sigma_{\varepsilon_t\varepsilon_{t-s}}\)の単位は\(\text{円}^2\)となる。
これらの結果を使うと\(\varepsilon_t\)の相関係数は
で与えられ,一般的には自己相関関数と呼ばれる。「関数」と呼ばれる理由は,\(\rho_{\varepsilon}(s)\)はsの関数として考えることができるためだ。このサイトでは,s=1の場合は自己相関係数と呼ぶ事にする。
次の特徴がある。
分母は必ず正となるので,分子の自己共分散が符号を決定する。
\(\rho_{\varepsilon_t\varepsilon_{t-s}}\)の値は
-1から1の間の値を取り、単位に依存しない。この特徴は、分母に\(\varepsilon_{t}\)と\(\varepsilon_{t-s}\)の標準偏差の積を積を置く事により分母の単位をキャンセルしているためである。
解釈は次のようになる。
\(\rho_{\varepsilon}(s)=0,\;s=1,2,3,\cdots\):何期離れたとしても自己相関はなしという意味である。過去の影響は皆無の状況を指している。
\(\rho_{\varepsilon}(s)>0,\;s=1,2,3,\cdots\):今期と
s期前の値は正の相関があるということを示す。\(\varepsilon_{t-s}\)の値が大きければ(小さければ),\(\varepsilon_{t}\)も大きい(小さい)傾向にあるという意味であり,s期前の影響が強ければ,自己相関係数の絶対値は大きくなる。経済学ではs=1を考える場合が多く,この性質を持続性(persisitence)と呼ぶ。持続性は多くのマクロ変数の重要な特徴となっている。\(\rho_{\varepsilon}(s)<0,\;s=1,2,3,\cdots\):今期と
s期前の値は負の相関があるということを示す。\(\varepsilon_{t-s}\)の値が大きければ(小さければ),\(\varepsilon_{t}\)は小さい(大きい)傾向にあるという意味であり,s期前の影響が強ければ,自己相関係数の絶対値は大きくなる。
.cov(),.corr(),.autocorr()#
自己共分散と自己相関係数の違いを説明したが,DataFrameを使ってどのように計算するかを説明する。dfex2は次のようなDataFrameになっている。
dfex2
| X | X_lag | |
|---|---|---|
| 0 | 11.273065 | NaN |
| 1 | 9.277047 | 11.273065 |
| 2 | 10.066605 | 9.277047 |
| 3 | 9.245792 | 10.066605 |
| 4 | 9.815769 | 9.245792 |
| 5 | 11.120995 | 9.815769 |
| 6 | 11.266016 | 11.120995 |
| 7 | 11.768386 | 11.266016 |
| 8 | 9.893149 | 11.768386 |
| 9 | 10.159764 | 9.893149 |
行ラベルは時間と考えよう。0番目の行が0期を表し,9期までの値が含まれる。
X_lagはXを1期ずらした値となっている。
例えば,1期のX_lagの値は0期のXの値が入っている。
また,-1期はないため,0期のX_lagの値はNaNになっている。
それぞれの列は次のように\(\varepsilon\)に対応している。
X\(\quad\Rightarrow\quad\varepsilon_t\)X_lag\(\quad\Rightarrow\quad\varepsilon_{t-1}\)
dfex2のメソッド.cov()を使って分散共分散行列を表示しよう。
vcov2 = dfex2.cov()
vcov2
| X | X_lag | |
|---|---|---|
| X | 0.807063 | 0.160427 |
| X_lag | 0.160427 | 0.900669 |
左上の値:
Xの分散(\(\sigma_{\varepsilon_t}^2\))右下の値:
X_lagの分散(\(\sigma_{\varepsilon_{t-1}}^2\))右上と左下の値(同じ値):
Xの自己共分散(\(\sigma_{\varepsilon_t\varepsilon_{t-1}}\))
自己相関係数はメソッド.corr()を使って求めることができる。
dfex2.corr()
| X | X_lag | |
|---|---|---|
| X | 1.000000 | 0.189076 |
| X_lag | 0.189076 | 1.000000 |
右上と左下の値(同じ値)が自己相関係数(\(\rho_{\varepsilon_t\varepsilon_{t-1}}\))である。
一方、左上の値はXとXの相関係数(\(\rho_{\varepsilon_t\varepsilon_t}=1\))であり,右下の対角線上にあるのは、X_lagとX_lagの相関係数(\(\rho_{\varepsilon_{t-1}\varepsilon_{t-1}}=1\))である。
Xの列をSeriesと抽出し,メソッド.autocorr()を使って自己相関係数を計算することもできる。
dfex2['X'].autocorr()
0.18907616026671226
メソッド.cov()を使って自己相関係数を計算する場合は,次のようにdfex2から欠損値がある行を削除した後に分散共分散行列を計算する必要がある。
dfex3 = dfex2.dropna() # 欠損値がある行の削除
vcov3 = dfex3.cov()
# 自己相関係数の計算
vcov3.loc['X','X_lag'] / ( vcov3.loc['X','X']**0.5 * vcov3.loc['X_lag','X_lag']**0.5 )
0.18907616026671226
ホワイト・ノイズ#
説明#
時系列のランダム変数\(\varepsilon_t\),\(t=0,1,2,3,\cdots\)を考えよう。例えば,レストランの経営者の収入。ビジネスにはリスク(競争相手の出現やコロナ感染症問題)があるため変動すると考えるのが自然である。\(\varepsilon_t\)は\(t\)毎にある分布から抽出されると考えることができる。次の3つの性質を満たしたランダム変数をホワイト・ノイズ(White Noise)と呼ぶ。
平均は
0:\(\quad\text{E}\left[\varepsilon_t\right]=0\)分散は一定:\(\text{ E}\left[\varepsilon_t^2\right]=\sigma^2\)(\(\sigma^2\)に\(t\)の添字はない)
自己共分散(自己相関)は
0:\(\text{ E}\left[\varepsilon_t \varepsilon_{t-s}\right]=0\)(全ての\(s\ne 0\)に対して)。
<コメント>
平均
0と分散が\(\sigma^2\)のホワイト・ノイズを次のように表記する。\[ \varepsilon_t\sim\textit{WN}(0,\sigma^2) \]ホワイト・ノイズの例:
平均
0,分散\(\sigma^2\)の正規分布から抽出された\(\varepsilon_t\)最小値
10,最大値100からからランダム抽出された\(\varepsilon_t\)
正規分布や一様分布ではない分布でもホワイト・ノイズになる。
ホワイト・ノイズは独立同分布(Independentt and Identically Distributed or iid)の1つである。
ホワイト・ノイズは上記の
3つの性質が満たされれば良いので、毎期の分布が同じである必要はない。ホワイト・ノイズに必要な\(\text{ E}\left[\varepsilon_t \varepsilon_{t-s}\right]=0\)は線形の相関がないことを要求しており、非線形の相関があっても構わない。一方、
iidの「独立」は線形・非線形のいかなる相関もないことを意味している。iidはより制限がより強い概念となる。共分散は
0だが独立ではない例\(X\)は標準正規分布に従うランダム変数とし、\(Y=X^2\)としよう。この場合、\(\text{E}\left[XY\right]=\text{E}\left[X^3\right]=0\)となる(左右対称が理由)。一方で、\(X\)と\(Y\)は明らかに非線形の相関がある。
平均と分散#
以下では実際にランダム変数を発生させ,そのプロットと統計的な特徴について考察する。まず,平均と分散について確認するために,その準備として次のコードを実行しよう。
rng = np.random.default_rng()
rngはランダム変数を生成する「種」となるオブジェクトとして理解すれば良いだろう。
正規分布を生成する構文は次のようになる。
rng.normal(loc=0, scale=1, size=1)
loc:平均(デフォルトは0)
scale:標準偏差(デフォルトは1)
size:ランダム変数の数(デフォルトは1)
ここで、.normal()はrngのメソッドである。例として、平均5,標準偏差2の標準正規分布から10のランダム変数を生成しよう。
rng.normal(5, 2, 10)
array([4.97476513, 4.90159705, 6.13527155, 4.85489379, 2.47316834,
7.67276022, 6.3994357 , 8.03258218, 3.17720194, 5.49651236])
Note
NumPyを使いランダム変数を生成する方法については,「経済学のためのPython入門」のNumpy: ランダム変数を参考にしてください。
では、標準正規分布からのランダム変数をn個抽出しプロットしてみよう。
n = 100
vals = rng.normal(size=n)
dfwn = pd.DataFrame({'WN':vals})
dfwn.plot(marker='.')
pass
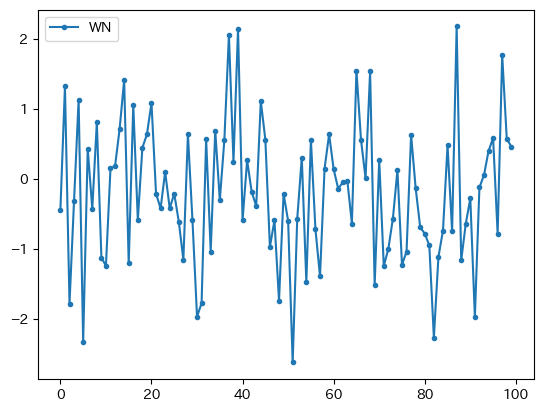
2つの特徴がある。
平均
0:0を中心に周辺を動いている。分散一定:
0から外れても0に戻っている。標準正規分布の場合、-2から2の間の値を取る確率が約95%になる性質からも理解できるだろう。
平均と分散を計算してみよう。
dfwn['WN'].mean(), dfwn['WN'].var()
(-0.1897443187071782, 1.000902208791908)
標準正規分布の母集団からのサンプル統計量であるため誤差が発生していることがわかる。
2つの特徴をを確認するためにPandasのplot()を使ってヒストグラムを描いてみよう。
dfwn.plot.hist(bins=30)
pass
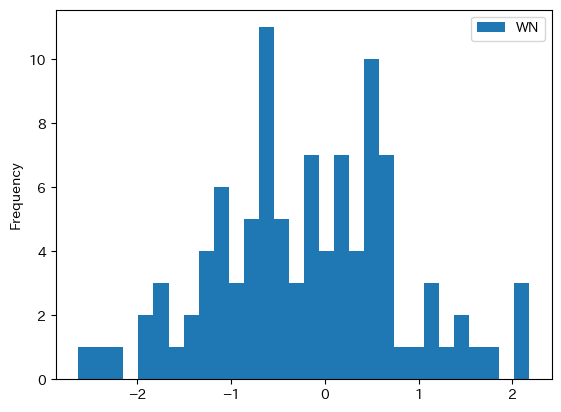
概ね0を中心に左右対象に動いている。即ち,平均0を反映している。また,0から離れている観測値が少ないことが分かる。これは0方向に戻ることを示しており,分散が一定となるためである。この性質はnを500や1000などの大きな数字に設定するより一層分かりやすいだろう。
自己共分散#
1期違いの自己共分散\(\sigma_{\varepsilon_t \varepsilon_{t-1}}\)を計算するために,dfwnの列WNを1期シフトさせた新たな列WNlagを作成しよう。
dfwn['WNlag'] = dfwn['WN'].shift()
dfwn.head()
| WN | WNlag | |
|---|---|---|
| 0 | -0.445298 | NaN |
| 1 | 1.320893 | -0.445298 |
| 2 | -1.785157 | 1.320893 |
| 3 | -0.310499 | -1.785157 |
| 4 | 1.126024 | -0.310499 |
WNlagの値はWNの値が1期シフトしていることが分かる。
0番目の行のWNが初期値であり、同じ値が1番目の行のWNlagに入っている。
即ち、1番目の行を見るとWNには1期の値、、WNlagには初期(0期)の値がある。
同様に、各行のWNにはt期の値、WNにt-1期の値が入っている。
この2つの列を使って散布図を描いてみる。Pandasのplot()で横軸・縦軸を指定し,引数kindで散布図を指定するだけである。
dfwn.plot.scatter(x='WNlag', y='WN')
pass
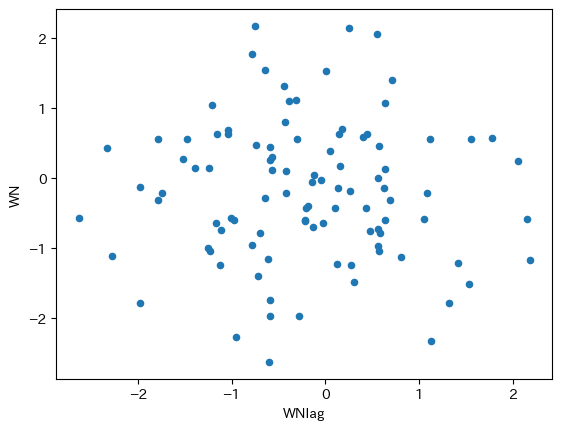
自己共分散がゼロであれば,ランダムに散らばっているはずであり,何らかのパターンも確認できないはずである。
ここで異なるプロットの方法を紹介する。Pandasのサブパッケージplottingにあるlag_plot()関数を使うと共分散の強さを示す図を簡単に作成することが可能となる。
必須の引数:1つの列
オプションの引数:
lagは時間ラグ(デフォルトは1)
pd.plotting.lag_plot(dfwn['WN'])
pass
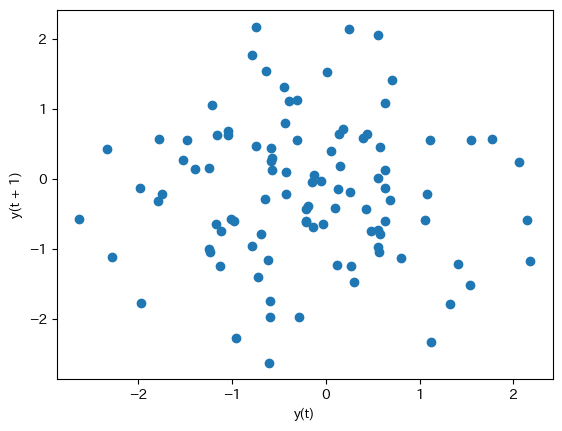
横軸:
t期の値縦軸:
t+1期の値
2つの図は同じであることが確認できる。
分散・自己共分散を計算してみよう。
dfwn.cov()
| WN | WNlag | |
|---|---|---|
| WN | 1.000902 | -0.032568 |
| WNlag | -0.032568 | 1.006786 |
左上と右下の対角線上にあるのは、WNとWNlagの不偏分散であり、1に近い値となっている。両変数は標準正規分布(分散1)から生成したためであり、1にならないのはサンプルの誤差である。(WNとWNlagの不偏分散は異なるが、その理由は?)一方、右上と左下の値(同じ値となる)が自己共分散であり、非常に小さな値であるが、自己共分散は0という仮定を反映している。
自己相関係数#
メソッド.corr()を自己相関係数を計算しよう。
dfwn.corr()
| WN | WNlag | |
|---|---|---|
| WN | 1.000000 | -0.032289 |
| WNlag | -0.032289 | 1.000000 |
右上もしくは左下にある値が自己相関係数になる。
もしちろん、列WNを抽出し,メソッドautocorr()を使って自己相関係数を計算することも可能である。
dfwn['WN'].autocorr()
-0.032289440092769295
また,dfwn.cov()を使って自己相関係数を計算することができるが、上でも説明した点に注意する必要がある。dfwnの0行目には欠損値があるため、自己共分散を計算する際にその行は使われていない。同様に、自己相関係数を計算する際は欠損値がある行を使わずに計算する必要がある。この点に注意して、次のコードで計算することができる。
vcov = dfwn.dropna().cov()
vcov.iloc[0,1] / ( vcov.iloc[0,0]**0.5 * vcov.iloc[1,1]**0.5 )
-0.032289440092769295
自己回帰モデル:AR(1)#
GDPや構成要素を含め、マクロ変数の重要な特徴は持続性(正の自己相関係数)である。 この点については次章で確認するが,その基本となる統計的モデルである自己回帰モデルを考察し、それを出発点として景気循環の議論を進めていく事にする。
説明#
ここでは持続性を捉える確率過程である自己回帰モデルを考える。英語でAugoregressive Modelと呼ばれ,AR(1)と表記され,次式で表される。(AR(1)の(1)は右辺と左辺の変数は1期しか違わないことを表している。)
ここで
\(y_t\):\(t\)期の\(y\)の値
\(-1<\rho<1\)
\(\varepsilon_t\sim WN(0,\sigma^2)\)(ホワイト・ノイズ)
次の特徴がある。第一に、\(\varepsilon_t\)を所与とすると\(y_t\)の差分方程式となっている。\(-1<\rho<1\)となっているため,安定的な過程であることがわかる。即ち,\(\varepsilon_t=0\)であれば、\(y_t\)は定常状態である\(0\)に近づいて行くことになる。しかしホワイト・ノイズである\(\varepsilon_t\)により、毎期確率的なショックが発生し\(y_t\)を定常状態から乖離させることになる。第二に、今期の値\(y_t\)は前期の値\(y_{t-1}\)に依存しており,その依存度はパラメータ\(\rho\)によって決定される。この\(\rho\)こそが\(y_t\)の持続性の強さを決定することになり,自己回帰モデル(99)の自己相関係数は\(\rho\)と等しくなる。即ち、持続性を捉えるためには、\(\rho\ne 0\)が必須である。
ここで考えるAR(1)の特徴をまとめておこう。
\(y_t\)の確率分布が変化しない定常過程
平均は一定:\(\quad\text{E}\left[y_t\right]=0\)
分散は一定:\(\text{E}\left[y_t^2\right]=\dfrac{\sigma^2}{1-\rho^2}\)(\(t\)の添字はない)
自己共分散は一定:\(\text{E}\left[y_t y_{t-s}\right]=\sigma_{y_t y_{t-s}}^2=\rho^s\dfrac{\sigma^2}{1-\rho^2}\)(\(s\ne 0\))。従って,
\[ \text{自己相関関数}(s)=\frac{\sigma_{y_t y_{t-s}}^2} {\sigma_{y_t}\times\sigma_{y_{t-s}}} =\rho^s \]であり,\(s=1\)の自己相関係数は\(\rho\)となる。
3つの例:持続性の違い#
直観的にマクロ変数の特徴である持続性とは,前期の値が今期の値にどれだけ影響を持っているかを示す。\(\rho\)の値を変えて持続性の違いを視覚的に確認するための関数を作成しよう。
def ar1_model(rho, y0=0, T=100):
"""引数:
rho: AR(1)の持続性を捉えるパラメータ
y0: 初期値
T: シミュレーションの回数(デフォルト:0)
戻り値:
matplotlibの図を示す
自己相関係数の値を表示する"""
y = y0 #1
y_lst = [y] #2
for t in range(1,T): #3
e = rng.normal() #4
y = rho*y + e #5
y_lst.append(y) #6
df_ar1 = pd.Series(y_lst) #7
ac = df_ar1.autocorr() #8
ax_ = df_ar1.plot(marker='.') #9
ax_.set_title(fr'$\rho$={rho} 自己相関係数:{ac:.3f}',size=20) #10
ax_.axhline(0, c='red') #11
コードの説明
#1:forループで使うアップデート用のyであり,初期値を割り当てている。#2:yの値を格納するリスト。初期値を入れてある。#3:T期間のforループの開始。変数tは(4)と(5)に入っていないので単にループの回数を数えている。range(1,T)の1はループの計算が\(t=1\)期のyの計算から始まるため。\(t=0\)期のyは(1)で与えられている。
#4:t期のホワイト・ノイズの生成。#5:右辺のeはt期のホワイトノイズであり,y前期のyとなっている。#6:y_listにyを追加。#7:y_listを使ってSeriesを作成しdf_ar1に割り当てる。#8:.autocorr()を使い己相関係数を計算しacに割り当てる。#9:yのプロットmarker='.'はデータのマーカーを点に設定。図の「軸」を
ax_に割り当てる。
#10:図のタイトルの設定frのfはf-stringを表し,{rho}と{ac:.3f}に数値を代入する。:.3fは小数点第三位までの表示を設定frのrは$\rho$をギリシャ文字に変換するためののも。$\rho$はLaTeXのコード。
#11:.axhline()は横線をひくメソッド。
ar1_model(0.1)
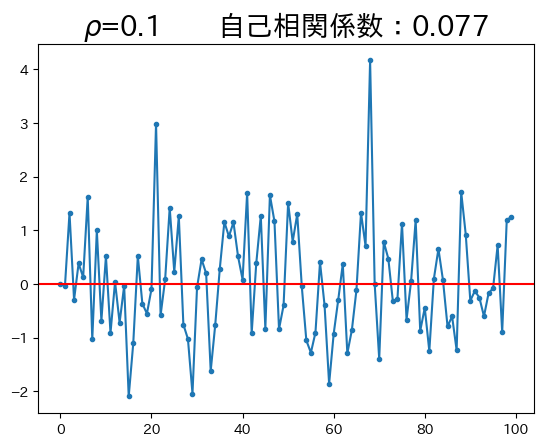
この例では\(\rho\)の値が低いため,\(y\)は定常状態の0に直ぐに戻ろうとする力が強い。従って、前期の値の今期の値に対する影響力が小さいため、持続性が低い。
ar1_model(0.5)
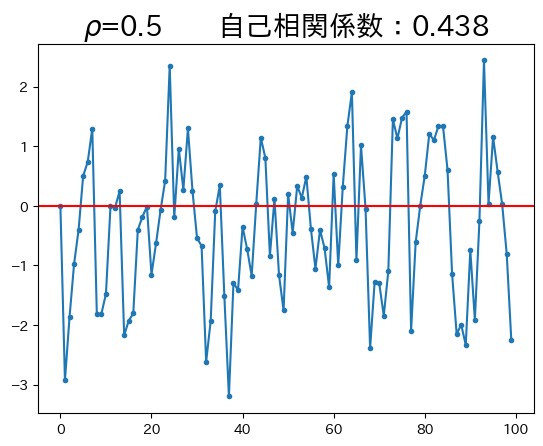
\(\rho\)の値が高くなると、定常状態の\(0\)に戻ろうとする作用が弱くなり、持続性が強くなることがわかる。
ar1_model(0.9)
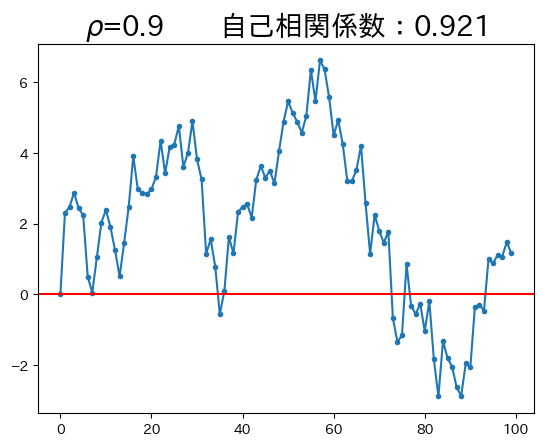
\(\rho\)が非常に高いため、持続性も非常に強くなっている。即ち、今期の値は前期の値に対する依存度が大きい。